Automating Algorithm Discovery: A Case Study in Transaction Scheduling
💡
This post is part of our AI-Driven Research for Systems (ADRS) case study series, where we use AI to automatically discover better algorithms for real-world systems problems.
In this blog, we revisit a recent research problem from our VLDB '24 paper, Towards Optimal Transaction Scheduling, which minimizes contention for database transactional workloads. We show how we leverage an ADRS framework to discover an algorithm with 34% faster schedules. This case study shows how AI can be used to develop solutions for different problem settings that would otherwise require manual redesign.
- ✍️ Previous Blogs: https://ucbskyadrs.github.io/
- 📝 Paper: https://arxiv.org/abs/2510.06189
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb
The Problem: Transactional Conflicts are Expensive
Transactions are a cornerstone of modern data stores, offering guarantees that simplify development under concurrent data access for modern applications. Their wide adoption by industry databases highlights their importance. However, modern applications pose new hurdles for supporting these semantics. Driven by massive data growth and new use cases such as AI agents, storage systems face unprecedented data volume and scale. This trend has given rise to large-scale, multi-tenant systems, such as Meta's User Database (UDB), which serves applications like Facebook, Instagram, and Meta AI. For these platforms, the central challenge is to deliver high performance without compromising the strict transactional guarantees on which applications depend.
In these shared environments, the primary performance bottleneck for transactions is often data contention. When different applications access shared data at the same time, their requests conflict, causing system-wide delays. Contention doesn't just hurt performance, leading to lost revenue and production outages; it also causes massive resource inefficiencies. This is because delayed requests hold onto system resources without making progress. However, weakening transactional semantics is also not ideal because it can lead to data corruption and safety violations.
Transaction Scheduling to Prevent Conflicts
In our VLDB '24 paper, we propose using a scheduling-based approach to handle contention: instead of resolving conflicts after they occur, we can prevent conflicts in the first place by intelligently reordering transactions. Traditionally, databases rely on concurrency control protocols to manage contention. However, these protocols share a fundamental limitation: they handle conflicts only after they have occurred, missing significant opportunities to improve performance by avoiding them altogether.
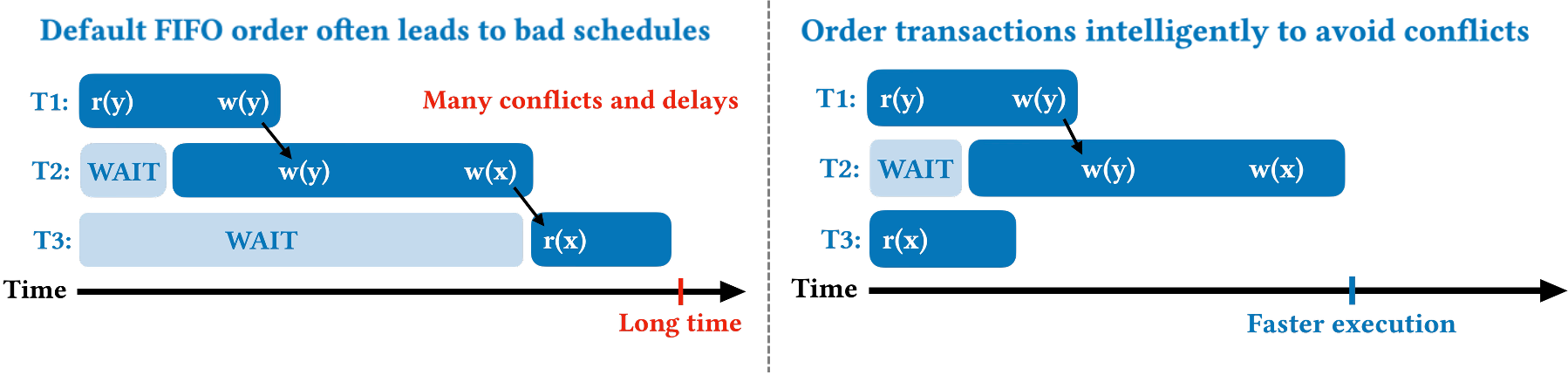
Instead of resolving conflicts, this work focuses on preventing them through intelligent scheduling. By reordering how transactions are executed, we can dramatically reduce the likelihood of conflicts. However, scheduling transactions is uniquely challenging. Unlike scheduling in networking or operating systems, transaction interactions are complex and depend on the data they access, which isn't fully known beforehand. Furthermore, databases must uphold strict ACID guarantees, adding far more constraints. This complexity is why most databases default to a simple first-in, first-out (FIFO) approach, which often results in suboptimal, high-conflict execution orders. Figure 1 illustrates how scheduling can improve performance.
Online vs. Offline Scheduling
There are two main settings for transaction scheduling: online and offline.
Online scheduling happens in real-time, as transactions arrive. The scheduler must make decisions almost instantly and with incomplete information, as the full details of a transaction's operations are not known ahead of time. Once a transaction is scheduled and committed, the decision is final. This setting is standard for most databases today (e.g., MySQL, Postgres, Spanner, etc.)
Offline scheduling relaxes many of these constraints as it assumes we know in advance the set of transactions we need to schedule. This models deterministic databases that can process transactions in batches. Here, the scheduler can analyze an entire group of transactions (and all their operations) at once, allowing for more computationally intensive algorithms to find better execution orders.
The SOTA Algorithm: Shortest Makespan First (SMF)
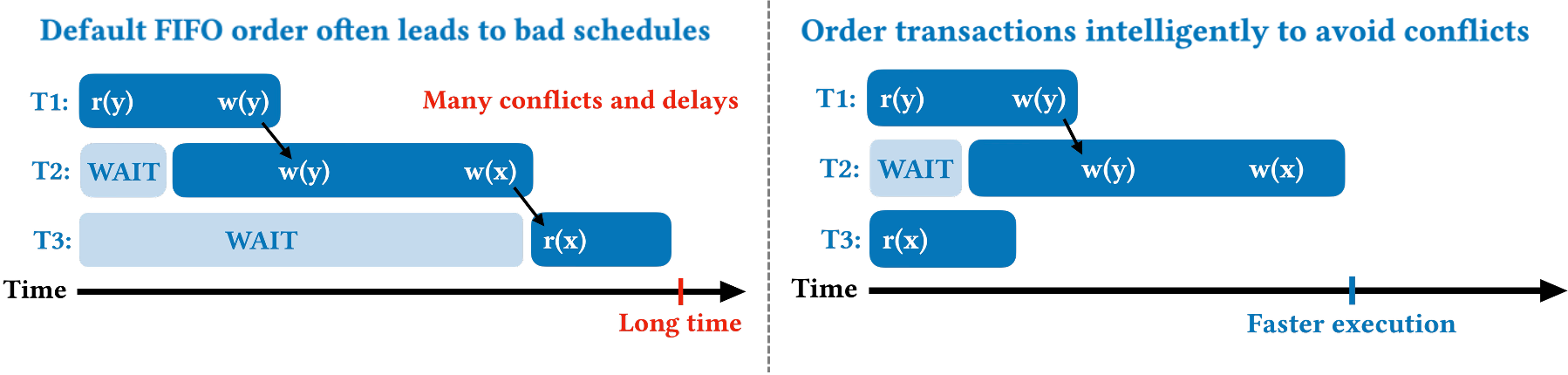
To tackle the problem of transaction scheduling, the VLDB paper first defines the goal of transaction scheduling: minimize the schedule makespan, i.e., the total time needed to execute a given batch of transactions. Finding the optimal schedule is known to be NP-Hard, so the paper introduces Shortest Makespan First (SMF), which finds fast schedules using heuristics. SMF works by greedily constructing a schedule. Starting with a single transaction, SMF samples a small number of unscheduled transactions and appends the one that causes the smallest increase in the total makespan. The core idea is to estimate the cost of potential conflicts and place transactions that are likely to conflict far apart from each other. This greedy approach has a low runtime overhead (linear with respect to the number of transactions that need to be scheduled) and is highly effective at finding low-conflict schedules in real-time. Figure 2 provides an example of how SMF is able to find the high-performing schedule for the previous workload.
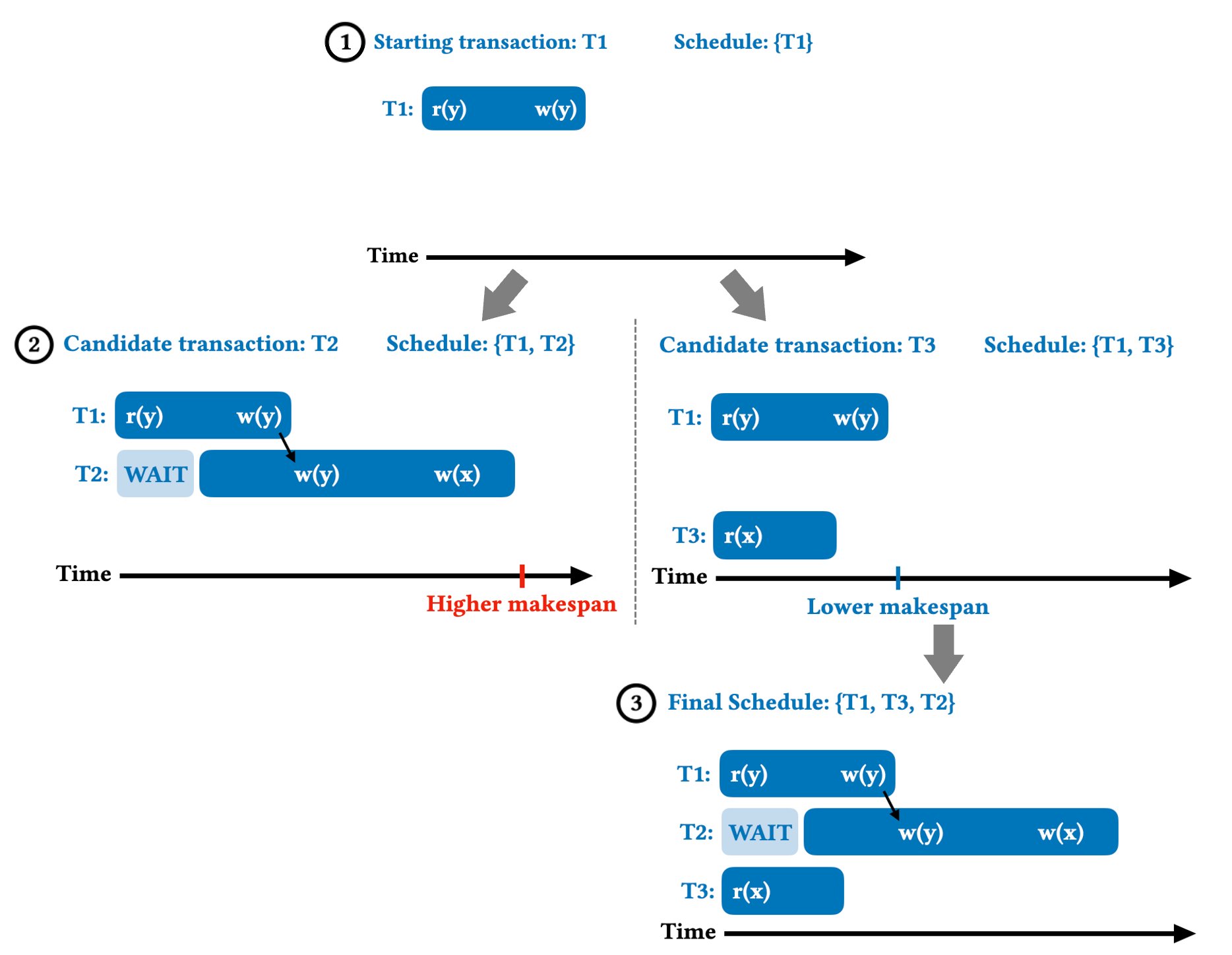
SMF is designed for the online setting in which the order transactions arrive and their full read-write sets are unknown. It is the SOTA in the online setting and also performs well in the offline setting, as we show in the VLDB paper.
The Challenge of Online Scheduling: Rediscovering the State-of-the-Art
Given the success of SMF, a natural question is whether an even better algorithm exists for the online setting. We tasked OpenEvolve, an open-source ADRS framework, with this exact challenge: starting from a simple random baseline, can it discover a policy that outperforms SMF? We use the existing simulator from the VLDB paper to model transactional execution and evaluate candidate solutions based on their average schedule makespan across standard OLTP benchmarks. The optimization objective is to find a schedule that minimizes makespan, thereby maximizing throughput.
After a thorough search, the best policy OpenEvolve discovered was, in fact, SMF itself. It is likely that this is a case of contamination, i.e., the model was trained on the SMF paper. While not a novel discovery, this result shows these frameworks can reproduce state-of-the-art solutions. Furthermore, it underscores the difficulty of the online transaction scheduling problem.
The online setting imposes strict constraints: decisions must be made in linear time, without full knowledge of a transaction's read-write sets. We show in our VLDB paper that more complex heuristics often fail to outperform SMF's conflict-aware, greedy approach. By leveraging the cost of conflicts, SMF provides a generalizable solution that works across different workloads.
Discovering a Better Algorithm for Offline Scheduling
We also apply OpenEvolve to automatically search for a better algorithm for the offline transaction scheduling problem. We use the same simulator as before but relax the constraints on algorithm runtime and reordering transactions.
We run OpenEvolve for 100 iterations, which takes less than two hours and costs under $20. We use a three-island setup with an ensemble of 80% Gemini 2.5 Pro and 20% OpenAI o3 models. We use SMF as our starting program for evolution.

OpenEvolve discovers a new algorithm for the offline setting that reduces makespan by 34% compared to SMF. Since this is not a previously known solution, it demonstrates the framework's ability to discover genuinely new algorithms. OpenEvolve introduces three key innovations that drive its performance improvements:
- Smart initialization: It first computes simple features for each transaction (e.g., number of writes, length) and builds a strong initial sequence by sorting them. This simple heuristic tends to reduce conflicts from the start.
- Exhaustive greedy construction: It then runs an exhaustive greedy algorithm where each remaining transaction is tried in every possible position in the schedule.
- Local refinement: Finally, it performs pair-swap hill climbing to escape any local minima and adds a few random schedules as a safety net for diversification.
This new design extends the greedy intuition of SMF but leverages the offline context to perform a more thorough search, leading to significantly better schedules.
Evolution
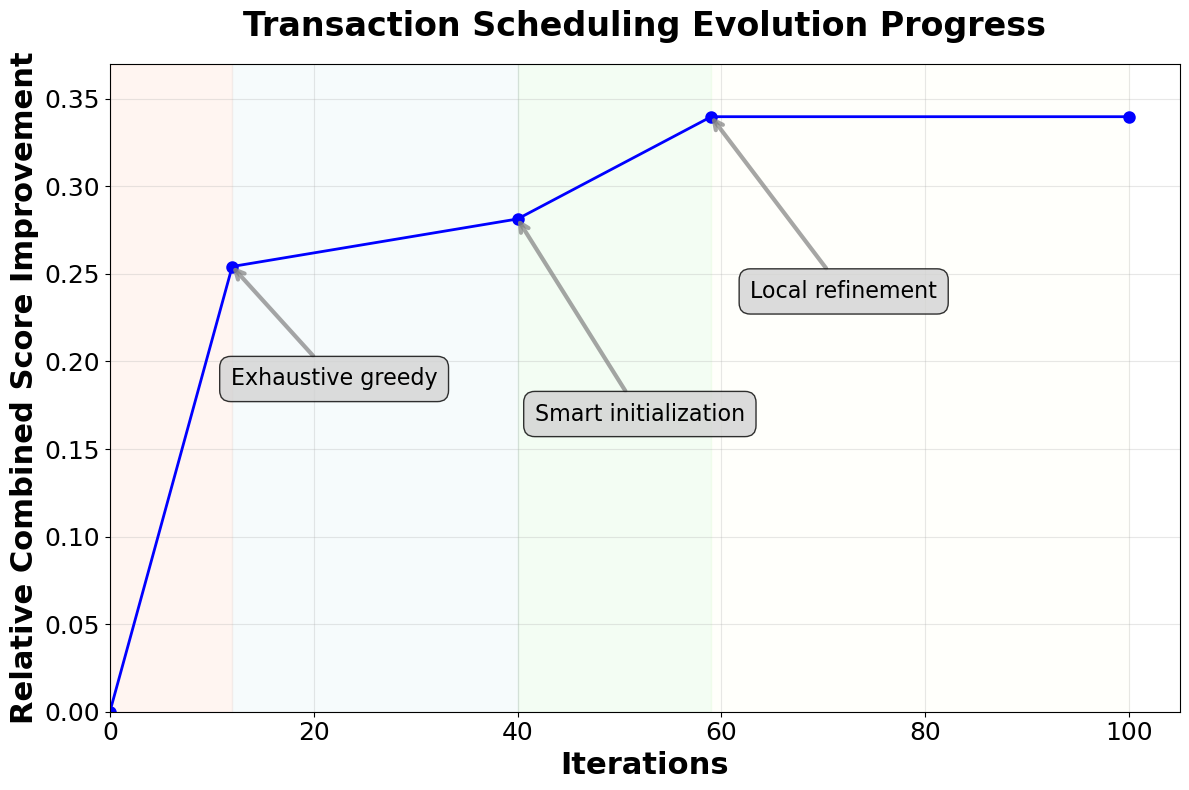
The evolution process for the offline setting began with exploring simple heuristics like sorting by transaction length or write count. The search eventually centered on two main directions: (i) greedily appending transactions to minimize makespan at each step but considering every possible position, and (ii) using metaheuristics like simulated annealing and neighborhood swaps to broaden the search.
An early challenge was that simple hill-climbing techniques often got stuck in local minima when starting from random schedules. The breakthrough came when the framework learned to combine a strong, heuristic-based starting point with an exhaustive greedy construction method. The reasoning models showed a sophisticated understanding of how to escape local minima by using problem-specific signals (like key frequency) and considering larger neighborhoods (e.g., inserting a transaction into every possible position). The final, best-performing solution combined the most successful techniques that emerged: a cheap but effective heuristic start, a powerful greedy construction phase, and a lightweight local search to refine the result.
Discussion
This case study tackles a fundamental and long-standing research problem in database systems: transaction contention. Starting with a state-of-the-art online algorithm, OpenEvolve automatically discovered a novel policy for the offline setting, reducing makespan by 34%. The result highlights a key benefit of AI-driven research: it can assist researchers in developing solutions for different problem settings that would otherwise require manual redesign. In practice, this broadens the range of problems that researchers can tackle and increases the speed at which they can address them.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t and Discord