Automating Algorithm Discovery: A Case Study in Spot Instance Scheduling
This post is the second in our AI-Driven Research Systems (ADRS) series, where we apply AI to optimize complex system problems. Here, we tackle spot instance scheduling, a classic cost-versus-reliability problem in the cloud. Specifically, we demonstrate how OpenEvolve discovers novel algorithms that surpass the algorithm from an NSDI'24 Best Paper, achieving up to 16% and 48% cost savings in a single and multi-region setups on our final evaluation traces, respectively.
- 🕸️ ADRS Blog Series: https://ucbskyadrs.github.io/
- 📝 Paper: https://arxiv.org/abs/2510.06189
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb
The Problem: Cost vs. Reliability in the Cloud
AI compute costs have become a significant bottleneck for innovation (as a16z recently points out). Compounding this challenge, many applications have strict deadlines for which missing them means lost revenue and degraded performance. Examples include recommendation systems processing user data or trading applications analyzing market information.
Cloud providers offer spot instances at 60-90% discounts to reduce costs, but these can be preempted at any moment, making it difficult to guarantee completion for deadline-sensitive workloads. This creates a critical challenge: how to minimize costs while ensuring jobs finish on time?
The NSDI '24 best paper Can't Be Late tackled this problem by introducing a state-of-the-art spot instance scheduling algorithm for a single region. We use OpenEvolve to improve upon it and further extend the approach to multi-region scheduling.
The Challenge in Practice
Consider a typical scenario: running a large-scale data analysis that needs 40 hours of computation and must complete within 60 hours before a conference submission deadline. With this 20-hour buffer, the scheduler can choose between:
- Spot instances: ~$25/hour, cheap but unreliable (can be preempted anytime)
- On-demand instances: ~$98/hour, expensive but guaranteed
- Cold start delay: every time you switch instances, you lose 20 minutes to cold-start overhead
The scheduler continuously monitors the system and makes decisions whenever the state changes - when a spot instance becomes available or unavailable, or when the current instance gets preempted.
At each moment, the scheduler must pick one of three actions: (1) Wait - No instance running, no cost, no progress, (2) Spot - Run on cheap instances but that may be preempted at any time, or (3) On-Demand - Run on an expensive but guaranteed instance.
The simplest policy, Always On-Demand, runs the job entirely on on-demand instances and ignores all spot opportunities. It guarantees completion but at maximum cost (~$4k for a two-day run), since it never uses cheaper spot capacity.
A better policy is the Greedy Policy (a baseline from the original NSDI paper) which uses spot instances whenever available, until it cannot risk another cold start delay and has to fall back to on-demand instances. But once the fallback happens, it can never go back to spot instances, even if these cheaper instances become available later on.
These limitations motivate the Can't Be Late paper to design a more adaptive scheduling algorithm.
The SOTA Policy: Uniform Progress
.png)
Figure 1. Uniform Progress Algorithm. Upper: instance usage over time; Lower: progress curve showing target line (pink) vs actual progress (green). The algorithm tracks a target progress line and switches to on-demand whenever actual progress falls behind, even if cheaper spots would become available shortly.
The Uniform Progress algorithm proposed in the NSDI'24 paper follows a simple idea: use on-demand instances early and stay close to the target progress line (illustrated in Figure 1), which represents the ideal steady progress rate, ensuring sufficient slack time to fall back to on-demand instances.
The core algorithm logic is as follows:
- Calculate target progress line:
job_duration / deadline_time - Track actual vs. target progress at each time step
- If behind schedule: use any available resources (spot or on-demand) to catch up
- If ahead of schedule: wait for spot or use if available
- Maintain hysteresis: staying on the on-demand instance for a minimum period to prevent oscillation between instances.
While Uniform Progress is effective, it follows a relatively simple, fixed approach: track a progress line and react when falling behind. This raises the question of whether a more adaptive strategy, one that learns from recent spot market patterns and makes smarter decisions about when to wait versus when to act, could achieve better cost savings.
Discovering a Novel Single-Region Scheduling Policy with OpenEvolve
To test whether an ADRS can discover a better-performing solution, we apply OpenEvolve to this problem, using the greedy policy mentioned above as the starting program (we also tried starting from Uniform Progress; see observations below). We evolve the policy over 400 iterations, which takes 5 hours and costs under $20, using a model ensemble of 80% Gemini 2.5 Pro and 20% GPT-4o. We use only ~30% of the total evaluation traces during evolution, to prevent overfitting. For evaluation, we measure the final algorithm using traces from the original paper that span different deadlines, cold start delays, regions, and GPU types.
The Evolution Result
The final evolved policy achieves on average 7% and up to 16.7% cost savings over the SOTA Uniform Progress policy while maintaining deadline guarantees. We compare between Uniform Progress policy and the final evolved algorithm below.

The evolved algorithm shows three main innovations that address Uniform Progress's limitations (shown in Figure 2):
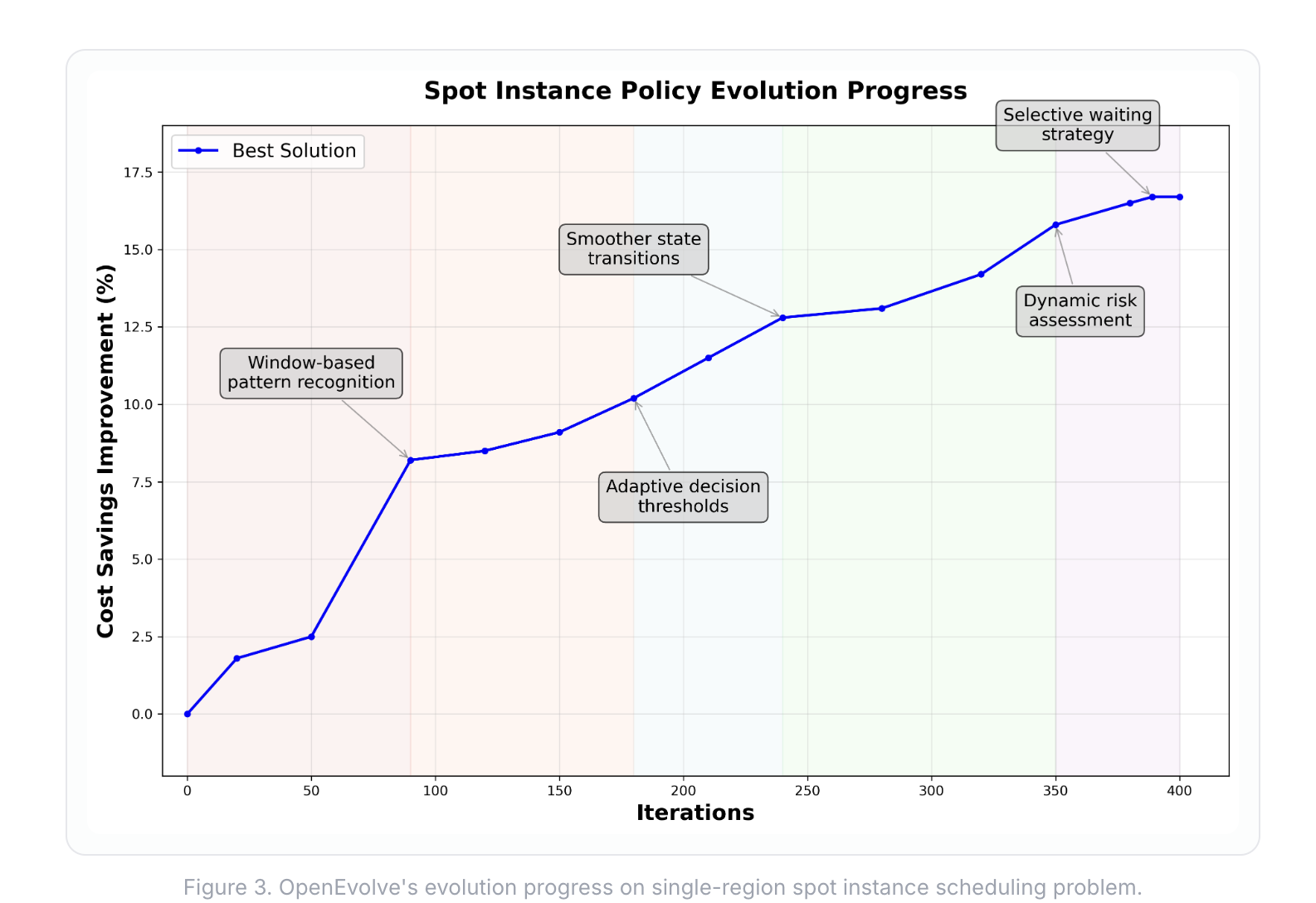
1. Window-based Pattern Recognition: Uses a sliding window to track recent spot availability and adjusts strategy based on whether spots have been stable or frequently preempted. This moves beyond Uniform Progress's simple fixed approach of just tracking a progress line.
2. Adaptive Decision Thresholds: Adjusts decision-making thresholds based on recent spot market conditions, rather than using Uniform Progress's fixed criteria for when to switch between resources. This enables more nuanced timing decisions.
3. Selective Waiting Strategy: Can choose to wait for more stable spots rather than immediately using every available instance. This solves Uniform Progress's key limitation of being overly reactive, grabbing every available spot when behind schedule, even extremely short-lived ones that don't provide enough progress to justify their cold start delays.
Evolution Process
Over 400 iterations, OpenEvolve gradually refined when to use spot instances (Figure 3.). Early generations learned window-based pattern recognition, tracking recent spot availability to distinguish between periods when spots were plentiful versus scarce. As evolution progressed, the policy developed adaptive decision thresholds that adjust based on how volatile the spot market has been recently.
Midway through, OpenEvolve learned to create smoother transitions between different behaviors and avoid unnecessary oscillation. In later iterations, it introduced dynamic risk assessment, adjusting how conservative to be based on recent preemption patterns. The final breakthrough was the selective waiting strategy: instead of grabbing every available spot, the algorithm learned to skip unreliable ones and wait for better opportunities.
Discovering a Novel Multi-Region Scheduling Policy with OpenEvolve
While the previous solution already saves up to 16.7% over state-of-the-art, we discovered a fundamental limitation during our experiments. Even with selective waiting, single-region scheduling hits a ceiling. The problem isn't just avoiding bad spot instances, it's that there simply aren't enough good spot instances throughout the whole job in one region.
This realization led us to explore scheduling jobs over multiple regions. Cloud providers offer instances across geographic locations (cloud regions) with independent spot markets. As a result, the optimization space expands dramatically: not just when to use spot vs. on-demand, but which region to run and when to migrate between regions.
Challenges in Multi-Region Setup
Beyond single-region decisions, the scheduler must now handle:
- Regional price variations: Spot prices differ by up to 30% across regions
- Migration costs: Moving jobs between regions incurs data transfer fees (egress fees) and setup time in the new region
- Availability correlation: Spot availability patterns are independent across regions
As no published algorithm exists for this setting, we apply OpenEvolve to explore this expanded search space.
We extend the single-region simulator to model multiple regions with realistic price variations and migration costs. We run the search for 100 iterations using Gemini 2.5 Pro, starting from a baseline that applies Uniform Progress locally and moves to other regions in a round-robin fashion when the local region does not have available spot at the time.
Evolution Results

In our final evaluation across all traces, the final evolved policy achieves on average 27% and up to 48% cost savings over the round-robin Uniform Progress baseline, while still preserving deadline guarantees.
The final policy follows an intuitive rule:
- When there is slack, explore cheaper regions and spot markets.
- When the deadline tightens, switch to guaranteed progress using on-demand instances.
This adaptive balance lets the system opportunistically chase low-cost capacity without risking missed deadlines, effectively navigating the multi-region trade-off between exploration and deadline pressure.
Evolution Process
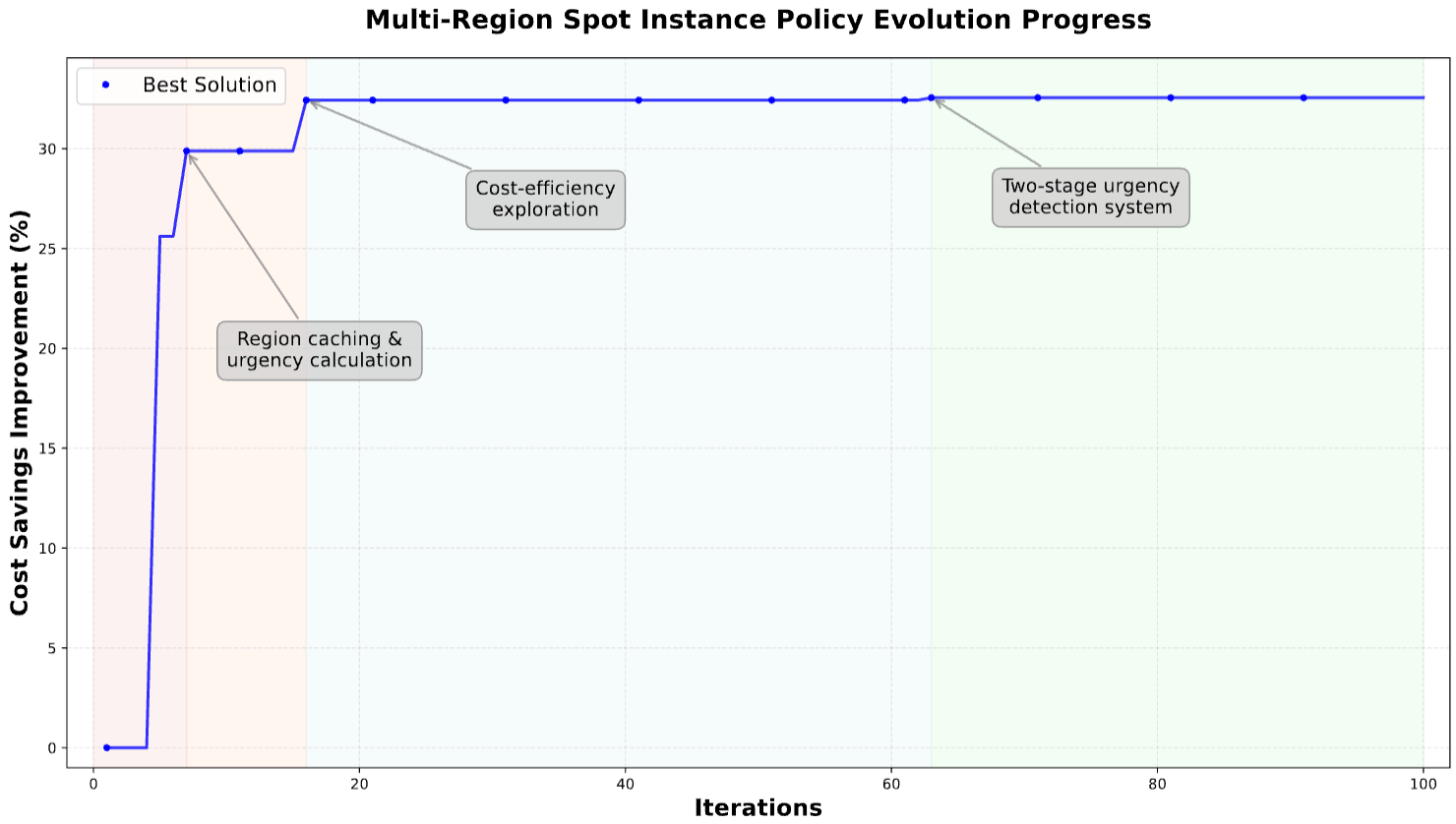
The evolution unfolded through a few key breakthroughs (shown in Figure 5.):
- Early iterations (~7): OpenEvolve introduces region caching and urgency calculation, helping it remember where stable spots had appeared before.
- Mid-stage (~20): experiments in cost-efficiency exploration refine how aggressively to chase savings without missing deadlines.
- Final stage (~63): OpenEvolve discovers a two-stage urgency detection system, separating progress tracking from deadline pressure. This allows it to act decisively when needed but explore freely otherwise.
The final design shows that in dynamic, volatile spot markets, knowing when to wait can be just as powerful as knowing when to act.
Observations
We now share a few key observations from our experiments.
💡 Less is More: Weaker Baselines Can Lead to Better Discoveries
Interestingly, evolution only made progress when initialized from the greedy policy. When we tried starting from the more advanced Uniform Progress baseline, nothing improved for dozens of rounds. Sometimes, a weaker starting point opens up more room for creativity by letting evolution find entirely new directions instead of getting stuck polishing what has already been optimized. One hypothesis is that SOTA represents a local minimum and it is harder for the evolution process to escape from such local minima.
💡 Prevent Overfitting
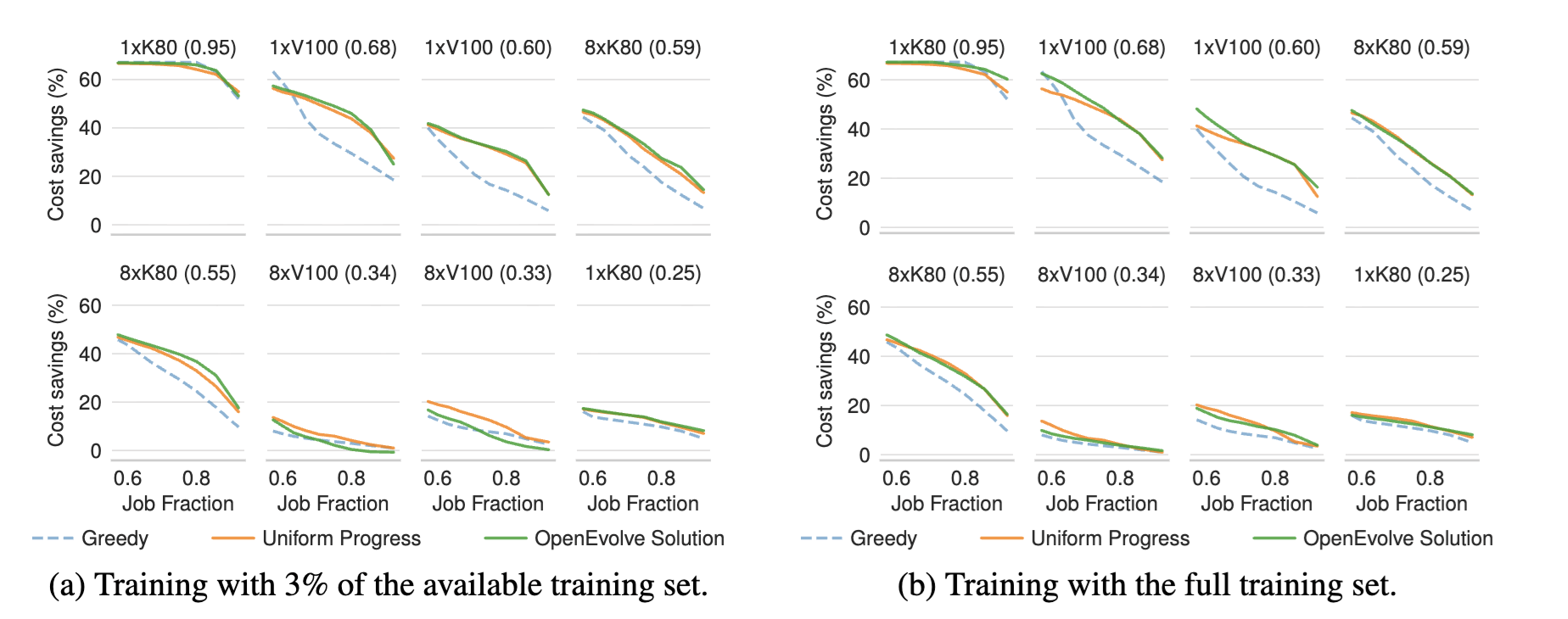
When tested on a subset of workloads, they pick up workload-specific patterns instead of real strategies. In this case, we found that testing on just one spot pattern caused the evolved policy to fail on other workloads (shown in Figure 6). The fix is simple: use broader, more varied test sets so evolution learns to generalize, not memorize.
Discussion
This problem is not a toy example: it is a complex, research-level scheduling challenge previously tackled by an NSDI'24 Best Paper. Our evaluation setup mirrors what was used in that paper, making this an apples-to-apples comparison. Yet, ADRS independently surpasses the state-of-the-art and uncovers new ideas like selective waiting and adaptive multi-region migration that cut costs by up to 48%. And all for just under $20 of compute!
These results highlight how ADRS can take on problems of genuine research complexity and autonomously produce novel, interpretable algorithms in hours; this is work that would otherwise take human researchers weeks or months. Try it out yourself: see what your system can evolve next!
Contact
Contact
- zhifei.li@berkeley.edu
- tianxia@berkeley.edu
- lshu@berkeley.edu
- accheng@berkeley.edu
- melissapan@berkeley.edu
if you have any questions about this blog!