Automating Algorithm Discovery: A Case Study in Scheduler Design for Multi-LLM Serving Systems
This post is part of our AI-Driven Research for Systems (ADRS) case study series, where we use AI to automatically discover better algorithms for real-world systems problems.
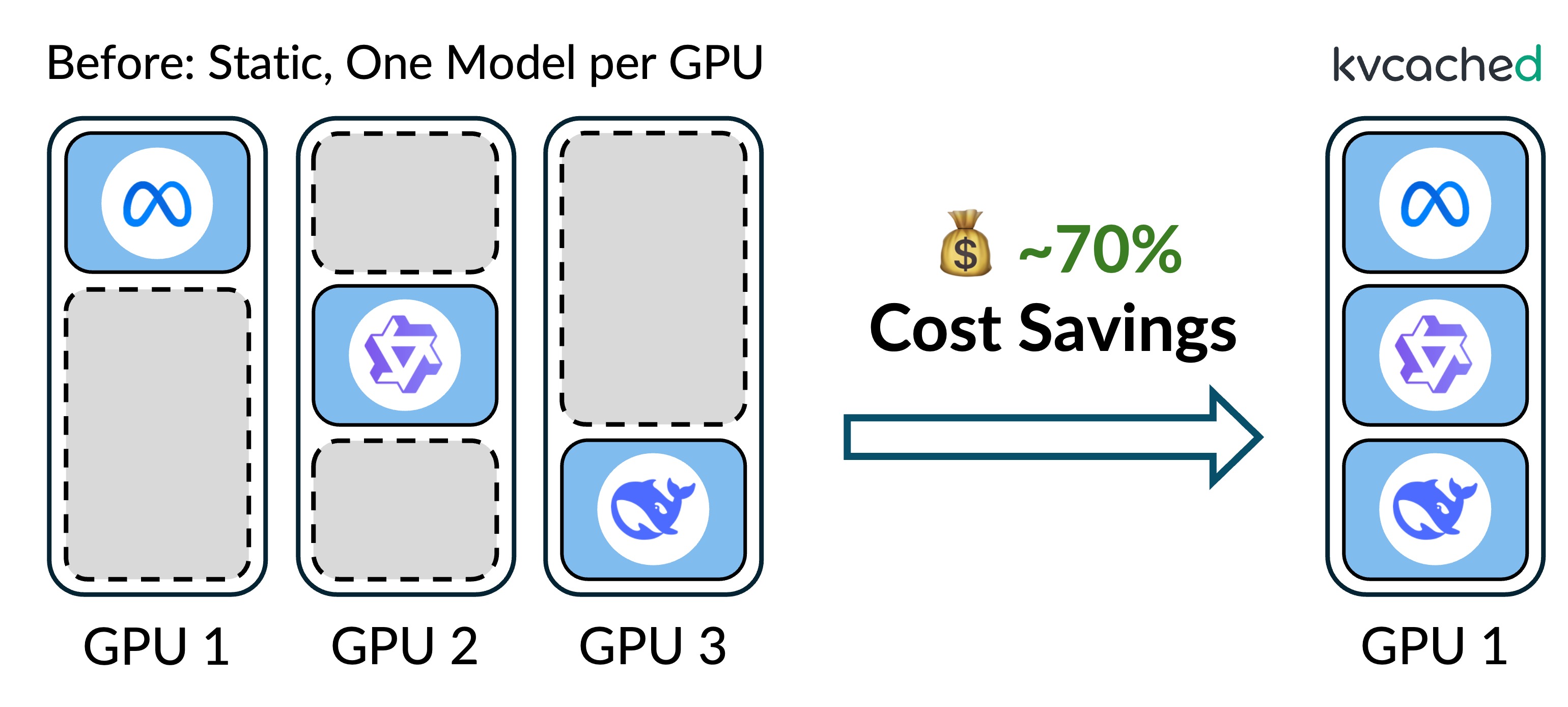
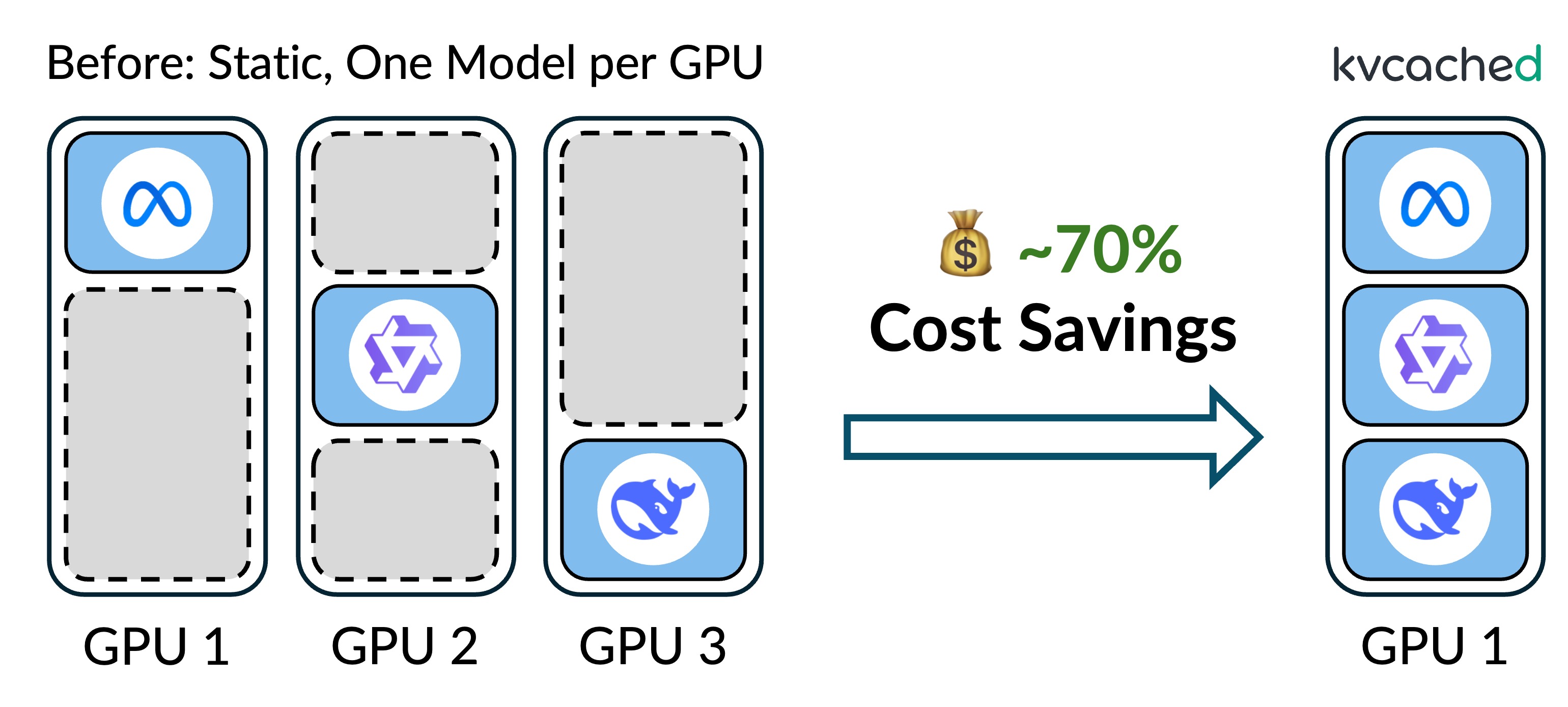
Low GPU utilization is a long-standing pain point for cloud LLM inference providers. As GPUs become more powerful (e.g., faster compute and larger memory), sharing GPUs across multiple models becomes a natural approach to improve efficiency. In our Prism project, we explore flexible GPU sharing for multi-LLM serving.
A central challenge in Prism is model placement: co-locating the right models on shared GPUs to avoid latency SLO violations under dynamic workloads. In this blog, we first present a manually designed placement heuristic, then show how OpenEvolve automatically rediscovers and further improves it, improving the original by 17%.
- 📝 Prism Paper: Prism: Unleashing GPU Sharing for Cost-Efficient Multi-LLM Serving
- ✍️ Previous ADRS Blogs: https://ucbskyadrs.github.io/
- 📝 ADRS Paper: https://arxiv.org/abs/2510.06189
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb
Background: Multi-LLM Serving with GPU Sharing
In real-world deployments, LLM inference providers host many models with long-tailed popularity: a small number of models are hot and receive most requests, while many others are cold and remain largely idle. Moreover, inference workloads are pretty dynamic. The request rates could fluctuate over time, and models frequently can switch between hot and cold states. The traditional approach of dedicating GPUs to individual models therefore leads to poor GPU utilization, especially for cold models with low resource demand.
Prism addresses this inefficiency by enabling flexible GPU sharing across multiple models. By co-locating models on shared GPUs, Prism significantly improves resource utilization and reduces serving costs. At its core, Prism introduces kvcached, a memory sharing mechanism that dynamically allocates KV cache across models using a virtual-memory abstraction. On top of this foundation, Prism provides scheduling algorithms that coordinate resource sharing among models to meet their diverse latency SLO requirements.
The Model-to-GPU Placement Problem
In GPU sharing, the primary bottleneck is often GPU memory, particularly the KV cache, whose footprint grows with the number of active tokens. When multiple models are co-located on the same GPU, they compete for KV cache capacity; once memory becomes scarce, the system must preempt or evict work, leading to degraded TTFT and TPOT.
As a result, model co-location decisions are critical. Placing multiple memory-hungry models on the same GPU can quickly exhaust KV cache capacity, triggering resource contention and ultimately causing latency SLO violations. Prism needs to find a model placement that minimizes SLO violation as much as possible.
This problem is deceptively simple to state (see Prism §6.2 for more details):
- We have N GPUs, each with memory capacity C.
- We have M models, each with:
- a request rate,
- a memory footprint to store its weights,
- an SLO (latency deadline target).
- We want a model-to-GPU placement that minimize the total SLO violation across all models.
Two things make it hard in practice:
- The search space is enormous: N^M possible placements.
- Demand is not predictable: KV cache requirements depend on the output lengths of the queries, and these queries are not known in advance.
As such, practical solutions tend to rely on heuristics, which are fast enough to run online and "good" enough under real traces.
Heuristic: KV Pressure Ratio (KVPR)
To tackle this problem, we rely on a heuristic called the KV Pressure Ratio (KVPR). Rather than attempting precise memory prediction, KVPR provides a coarse but effective signal that captures how "tight" GPU memory is under a given model placement. KVPR measures the intensity of KV-cache contention on a GPU by comparing the urgency of memory demand against the remaining capacity. Formally, it is defined as
KVPR = w_token_rate / shared_kv
w_token_rate = (token_rate * token_size) / SLO
w_token_rate represents a model's SLO-weighted token memory demand rate, and shared_kv denotes the remaining KV-cache capacity on the GPU. Intuitively, a higher KVPR indicates a GPU under greater memory pressure, where KV-cache growth is more likely to be constrained, leading to preemption, eviction, and increased latency. Prism therefore uses KVPR as a guiding metric to evaluate and compare model placements.
Prism's Manually-Designed Scheduler
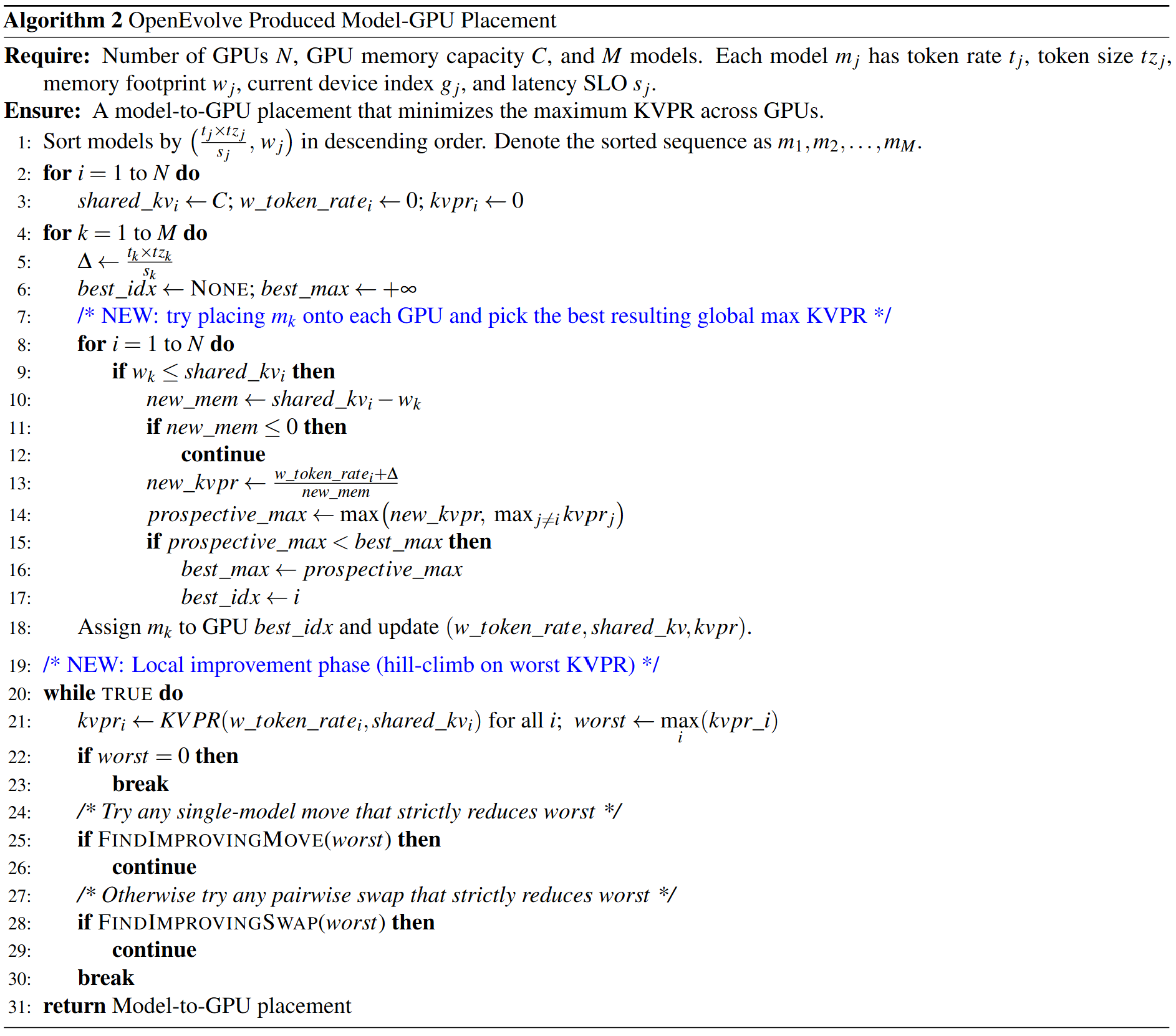
Based on KVPR, we first designed a lightweight placement algorithm that greedily balances KV-cache pressure across GPUs. The algorithm processes models in descending order of their SLO-weighted token demand (t_j x tz_j / s_j), ensuring that models with higher urgency are placed earlier. For each model, the algorithm assigns it to the GPU with the lowest current KVPR, i.e., the GPU where the ratio between aggregated memory demand and remaining KV-cache capacity is minimal. After placement, the algorithm updates the GPU's KV-cache usage and weighted token rate accordingly.
Despite its simplicity, this greedy strategy effectively spreads memory pressure across GPUs, avoids obvious hotspots, and serves as a strong baseline for online model placement in multi-LLM GPU sharing environments.

Using OpenEvolve to Discover and Improve the Placement Algorithm
After learning about ADRS, we decided to explore whether it could automatically discover model placement algorithms that match, or even outperform, our manually designed heuristic. To this end, we used OpenEvolve as the search engine for algorithm exploration.
Experimental setup
We configured OpenEvolve with a lightweight but expressive setup.
- We used ChatGPT-4o-latest for 70% of the evolution steps to enable fast iteration, and o3-2025-04-16 for the remaining 30% to provide deeper reasoning when needed.
- We explicitly defined the KVPR metric and explained how it reflects GPU memory pressure and SLO risk in our prompt.
- We built a simple simulator that generates synthetic workloads consisting of a few popular LLMs with varying request rates, executes the generated placement algorithm, and aims to maximize KVPR. This allowed OpenEvolve to iterate quickly and consistently.
Evolving from a random algorithm
To test whether OpenEvolve could discover a useful strategy without relying on human expertise, we deliberately started from a "naive" initial algorithm. This baseline simply assigns each model to the GPU with the smallest GPU ID that has sufficient memory, an approach that clearly leads to severe load imbalance and high maximum KVPR.
Starting from this naive program, OpenEvolve rapidly discarded the flawed logic and, within three iterations, evolved an algorithm that effectively reproduced a similar algorithm to our manually designed one. This result suggests that, once we specify the optimization objective (KVPR), OpenEvolve can quickly rediscover non-trivial scheduling logic, significantly reducing the manual effort required for algorithm design (see Algorithm 2 below).
Evolving beyond the manual algorithm
Encouraged by this result, we next seeded OpenEvolve with our manually designed algorithm and allowed it to continue evolving. The goal was to evaluate whether OpenEvolve could identify refinements that further reduce the worst-case KVPR.
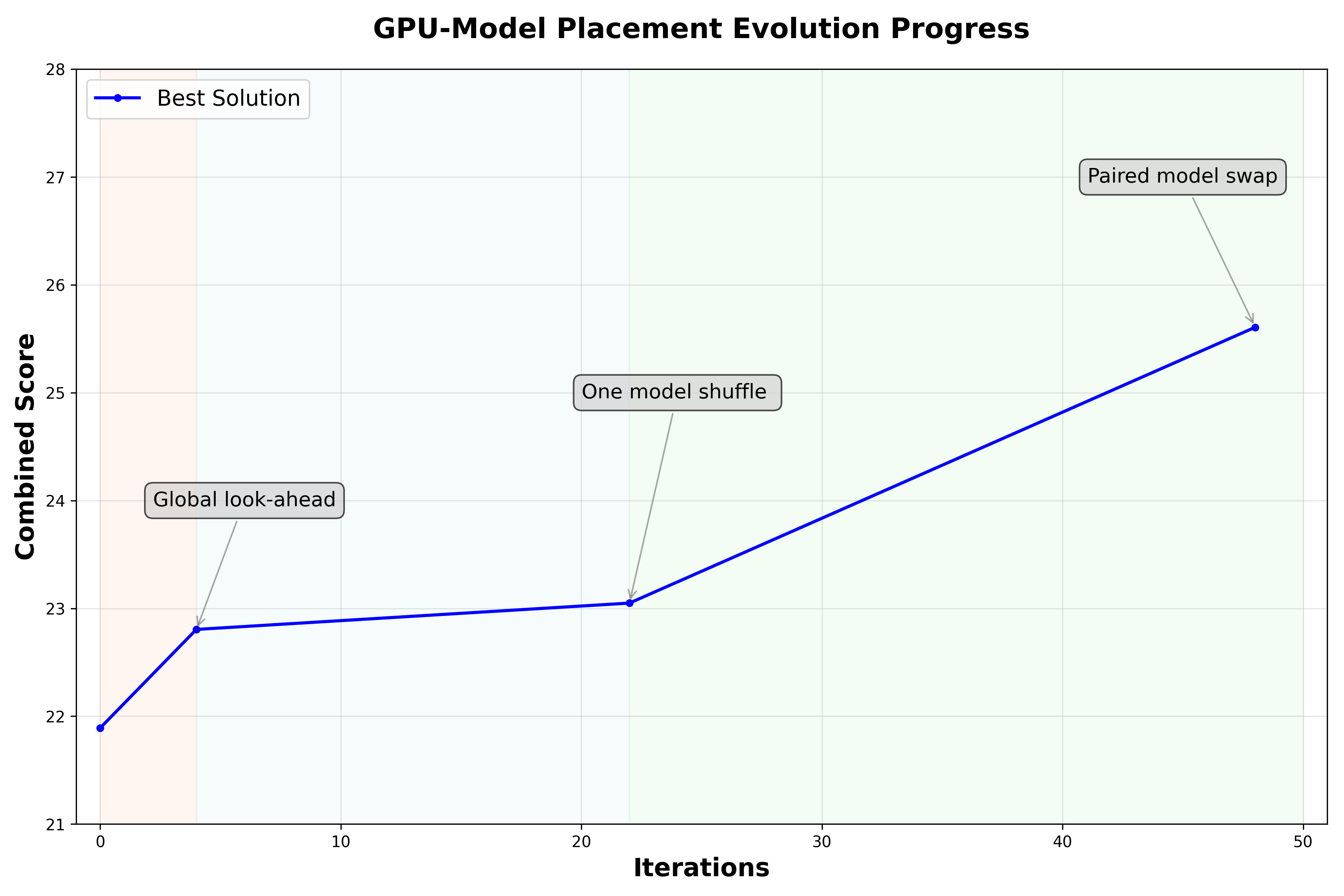
The figure above illustrates the evolution process. The combined score (y-axis) is OpenEvolve's preferred metric for evaluating candidate algorithms, where higher values indicate better performance. We define this score as a combination of $1/max_KVPR$ produced by the algorithm and the code's execution success rate. As shown in the figure, OpenEvolve identifies three key improvements over the initial program, which together resulted in a 17% improvement in the combined score.
The key changes made by OpenEvolve are:
- Look-ahead global KVPR minimization. Unlike the manual heuristic, which assigns each model to the GPU with the lowest current KVPR, this algorithm performs a one-step look-ahead. For each incoming model, it tentatively places the model on every feasible GPU and evaluates the resulting global maximum KVPR. The algorithm then commits the placement that minimizes this worst-case KVPR, explicitly preventing decisions that appear locally optimal but create future memory hotspots.
- Local hill-climbing refinement. After the initial greedy placement, this algorithm introduces a local improvement phase that iteratively reduces the worst-case KVPR.
- Single-model move. In each iteration, the refinement first tries a single-model migration. It identifies the most "pressured" GPUs (highest KVPR) and attempts to move one model from a high-KVPR source GPU to a different target GPU that has enough free memory. A move is accepted only if it strictly reduces the global worst-case KVPR . This operator is lightweight and could fix obvious imbalances created by the greedy placement.
- Pairwise model swap. If no improving single-model move exists, the refinement falls back to a more flexible pairwise swap. It considers swapping a model on a high-KVPR GPU with a model on another GPU, as long as the swap is memory-feasible on both sides. Like above, a swap is committed only when it strictly lowers the maximum KVPR across GPUs. This swap step helps escape local minima where no single model can be moved without making another GPU worse, but exchanging two models can still improve the overall balance.
Summary and Discussion
In this post, we explored the model-to-GPU placement problem in multi-LLM serving and showed how OpenEvolve can automatically discover, refine, and improve placement algorithms, ultimately outperforming the human-designed baseline.
Interestingly, in this experiment, the KVPR heuristic itself is manually designed, based on domain knowledge about GPU memory pressure and SLO behavior. While effective, designing such heuristics requires significant human expertise and iteration. One interesting next step would be applying ADRS-style evolutionary search to the heuristic design process itself. In other words, rather than fixing KVPR a priori, future systems could evolve alternative objectives, such as GPU utilization or overall throughput, which better capture real-world performance trade-offs.
Moreover, our evaluation relies on a simulator to enable fast and reproducible evolution. While this is essential for rapid search, simulation inevitably abstracts away hardware-level effects. A natural next step is to combine simulation with real-GPU evaluation in a hierarchical evolution loop--using the simulator for broad exploration and pruning, and selectively validating promising candidates on real GPUs. Such a hybrid approach could further close the gap between evolved algorithms and production deployments, while keeping the search tractable.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t and Discord
🗞️ Follow us: x.com/ai4research_ucb