Automating Algorithm Discovery: A Case Study in Optimizing LLM Queries over Relational Workloads
💡
This post is part of our AI-Driven Research for Systems (ADRS) case study series, where we use AI to automatically discover better algorithms for real-world systems problems.
In this blog, we revisit a recent research challenge from our MLSys '25 paper, "Optimizing LLM Queries in Relational Data Analytics Workloads ", which tackles the high cost and latency of executing LLM queries over relational data. We show how using OpenEvolve, ADRS autonomously discovered a 3× faster algorithm that achieves the same prefix reuse ratio as the published solution. This case study shows how AI can independently improve even state-of-the-art algorithms in LLM-based data analytics.
- ✍️ Previous Blogs: https://ucbskyadrs.github.io/
- 📝 Paper: https://arxiv.org/abs/2510.06189
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb
The Problem: LLM Queries are Slow and Expensive
Large language models (LLMs) are increasingly used in relational data analytic workloads, where SQL queries or DataFrame operations invoke LLMs over relational (table-based) data. Major analytics platforms, such as AWS Redshift, Databricks, and Google BigQuery, now integrate LLM functionality directly into their SQL APIs. Similarly, modern DataFrame libraries like LOTUS support LLM calls over structured data.
For example, a user might issue the following query to check whether a product description matches its review:
SELECT LLM(
"Is the description consistent with the review?",
Description, Review
) FROM Products;
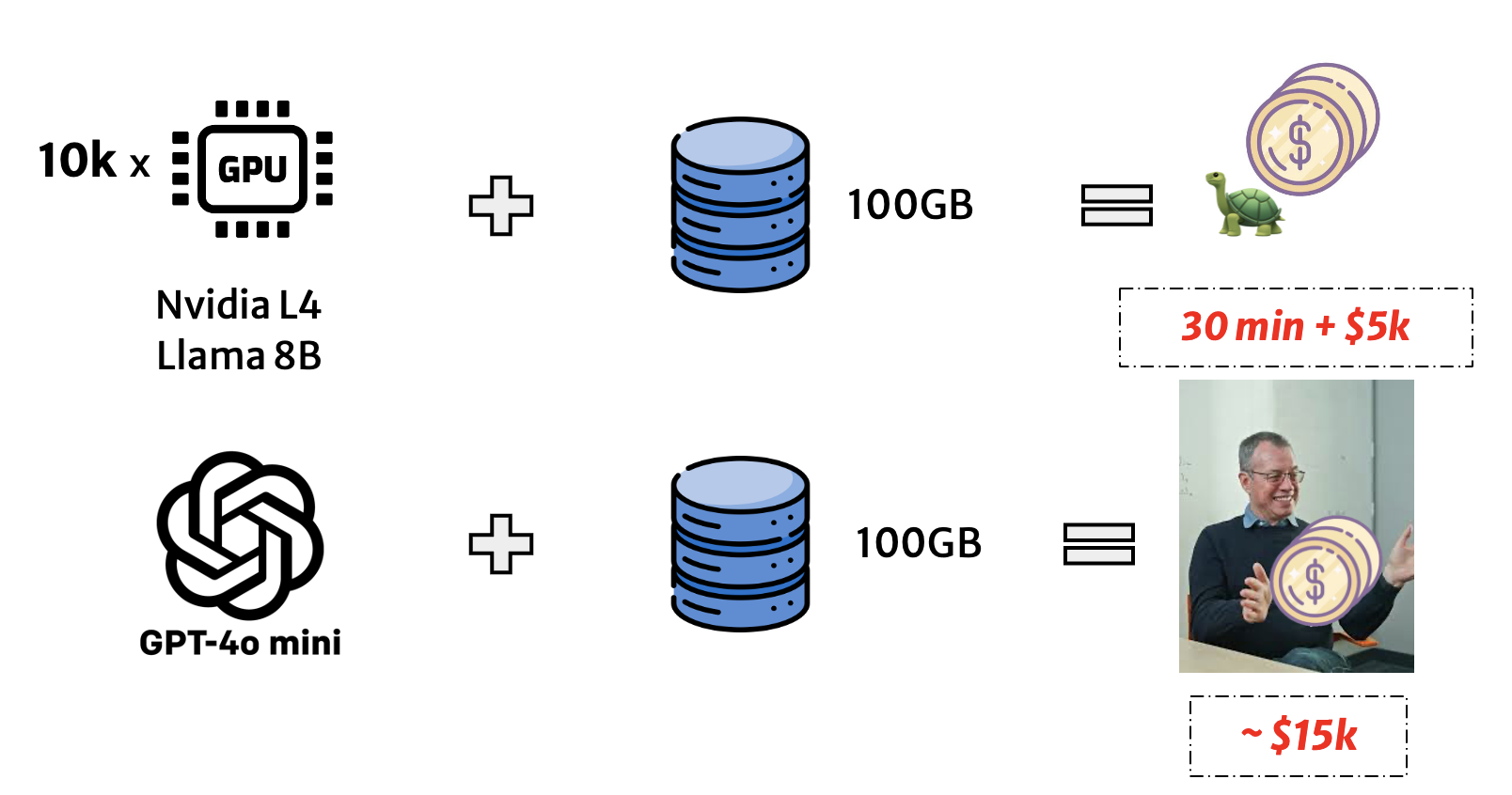
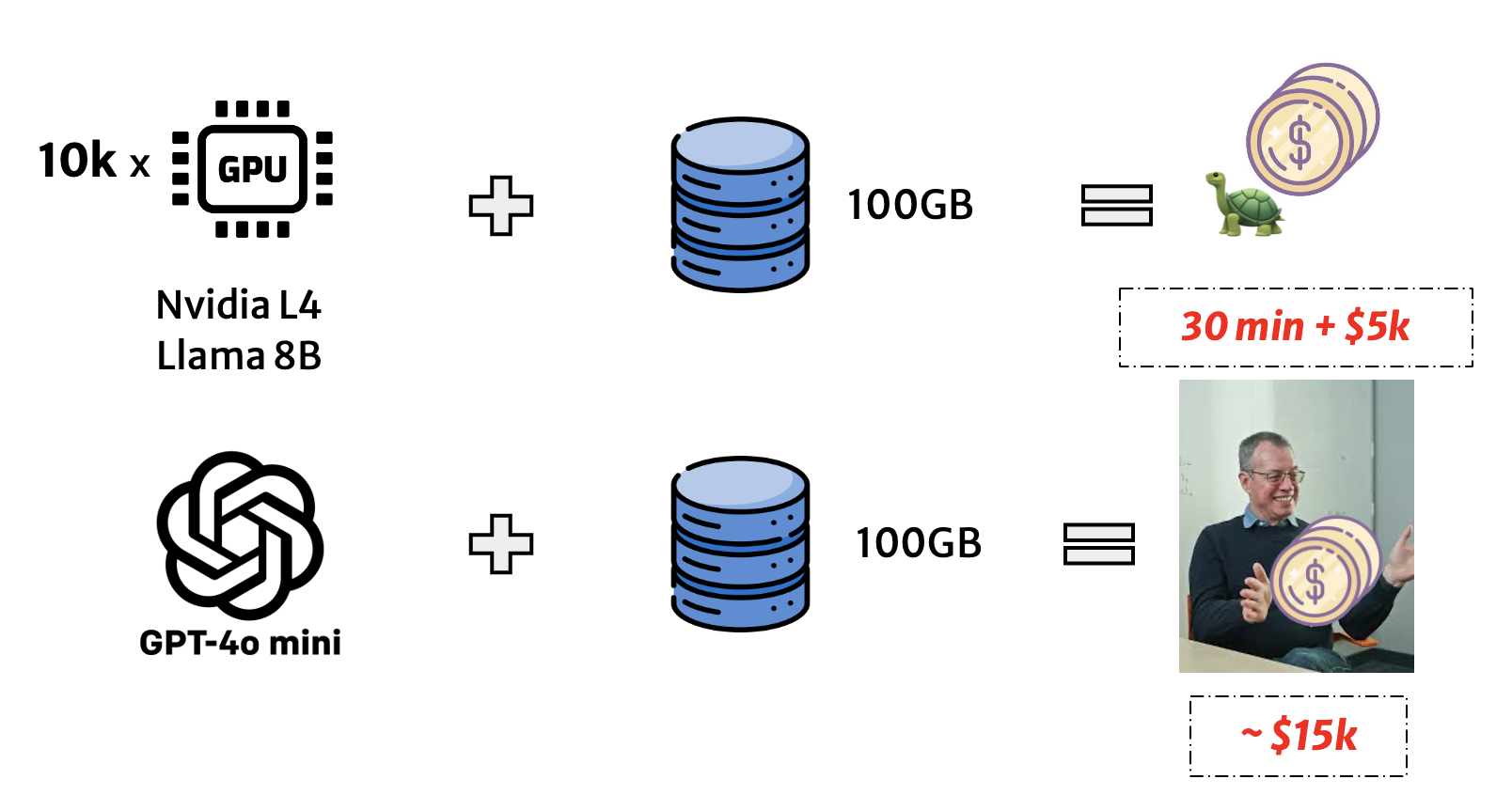
This simple-looking query triggers one LLM inference per row, often thousands or millions of times. Running such queries on commercial APIs or GPUs is prohibitively slow and expensive. For instance, as shown in Figure 2, executing a 100 GB table on Llama-3-8B with NVIDIA L4s can take 30 minutes and cost over $5K, and scaling to full-dataset analytics can reach $15K per query.
Prefix Reuse
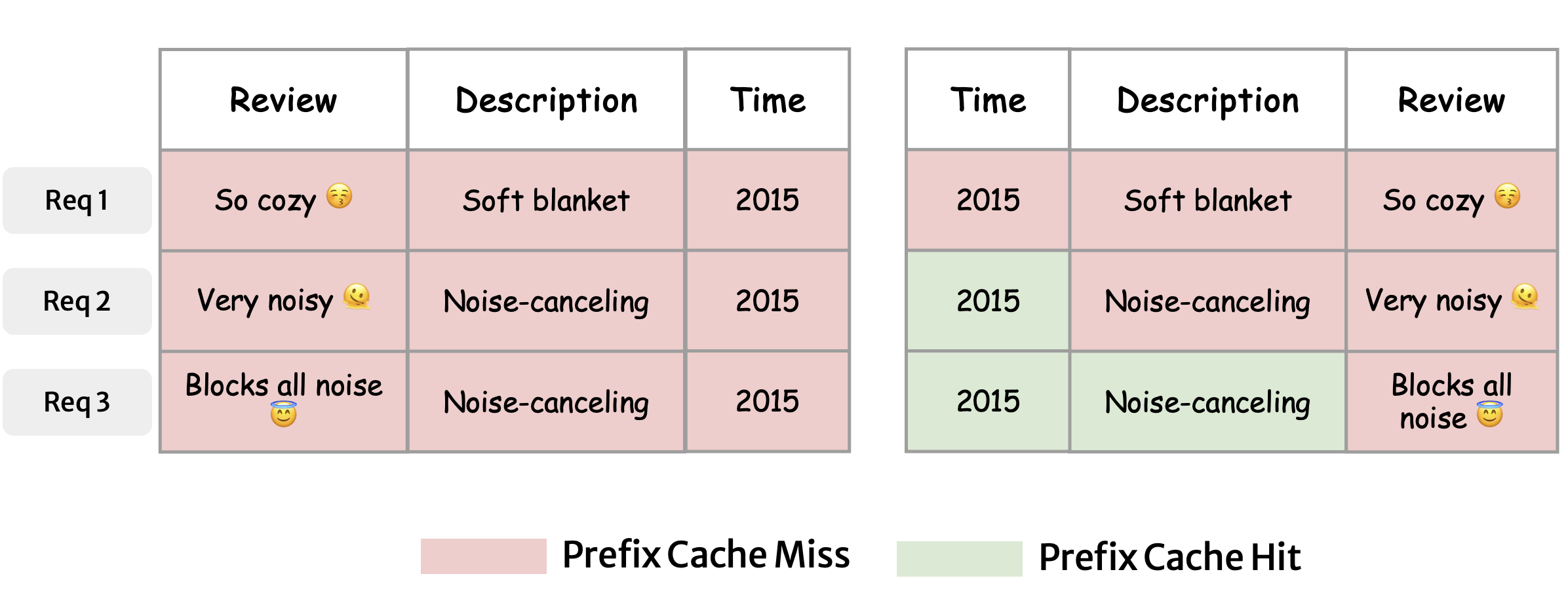
One of the key insights from the MLSys '25 paper is that relational tables often contain repeated values. Some examples are identical timestamps, product categories, and metadata fields shared across many rows. However, LLMs can reuse computation only when the shared parts appear as a prefix in consecutive prompts. In such cases, the model can avoid reprocessing the repeated tokens by reusing their intermediate computed states, stored as key and value (KV) vectors in the KV-cache.
In practice, standard table orderings rarely align these shared prefixes, forcing the model to redundantly re-compute identical values across rows. The MLSys '25 paper shows that by reordering the table's columns and rows so that similar prefixes appear consecutively, the LLM can reuse its KV-cache across successive inference operations. This eliminates redundant computation and significantly reduces both latency and cost, as cached prefix tokens are 2-10× cheaper to compute. Figure 3 illustrates this intuition.
SOTA Algorithm: Greedy Group Recursion (GGR)
To exploit the structure of relational tables, the reordering algorithm aims to maximize prefix cache hit rate (PHR), i.e., the fraction of tokens reused across consecutive LLM inference requests. However, finding the optimal ordering is combinatorially intractable: a table with $n$ rows and $m$ fields has $n!\times(m!^n)$ possible orderings.
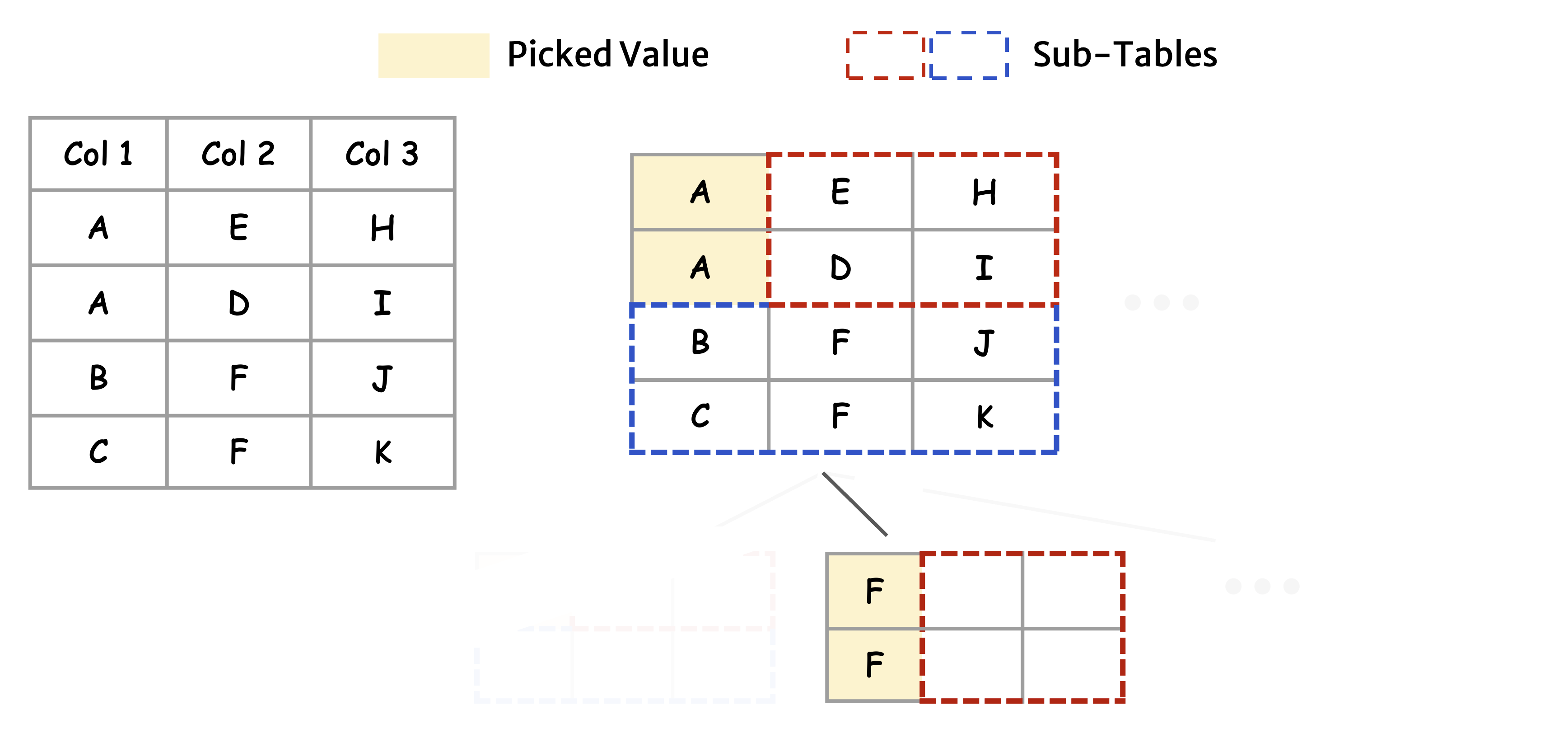
The Greedy Group Recursion (GGR) algorithm proposed by the paper provides a practical approximation. It works by recursively scanning the table to find the value that contributes most to prefix reuse (typically one that is both frequent and long). Once this value is found, GGR prioritizes the column in which it occurs, moving that field earlier in the ordering. After selecting that column, GGR partitions the table into smaller subsets: rows sharing that value form one group, and the rest form another. The same process is then applied recursively within each subset (Figure 4).
This recursive grouping naturally aligns rows that share prefixes, enabling high cache reuse across LLM inferences. To further improve algorithm efficiency, GGR uses functional dependencies and table statistics (e.g., average string length, value cardinality) to decide when to stop recursion early.
Despite achieving near-optimal cache reuse in practice, GGR remains computationally expensive: it repeatedly scans tables and performs deep recursion, which adds runtime overhead and makes it difficult to scale to larger tables. This inefficiency makes it a natural target for automated optimization using ADRS.
Discovering a Better Reordering Algorithm
We apply OpenEvolve to automatically search for a better reordering algorithm for LLM-SQL queries. The simulator models an LLM inference engine executing over relational tables and evaluates two key metrics: the prefix cache hit rate (PHR) and the runtime of the reordering algorithm. The optimization objective is to match the original PHR of the GGR algorithm while minimizing algorithm runtime overhead. Each candidate algorithm is scored based on a weighted combination of these two metrics.
We run OpenEvolve for 100 iterations using a three-island setup, powered by an ensemble of 80% OpenAI o3 and 20% Gemini 2.5 Pro models. The full evolution completes in roughly one hour and costs under $7. We set our initial program as the GGR algorithm, and show the evolved policy as in Figure 5.

The new algorithm discovered by OpenEvolve fundamentally restructures the reordering process around local continuity instead of global recursion. Rather than repeatedly splitting and traversing the table, it focuses on optimizing token reuse between adjacent rows, treating the dataset as a continuous sequence rather than a recursive tree. OpenEvolve introduces three key innovations that drive this transformation:
- Lazy counting: value frequencies are computed once globally and reused across recursive steps, eliminating redundant scans.
- Adaptive recursion: recursion is skipped for small subtables (below a base threshold of ~4 K rows), avoiding unnecessary overhead.
- Vectorized per-row reordering: each row is reordered relative to its predecessor using NumPy-level vectorization, replacing slow Pandas operations.
These design changes reduce the algorithm's complexity from recursive traversal to a lightweight sequential scan, with high cache locality. The evolved algorithm achieves comparable PHR to the original GGR while running 3× faster, significantly lowering the algorithm pre-processing time for LLM-SQL queries.
Evolution Process
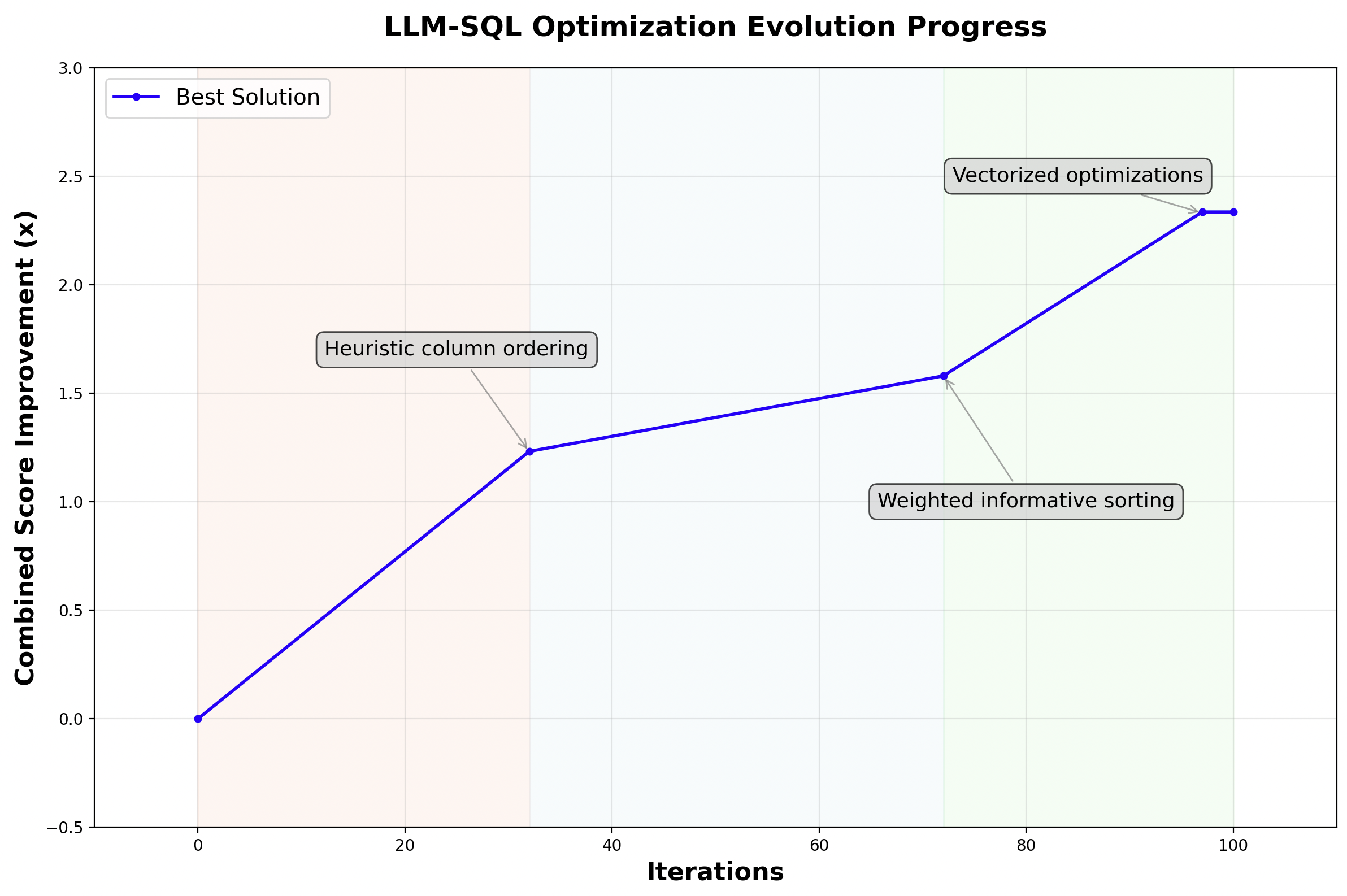
We show the evolution progress in Figure 6. By iteration 32, OpenEvolve makes its first breakthrough. It replaces the recursive splitting with a simpler, faster heuristic that ordered columns by (frequency × squared length). This change eliminated redundant value counting and dramatically improved runtime, even if it slightly reduced grouping accuracy. Around iteration 72, the system refines this idea further. The heuristic evolves into a normalized weighting scheme and begins sorting only the most informative columns rather than all of them. This selective attention improves prefix hit rates while keeping the new algorithm lightweight.
By iteration 97, the algorithm had converged to a clean, optimized form. It introduced a higher recursion base threshold to avoid unnecessary splits, reused cached counts and string lengths, selectively re-applied recursion to difficult subsets of rows, and switched to a NumPy-based reordering strategy that replaced slow Pandas lookups with vectorized array operations.
Discussion
This case study tackles a recent and timely research problem in optimizing LLM-based data analytics, an area where even the latest state-of-the-art algorithm left room for improvement. Starting from a complex recursive baseline, it distilled the logic into a simpler, data-parallel policy that preserves accuracy while cutting runtime by 3×. The result highlights a key benefit of AI-driven research: instead of manually tuning algorithms, researchers can now evolve efficient variants guided by simulation feedback. In practice, this enables faster, cheaper, and more scalable execution of LLM-based analytics workloads.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t and Discord