Automating Algorithm Discovery: A Case Study in Multi-Cloud Data Transfer
This post is part of our AI-Driven Research for Systems (ADRS) case study series, where we use AI to automatically discover better algorithms for real-world systems problems.
In this post, we study Cloudcast, a problem originally introduced in an NSDI '24 paper, which focuses on cost-aware data multicasting across multi-region and multi-cloud networks. The goal is to transfer large datasets from one source to many destinations while minimizing total egress cost.
We start from a simple, intuitive baseline strategy and show how GEPA automatically discovers a significantly more cost-efficient solution, achieving over 30% cost reduction and converging to a structure close to the human-designed state-of-the-art. GEPA's solution builds a single overlay that connects all nodes through a set of carefully chosen intermediate waypoints rather than sending data separately to every destination.
- 📝 Cloudcast Paper: https://www.usenix.org/system/files/nsdi24-wooders.pdf
- ✍️ Previous ADRS Blogs: https://ucbskyadrs.github.io/
- 📝 ADRS Paper: https://arxiv.org/abs/2510.06189
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb
Background: Multi-Cloud Data Multicasting
In real-world multi-cloud deployments, systems frequently need to multicast the same data from a source node to many destination nodes across different clouds and regions. These multicasts traverse heterogeneous and asymmetric cloud networks, where link bandwidths, latencies, and, most importantly, monetary egress costs vary widely across intra-cloud and inter-cloud connections. Available paths also differ across providers, making the cost of data transfers topology-dependent.
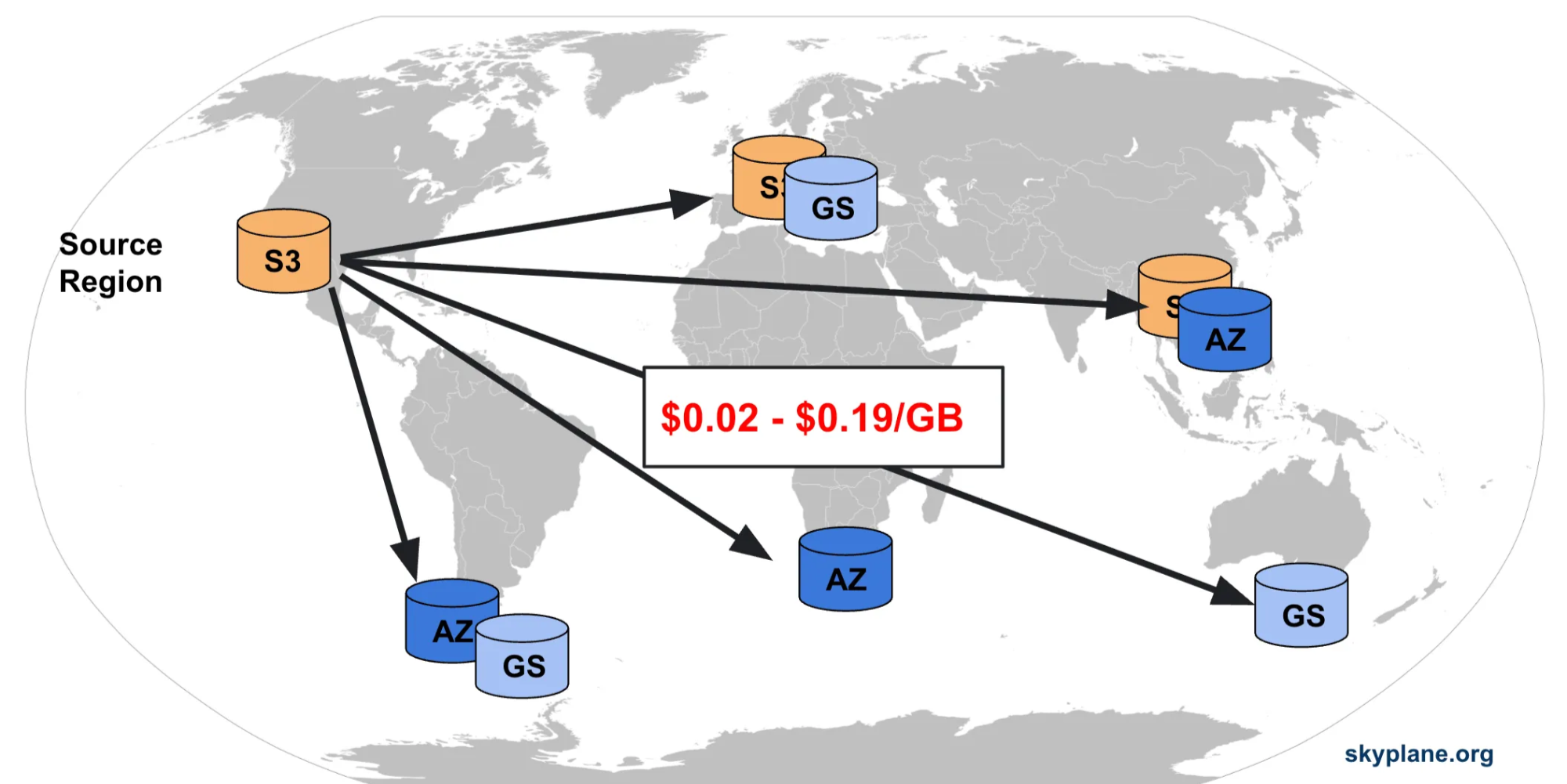
The Multi-Cloud Data Transfer Cost Problem
In multi-cloud data multicasting, the primary cost is often data egress. When data is transferred across cloud providers or regions, each transfer incurs a monetary charge that can vary significantly depending on the source, destination, and network path. As shown in Figure 2 below, transferring the same data item independently from a source region to each destination region can lead to substantial costs.
Indeed, sending identical data directly from the source to every destination leads to redundant transfers over expensive inter-cloud links, unnecessarily inflating total egress cost. In contrast, by carefully designing a multicast tree, we can reuse intermediate transfers, route data through cheaper links, and reduce the overall cost of moving data across clouds. Cloudcast therefore seeks multicast trees that minimize total egress cost while delivering data to all destinations.
This problem is deceptively simple to state. Given:
- a source node storing the input data
- a set of destination nodes located in multiple clouds and regions
- a multi-cloud network topology, where different links can have different egress costs
- a completion time deadline, the maximum allowable time to finish the transfer, typically defined as a multiple of the fastest direct transfer time
- partition the data into multiple stripes to enable parallel transfers (each stripe can be transferred independently)
- compute a tree topology that minimizes the total data transfer (egress) cost to deliver the data from the source to all destinations.
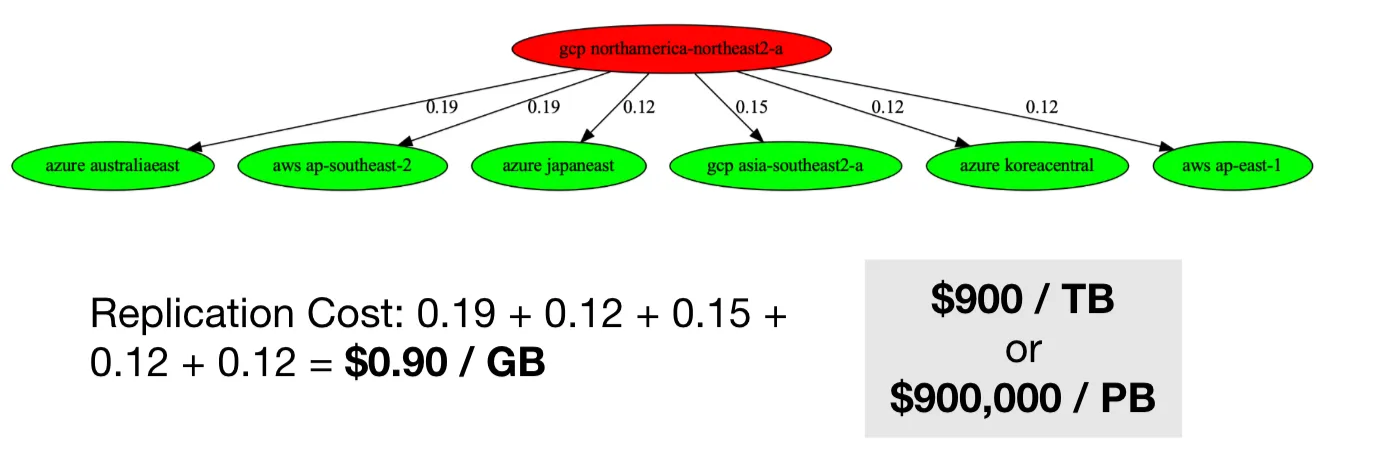
Two factors make this problem challenging in practice:
- The search space is large: there are many possible ways to route and combine transfers across intermediate nodes and networks.
- Network costs are heterogeneous: different paths incur different egress charges, and the cheapest path for one destination may be suboptimal when multicasting to many destinations simultaneously.
As a result, practical solutions rely on cost-aware heuristics that exploit network structure, reuse intermediate transfers, and balance data movement across cheaper paths to reduce total egress cost.
Cloudcast Scoring Function
To tackle this problem, Cloudcast evaluates a multicast strategy based solely on its data transfer (egress) cost, while requiring that the resulting multicast meets strict end-to-end time constraints. Rather than modeling low-level packet scheduling or instance execution cost, the objective focuses on how efficiently data is moved across cloud networks.
Formally, Cloudcast minimizes the total egress cost of a multicast topology:

Here:
- P denotes the multicast topology (i.e., the set of transfer paths),
- the data is partitioned into STRIPES to enable parallel transfers,
- P_s is the transfer path used for stripe s,
- ⟨cost^path, P_s⟩ represents the egress cost incurred along that path.
Intuitively, this objective penalizes multicast trees that rely on expensive or redundant network transfers. By striping data across multiple paths, the objective naturally favors strategies that reuse intermediate transfers, balance load across networks, and exploit parallel, low-cost routes in the multi-cloud topology. Multicast trees that violate time constraints are treated as infeasible and discarded.
Cloudcast uses this objective as a scoring function to compare candidate multicast trees. Lower scores correspond to multicast topologies that minimize data transfer cost while satisfying the required completion-time constraints, guiding the evolution.
Baseline: Direct Replication
The most straightforward approach is direct replication.
Under this strategy, the source independently sends a full copy of the data to every destination. Each transfer is treated as a separate operation, and no intermediate nodes are used.
This approach is appealing because it is easy to implement, guaranteed to reach all destinations, and does not require global coordination. However, it is also inefficient.
Direct replication ignores the structure of the network. It fails to exploit the fact that many destinations may share common paths, providers, or cheaper regions. As a result, the same expensive links are paid for repeatedly, leading to unnecessarily high total cost.
In multi-cloud settings, this inefficiency becomes particularly severe, because cross-cloud egress links are often orders of magnitude more expensive than intra-cloud transfers.
Using GEPA to Discover Cheaper multicast Algorithms
We use GEPA to automatically search for better multicast trees.
Experimental Setup
We provide GEPA with an evaluator that scores candidate algorithms by total egress cost only. We evaluate 6 different network topologies with real egress costs across GCP, Azure, and AWS.
We start the evolution with our direct replication baseline.
Performance and Results
We run for 100 iterations with GPT-5 model on GEPA. Across a wide range of multi-region, multi-cloud configurations, the evolved algorithm achieves:
- 31.1% average cost reduction compared to direct replication
- Performance close to the human-designed state-of-the-art solution
- Stable behavior across different network structures
The Discovered Algorithm

The evolved algorithm consistently constructs shared multicast trees instead of independent paths. Rather than sending data separately to every destination, it builds a single overlay that connects all nodes through a set of carefully chosen intermediate waypoints.
Conceptually, the evolved strategy behaves as follows:
- It identifies regions where data replication is relatively cheap.
- It routes traffic through these regions to amortize expensive egress links.
- It minimizes the number of times costly inter-cloud edges are used.
- It allows multiple destinations to reuse the same upstream transfers.
The resulting topology is structurally close to a Steiner tree: a minimal-cost subgraph that connects all required nodes using optional intermediate vertices.
Discussion: Beyond Cost-Only Optimization
In this study, we formulate Cloudcast as a pure cost minimization problem. This makes it an ideal sandbox for studying algorithm discovery, because the objective is clean, stable, and easy to evaluate. In real systems, additional constraints, such as latency, reliability, fault tolerance, and network congestion often matter.
A natural next step is to extend this framework to multi-objective evolution, where cost must be balanced against performance and robustness. This would allow the ADRS framework to search not just for the cheapest solution but also for the best trade-off frontier across multiple system dimensions.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t and Discord
🗞️ Follow us: x.com/ai4research_ucb