Automating Algorithm Discovery: A Case Study in MoE Load Balancing
This post is the first in a series of case studies in which we apply AI-Driven Research for Systems (ADRS) to optimize performance in various systems. In this blog, we discuss the optimization of a key component in large language model (LLM) inference. Specifically, we demonstrate how OpenEvolve independently discovers and surpasses highly optimized algorithms engineered by human experts to achieve a 5.0x speedup.
- ✍️ Previous blog post: https://ucbskyadrs.github.io/blog/
- 📝 Paper: https://arxiv.org/abs/2510.06189
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- 🌎 Follow us: x.com/ai4research_ucb
The Problem: Balancing Load for MoE Inference
The immense scale of modern LLMs is made manageable by architectures like Mixture-of-Experts (MoE). In this model, a router dynamically sends each token of an input to a small subset of specialized "expert" networks. This allows requests to be processed using only a fraction of the model's total parameters, greatly improving inference efficiency. However, this architecture introduces the critical performance challenge of balancing the load across these experts.
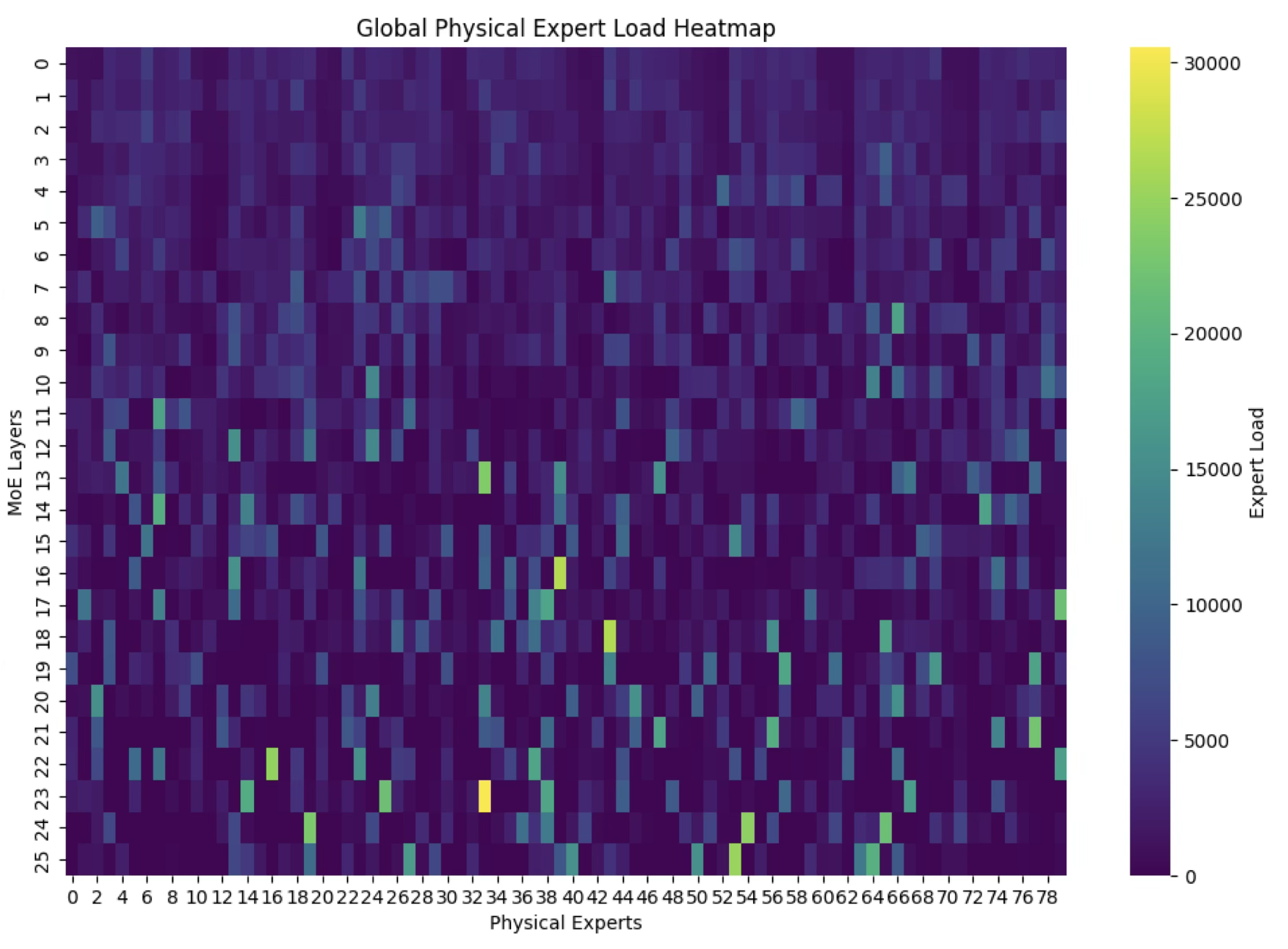
Inevitably, some experts become more popular or "hot," creating computational bottlenecks. The GPUs hosting these hot experts are overwhelmed, while others sit idle, wasting valuable resources (Figure 1).
The solution is an Expert Parallelism Load Balancer (EPLB), an algorithm that dynamically rearranges experts across GPUs to minimize load imbalance and maximize system throughput. The basic EPLB algorithm runs in three stages:
- (i) distribute expert groups across nodes to balance the load
- (ii) create replicas for hot experts
- (iii) assign these replicas to GPUs to further maximize load balancing.
Given a workload, an MoE setup, and some GPUs, the EPLB algorithm determines the number of replicas for each expert and then maps these replicas onto GPUs.
The EPLB algorithm has two objectives:
- Minimize imbalance: Distribute the load as evenly as possible.
- Minimize runtime: The rearrangement process itself must be fast to avoid becoming a new bottleneck.
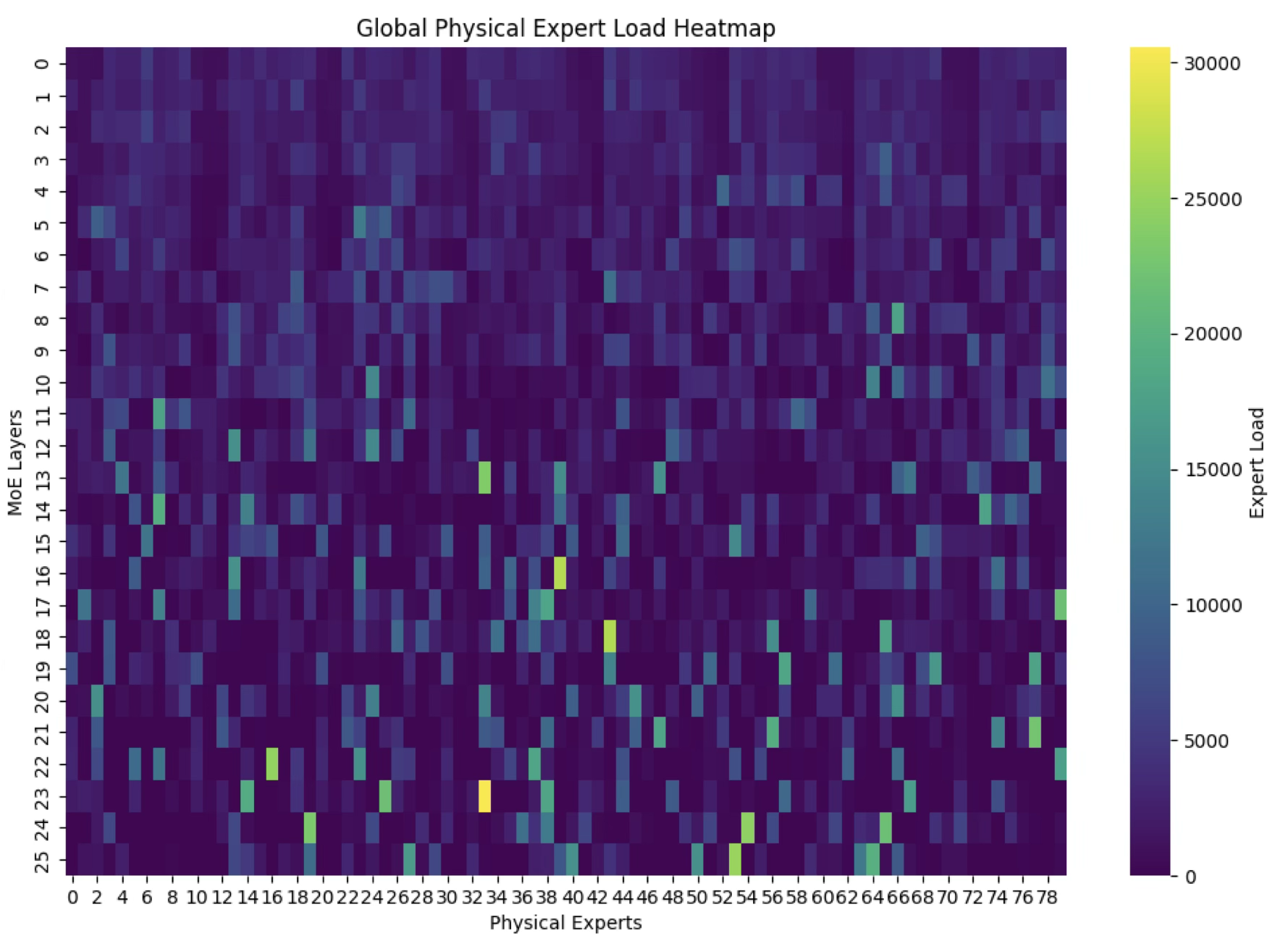
The EPLB algorithm has a direct impact on the cost and performance of production LLM serving (Figure 2).
Existing EPLB Algorithms
We consider two baselines in searching for a better EPLB algorithm.
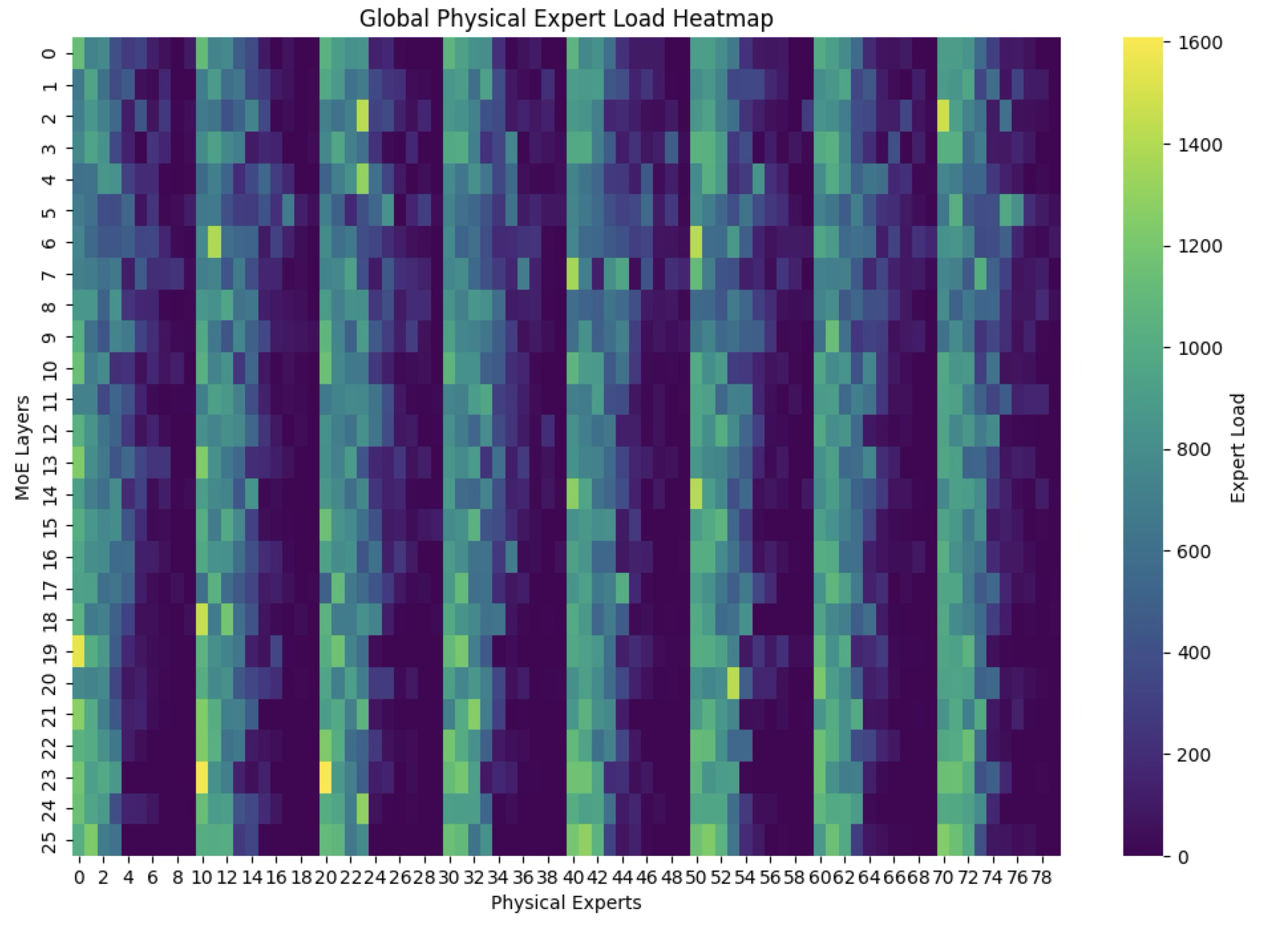
First, we evaluate DeepSeek's open-source EPLB implementation. This employs a greedy bin-packing strategy: experts are sorted by load in descending order, and each is placed onto the least-loaded GPU that has capacity (Figure 3a, Example 1). While simple, the solution is slow because it is written in Python and uses a for-loop to perform linear search for finding the best-fit GPU choice. On average, it takes about 540 ms to re-balance the experts and achieves a load balance factor of 0.66 (calculated as the ratio of average to maximum tokens generated per GPU).
Example 1. The original EPLB algorithm greedily places the heaviest expert onto the least-loaded GPU in a step-by-step manner, implemented with slow Python for-loops.
We also consider a non-public reference implementation from a frontier lab that we have access to. This implementation avoids explicit iteration and reduces the rebalancing algorithm runtime to 19.6 ms while achieving the same balance factor as the open-source algorithm.
Discovering a Novel Algorithm with OpenEvolve
We apply OpenEvolve to search for an EPLB algorithm. We use a simulator that models a distributed GPU inference engine for MoE models and is implemented in PyTorch. For workloads, we model the load changes over the ShareGPT and GSM8K datasets. Our optimization goal is twofold: to maximize the load balance factor (i.e., the ratio of average to maximum tokens generated per GPU) and to reduce the running time of the algorithm used to re-balance experts when the load changes. Consequently, we score algorithms based on the weighted average of the load balance factor and inverse of run time (since higher scores mean better algorithms).
We run OpenEvolve using a combination of 80% Gemini 2.5 Flash and 20% Gemini 2.5 Flash Lite. We cap the evolution at 300 iterations, starting with the greedy open-source implementation as the initial program. The total evolution takes roughly five hours and costs less than $10.

The new algorithm generated by OpenEvolve discovers a clever heuristic to replace the linear for-loop: instead of explicit bin packing, it reshapes and transposes tensors representing expert indices, using PyTorch's fast tensor operations to effectively stagger expert assignments via a zigzag (or "snake") pattern between heavily and lightly loaded GPUs. The main idea is to alternate expert placement in a way that naturally interleaves high-load and low-load experts across GPU slots (Figure 3b, Example 2). OpenEvolve also introduces subtle enhancements, including improved ordering logic and more adaptive reshaping strategies. The resulting algorithm matches the load balance factor of the other baselines while reducing runtime to just 3.7 ms, yielding a 5.0x speedup over the internal reference implementation.
Example 2. The new zig-zag pattern employs a simple yet effective heuristic for assigning experts to GPUs, often achieving an optimal arrangement. This can be implemented via fast PyTorch vectorized operations.
Evolution Process
Figure 4 shows how the evolution progressed over time. The trajectory can be characterized by two major steps in improving runtime: first, replacing Python for-loops with PyTorch tensor operations, and second, discovering the zigzag placement pattern. Interestingly, the initial introduction of the zigzag pattern did not yield immediate gains--the imbalance factor sometimes worsened, and rearrangement costs fluctuated. The breakthrough came when the AI learned not just to use the zigzag heuristic, but to apply it systematically across multiple stages of the algorithm, reducing runtime significantly.
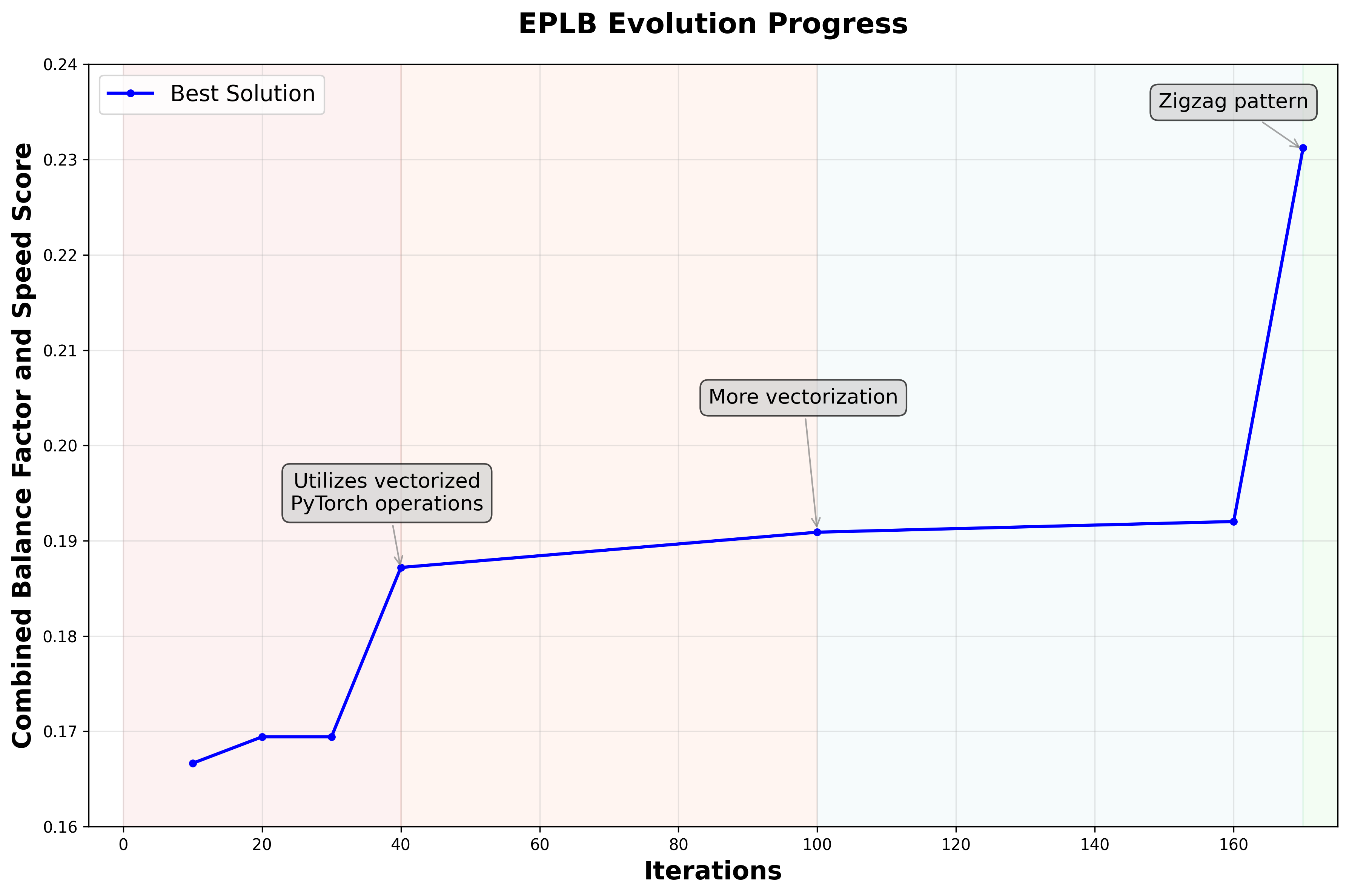
In contrast, the expert replication stage remained the most unstable throughout evolution. The system oscillated between strategies such as copying the least-used experts, overloading popular ones, or attempting proportional spreads. These experiments rarely improved the score, and ultimately the intuitive rule of replicating only overloaded experts prevailed. Consequently, many iterations were unproductive, with the main speed improvements coming from global reorganization logic that exploited PyTorch's batched operations and the zigzag layout.
In summary, OpenEvolve independently rediscovered and fully exploited a zigzag partitioning scheme, yielding an evolved EPLB algorithm that achieves a 5.0x speedup while achieving the same load balance factor.
Parting Thoughts
The 5.0x speedup achieved in this case study is a compelling demonstration of a new research paradigm. In just five hours, an ADRS framework was able to discover a state-of-the-art solution that would typically consume days or weeks of an expert engineer's time, validating the core promise of ADRS to accelerate discovery. Crucially, the AI delivered both engineering optimizations, such as replacing loops with vectorized tensor operations, and a fundamental algorithmic improvement by discovering the zigzag partitioning scheme. We'll integrate this optimized algorithm into vLLM, a popular open-source LLM inference and serving engine. The ability to devise sophisticated computational strategies proves that ADRS can tackle complex, real-world problems, moving far beyond black-box tuning for applying AI to systems. This exploration of MoE load balancing is the first of several deep dives we will share in the coming weeks, as we continue to demonstrate the transformative potential of this new framework.