Agentic Memory Management for GPU Code Generation
This post is part of the AI-Driven Research for Systems (ADRS) blog series, where we explore how AI can be applied to systems research. We feature exciting work from Makora this week!
In this blog post, we examine the problem of balancing memory and other knowledge sources for GPU kernel generation agents. Memory helps GPU kernel agents only when it saves more search than it costs in context. Search discovers useful coding patterns, and memory prevents rediscovering them.
- ✍️ Previous Blogs: https://ucbskyadrs.github.io/
- 📝 ADRS Paper: https://arxiv.org/abs/2510.06189
- 👩💻 ADRS Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb and LinkedIn
Introduction
Everyone agrees that agents need memory but the harder question is when they should ignore it. In most agentic systems, memory is treated as long-term recall: store prior experience, retrieve relevant pieces later, and use them to improve the next action. That framing is incomplete for optimization agents. GPU kernel generation is an iterative search problem: each candidate must be generated, compiled, checked for correctness, benchmarked, and often profiled before the agent knows whether it improved the objective. In principle, this loop can be extended with more inference-time compute, and recent work on kernel generation explicitly benefits from such scaling. In practice, however, each additional iteration consumes model calls, compiler time, benchmark time, and accelerator time, so the agent operates under a practical compute/search/context budget [1,2]. The current candidate code, the latest compiler error, profiler output, retrieved documentation, prior kernels, and run-local notes all compete for the same memory. Adding memory is not free: the wrong memory can crowd out the local evidence that an agent needs to make the next kernel better.
This suggests a different view. For GPU code generation, memory looks less like a notebook and more like a cache. A useful retrieval is a cache hit as it avoids recomputing or rediscovering information that would otherwise cost additional search. Stale entries, low-utility items, and prompt clutter are the corresponding failure modes.
Using MakoraGenerate, our GPU kernel generation agent, we argue that cache-style context management is especially important for optimization agents with hard per-step budget pressure and can be evaluated against a verifiable objective. The key question is not how much memory an agent can access. It is what belongs in the agent's working set (or "cache") at each step.
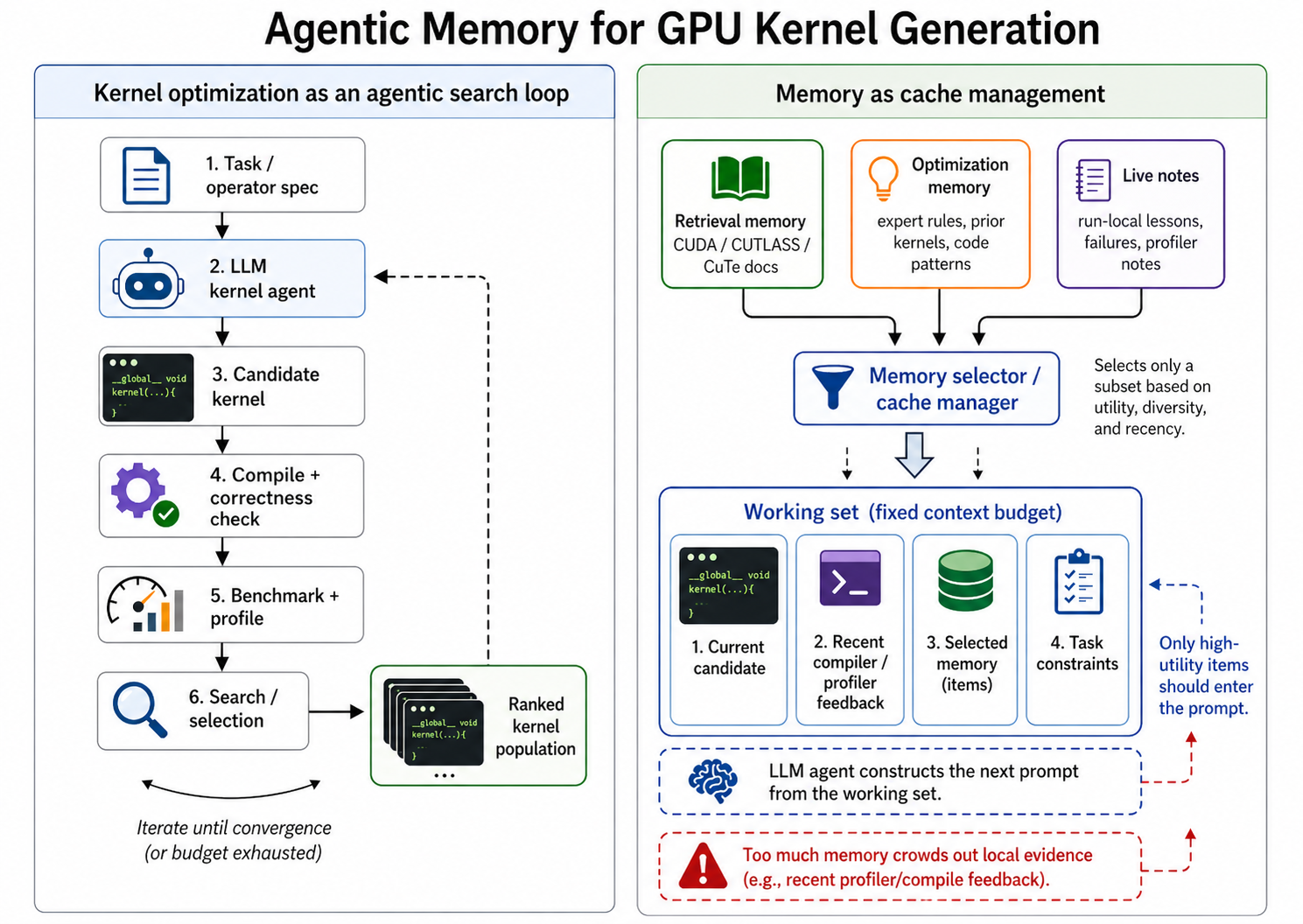
Kernel generation as an agentic search problem
Some parts of systems research are surprisingly amenable to automation. When the problem comes with a verifier that exactly represents the optimization objective -- runtime, throughput, latency, cost -- an agent can propose candidates, evaluate them, and search its way toward better ones. Pair an LLM with this loop and let iteration do the work. That recipe is the basis of AI-Driven Research Systems (ADRS).
MakoraGenerate is our instantiation of this recipe for GPU kernel optimization. It is a configurable multi-agent evolutionary system that generates, compiles, validates, and benchmarks kernels across NVIDIA GPUs, AMD GPUs, TPUs, and NPUs. At each step, an LLM proposes a candidate kernel, the system checks correctness against a PyTorch reference implementation on identical, randomly-seeded inputs across multiple trials, and requires that every output tensor match the reference in dtype, shape, and value within configurable absolute/relative tolerances. Then, the agent profiles runtime, and the measured speedup over a baseline serves as the reward. The agent maintains a ranked population and uses diversity-based selection to inherit effective patterns while avoiding premature convergence.
The baseline already has some memory, the search state itself. Past candidates and recent failures shape the next generation. But this is within-run artifact memory. It carries continuity inside a single search; it does not accumulate reusable knowledge across kernels, operators, or hardware backends. Adding richer memory is what we ablate next.
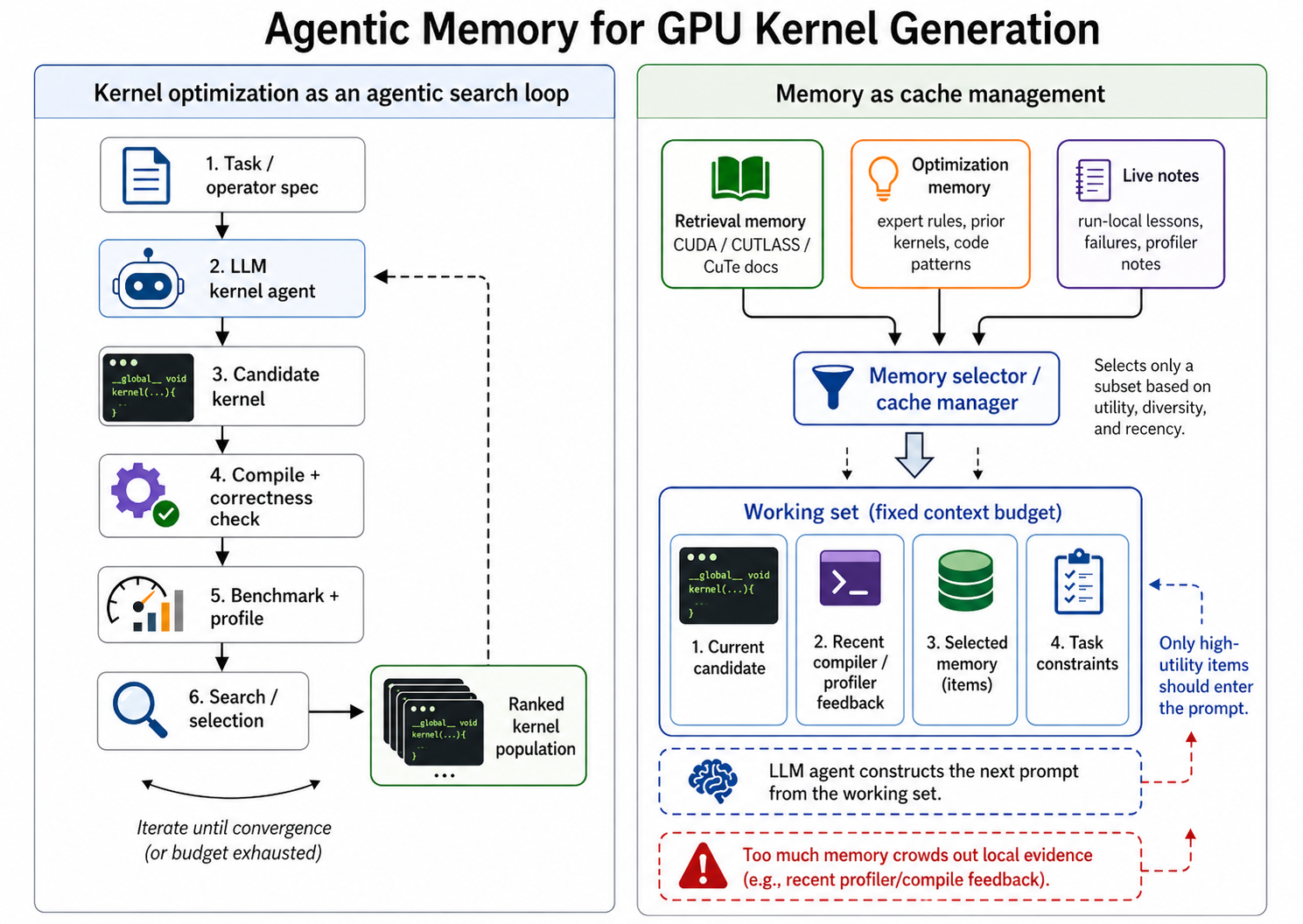
Knowledge sources
Each memory type we use plays a distinct role in the search.
Retrieval memory consists of external references such as CUDA, CUTLASS, and CuTe DSL documentation. This matters most on stacks that are new or evolving, where the relevant API, layout constraint, intrinsic, or hardware-specific behavior may be missing or outdated in pre-training. Retrieval memory helps the agent enter the valid search space by answering what APIs exist, what constraints apply, and why a compiler is rejecting the current attempt.
Optimization memory consists of reusable expert rules and code patterns drawn from examples, GitHub snippets, prior kernels, and curated knowledge. This is not API recall; it is heuristic guidance about which implementation family to search in. A concrete example: when targeting Blackwell with satisfied layout constraints, prefer a tcgen05.mma PTX instruction over older Hopper-style warp-group instructions. Optimization memory helps the agent move through the search space toward stronger implementation families.
Live notes are short evolving lessons accumulated during a run: errors and their fixes, optimization directions that helped or failed, and profiler observations. Notes are managed by multiple agents -- one runs experiments, one reflects, and one updates and merges the lessons. Live notes are the most local form of memory, helping the agent avoid cycling by preserving evidence generated by the current search.
Memory is a policy, not a database
Once the agent has access to documentation, examples, prior kernels, and live notes, the hard problem shifts from storage to memory management and retrieval. A useful memory system needs a policy that decides what to store, what to retrieve, how much context to allocate to memory, when to prefer search over retrieval, when to evict stale entries, and how to combine external knowledge with local compiler and profiler feedback.
This is where learned memory managers, reflective agents, and advancements such as recursive language models become relevant. They are not just larger databases; they are policies for allocating context under uncertainty. A memory item is valuable only if it has high marginal utility for the next search step:
The right memory snippet is the one that changes the next experiment step in a meaningful way, either to explore more diverse solutions, or to exploit a previously-discovered optimization.
Experimental setup
We test on an internal QoR benchmark of five CuTe DSL kernel generation problems. For each kernel, the target is a fixed speedup threshold over the TorchInductor Triton baseline. At each iteration, the agent proposes a candidate, checks correctness, benchmarks runtime, and produces the next candidate.
We compare five settings:
- Baseline: the task and past kernels from the current run.
- + Retrieval memory: baseline plus relevant CuTe/CUTLASS documentation.
- + Optimization memory: baseline plus reusable expert rules and code snippets.
- + Live notes: baseline plus compact summaries written during the run.
- Full-memory: combines all three under a fixed context budget.
We report three main metrics. Best performance by iteration, the best speedup found so far, is the headline. If memory is helping, this curve should rise earlier, not just end higher by chance. Iterations to target directly captures the cost: if extra context delays useful experiments, this number goes up. Repeat-failure rate tracks how often the agent revisits the same compile, correctness, or optimization failure.
Results
The most striking result in our ablation is not that more memory wins on best performance. It is that adding memory can make the agent slower to reach a target.
Optimization memory alone reaches the target in 3 iterations at 1.78×. Full memory reaches the same target in 5 iterations and converges at 1.85× the speed of TorchInductor. The full configuration buys a 4% improvement in best speedup at the cost of 67% more iterations.
| Memory setting · Iterations to target ↓ | Best perf @ fixed budget ↑ | | --- | --- | --- | | Baseline · 14 · 1.00x | | + Retrieval memory · 6 | 1.38x | | + Optimization memory · 3 | 1.78x | | + Live notes · 8 | 1.12x | | Full memory · 5 | 1.85x · Under a "memory = recall" view, this is paradoxical: full memory contains the information available to every other configuration, so it should dominate. Under a "memory = cache" view, it is exactly what we expect when capacity grows but per-iteration bandwidth, the prompt tokens each step actually gets, does not. Lower-utility items displace higher-utility ones. The agent has more information available and uses its budget worse.
The convergence curves below make the same point at finer granularity. Full memory and optimization memory track each other closely for the first few iterations and then diverge: optimization memory quickly reaches a strong solution, while full memory continues climbing more slowly before plateauing slightly higher. The marginal value of the extra context is real, but small, and only realized late.
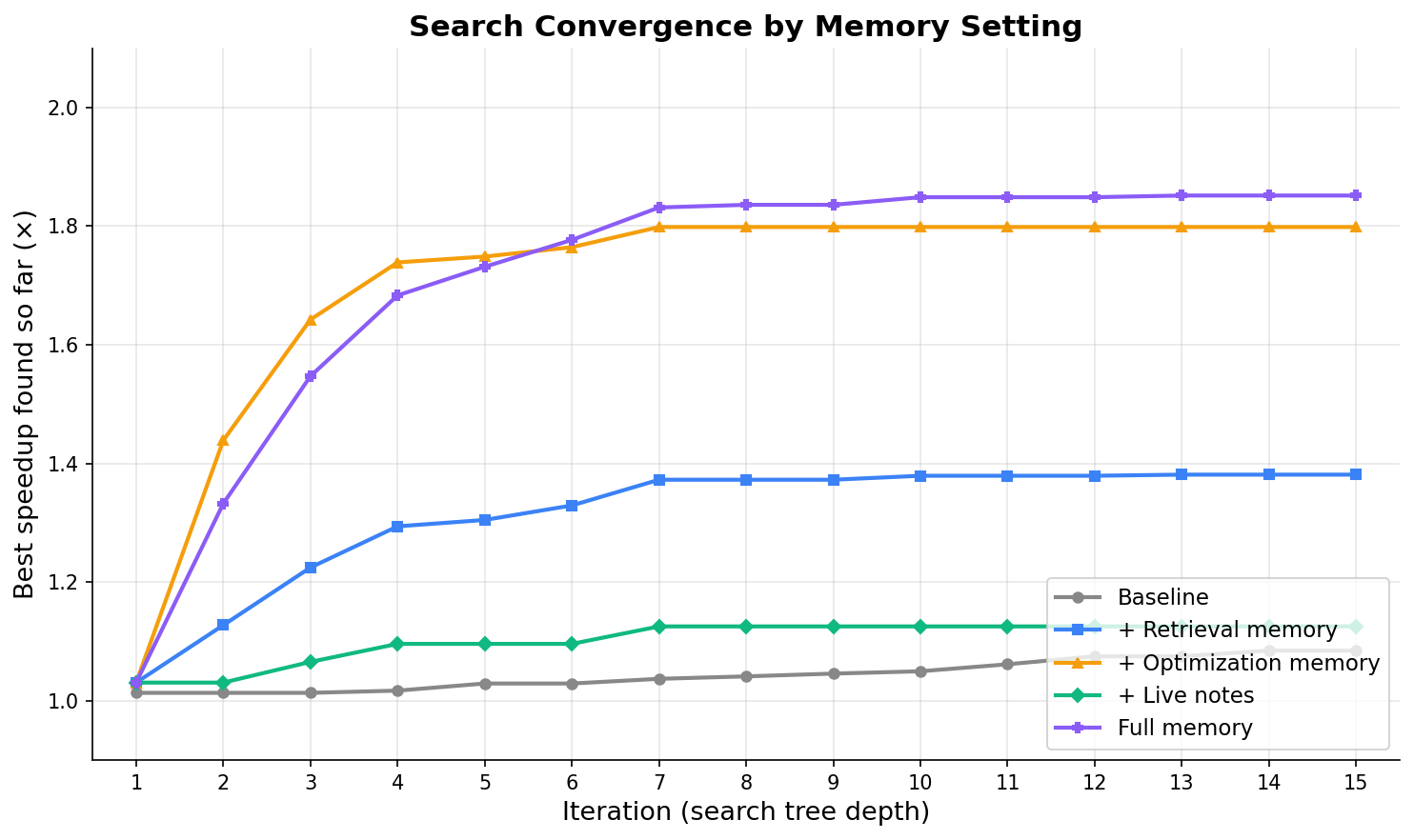
Read through the "cache" lens, the other configurations divide cleanly. Retrieval memory closes compulsory misses: it gives the agent constraints and API conventions it would otherwise have to discover by failing to compile or vastly underperforming a strong baseline. This is why it dominates on newer DSLs where LLM pre-training coverage is thin. Optimization memory closes capacity misses: the agent would eventually find the right implementation family by search, but it does not have iterations to spare. Live notes are the surprising entry. They are the most agentic source, written by the agent itself during the run, and they help the least. Two factors likely explain this. First, the evolutionary baseline already carries strong candidates and recent failures forward, so a substantial fraction of what notes preserve is already in the search state. Second, notes written during the search are noisy, and the writer-agent and retriever-agent do not always agree on what is worth recording. The current value of live notes appears closer to within-run summarization than to durable cross-run accumulation.
The combined-memory result is not a contradiction of the cache framing: under a fixed prompt size, naively concatenating all three sources displaces the current run information: the latest compiler error, the most recent profiler readout, the candidate currently being edited. This current run information is in many cases necessary to inform the next experiment.
Memory vs. Search
Following with the "cache" analogy, there should be a sweet spot in how much of the prompt is given to memory versus local evidence. Too little memory leaves the agent rediscovering the same constraints and failures; too much crowds out the per-iteration signal. A budget sweep -- fraction of the prompt allocated to memory on the x-axis, performance on the y-axis -- should produce a hump-shaped curve.
We measure this directly. Sweeping the memory fraction from 0% to 80%, both metrics show clean three-regime structure. Best speedup peaks near 40% memory allocation and falls off symmetrically on either side. Iterations to target reach a minimum across the 35-45% range and rise sharply outside it. Below ~15% the agent spends most of its budget rediscovering things memory could have provided. Above ~55% the prompt becomes saturated with low-utility items and effective bandwidth on local evidence collapses.
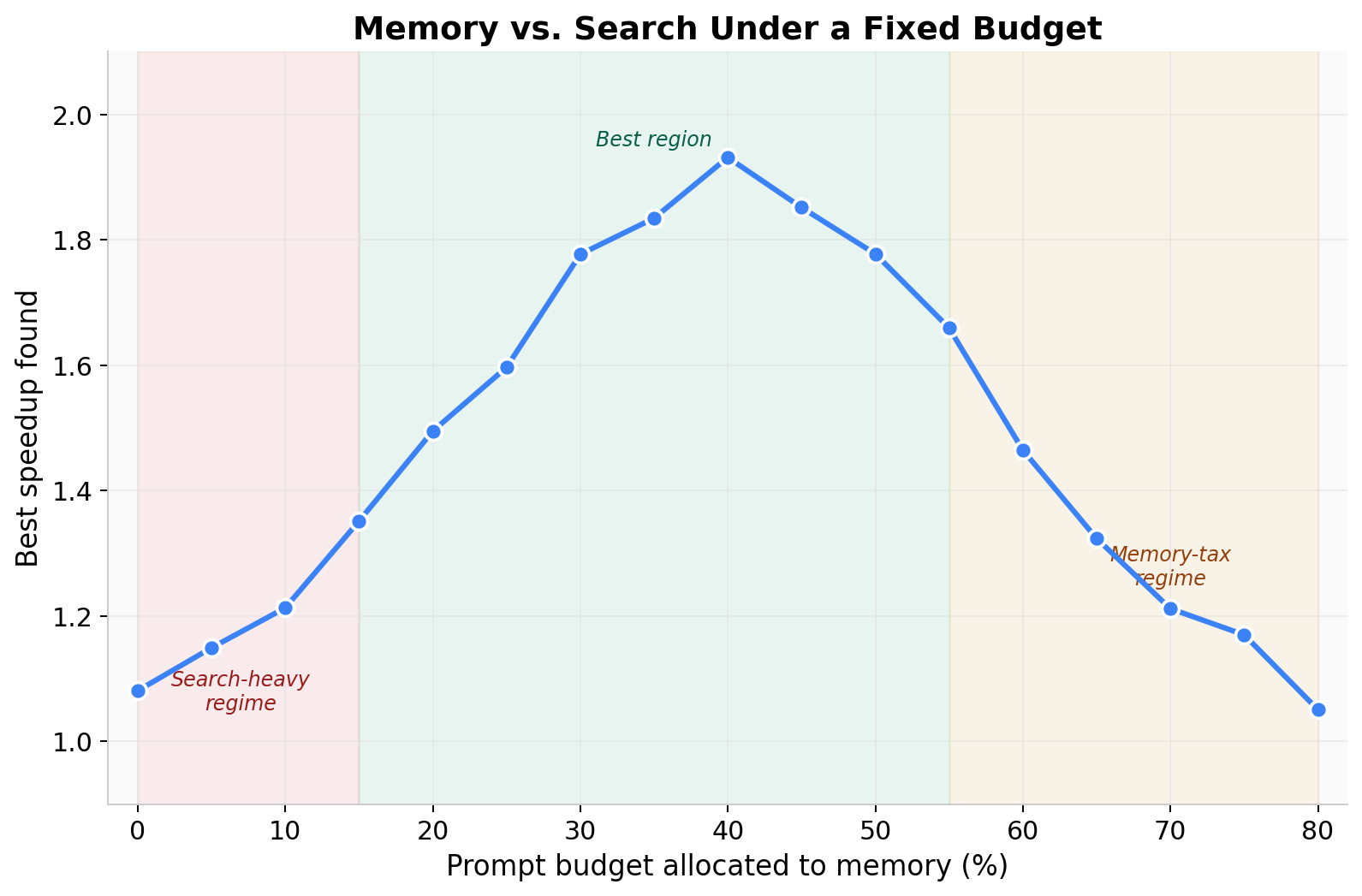
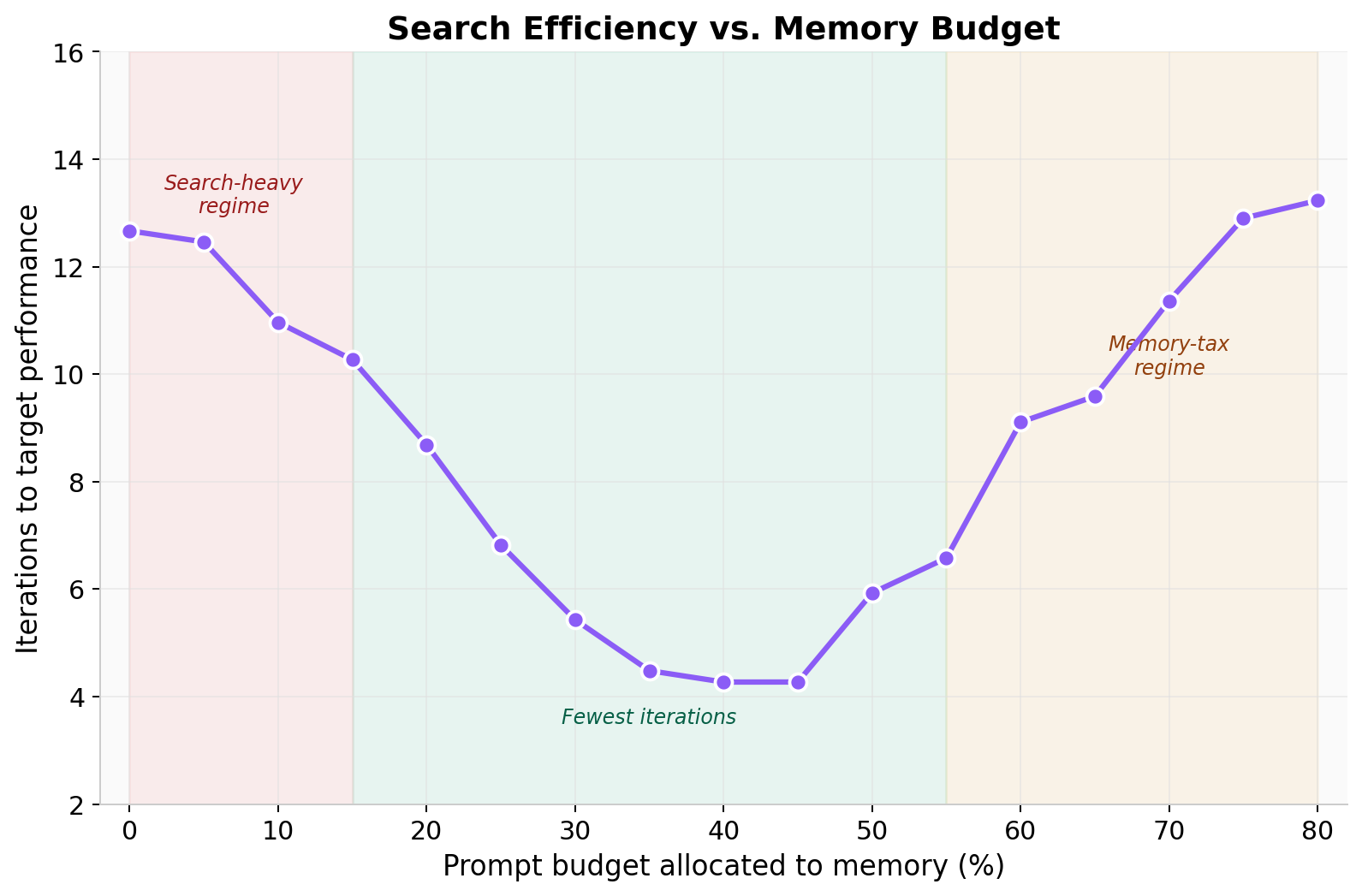
Two observations matter here. First, the existence of a memory-tax regime, where adding memory makes both metrics strictly worse, is empirically confirmed. Second, the operating point that minimizes iterations to target is not the same as the one that maximizes best speedup. The former optimizes search efficiency at a known threshold; the latter optimizes asymptotic quality. A practical agent has to choose, and that choice is downstream of what the user is paying compute for.
This sweep tells us how much memory belongs in the prompt. It says nothing about which items. Two configurations with the same memory budget can fill it very differently -- one with three optimization rules, one with five doc snippets, one with the latest live note plus the most relevant API reference. That is a separate problem, and it is the one we turn to next.
Memory selection policies under a fixed context budget
If pollution rather than capacity is the binding constraint, it is informative to try out different policies for how a fixed memory budget is allocated. We therefore run a second ablation, holding the per-iteration memory budget fixed at around 4K tokens and varying only the selection policy over the pooled three-source memory. This isolates the memory-management problem: given the same total context allocation, which items should be placed in the working set?
We compare five policies:
- Static proportional: allocates the budget evenly across retrieval memory, optimization memory, and live notes. This is the closest analog to the naive full-memory configuration and serves as the control.
- Relevance-ranked: pools all memory items, scores each by similarity to the current candidate code and most recent error, and fills the budget greedily.
- Iteration-aware: changes the source mix by iteration index: retrieval-heavy early to enter the search space, optimization-heavy mid-run to find stronger implementation families, and live-notes-heavy late to avoid cycling.
- Failure-conditioned: prioritizes items tagged for the most recent failure class, such as compile error, correctness failure, or performance regression. This is the "serve the miss that just happened" policy.
- Oracle judge: uses a small auxiliary LLM to score expected utility for the next iteration. This is an upper bound on what selection alone can achieve.
In addition to best performance and iterations to target, we report two cache-style diagnostics. Repeat failures measures how often the agent revisits the same failure class.
| Policy · Avg. best perf ↑ | Avg. iterations to target ↓ | Repeat failures over 5 runs ↓ | | --- | --- | --- | --- | | Static proportional · 1.85× | 5.0 · 12/40 | | Relevance-ranked · 1.88× | 4.0 · 9/40 | | Iteration-aware · 1.92× | 3.2 · 7/40 | | Failure-conditioned · 1.82× | 2.4 · 5/40 | | Oracle judge · 2.00× | 3.0 · 6/40 · We report repeat failures as absolute counts over the full 8-iteration budget. A repeat failure is an iteration whose failure class: compile error, correctness bug, or performance regression -- has already appeared earlier in the same run.
These results separate two notions of good memory: fast recovery and strong final optimization.
Failure-conditioned selection reaches the target fastest because it spends the memory budget on the most recent blocker. It is especially good at reducing repeated failures: when the agent just hit a compiler error, correctness bug, or performance regression, the policy retrieves memories that are directly tied to that failure class. This produces the lowest repeat-failure rate and the fastest threshold crossing. But the same reactivity makes it myopic. It is good at escaping the current hole, not necessarily at finding the best final kernel.
Relevance-ranked selection improves over static proportional selection, but only modestly. Similarity is useful, but it is not the same as utility. A memory can be lexically similar to the current candidate without changing the next experiment. This is exactly the distinction between retrieving something that looks relevant and retrieving something that is actually actionable.
Iteration-aware selection gives the best non-oracle tradeoff. It reaches the target in 3 iterations while achieving a higher fixed-budget speedup than the other practical policies. This supports the working-set hypothesis: the right cache contents shift as search progresses. Early iterations benefit from documentation and constraints, middle iterations benefit from optimization rules, and later iterations benefit from notes about what the current run has already tried.
The oracle judge shows the remaining headroom from better selection. It has the best final performance, but it does not reach the target faster than the iteration-aware policy. This is expected: the oracle is optimizing expected next-step utility and final quality, not necessarily the fastest path to get there.
Conclusion
In GPU kernel generation, memory is useful when the agent already has something relevant to retrieve, while search is useful when it does not. A strong kernel agent should alternate between the two: search to create knowledge, then accessing memory to avoid paying for the same discovery twice. The challenge is not building larger stores of past information, but deciding what is worth remembering, when it is worth retrieving, and when the agent should stop reading and go back to exploring. We demonstrated the tradeoffs between memory and search through five challenging kernel generation problems. In MakoraGenerate, we have quickly realized that managing knowledge sources, memory, and tool-calling is key to high-performance GPU kernel generation. And indeed, more is not always better, even for isolated kernel generation problems.
References
- Tehrani, Ali, Yahya Emara, Essam Wissam, Wojciech Paluch, Waleed Atallah, Łukasz Dudziak, and Mohamed S. Abdelfattah. 2026. Fine-Tuning GPT-5 for GPU Kernel Generation. arXiv preprint arXiv:2602.11000. https://arxiv.org/abs/2602.11000
- Baronio, Carlo, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti. 2025. Kevin: Multi-Turn RL for Generating CUDA Kernels. arXiv preprint arXiv:2507.11948. https://arxiv.org/abs/2507.11948
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to the UCB team via email: ucbskyadrs@gmail.com
💬 Join UCB on join.slack.com/t and Discord