LEVI: Better ADRS Results at a Fraction of the Cost

This post is part of our AI-Driven Research for Systems (ADRS) case study series, where we use AI to automatically discover better algorithms for real-world systems problems.
Algorithmic discovery frameworks like OpenEvolve and GEPA have shown that AI-Driven Research for Systems (ADRS) can produce strong algorithms. But today's frameworks are too expensive for where ADRS should go next. The future is in continuous and bespoke optimization, not one-off benchmark results. The system should generate solutions tailored to the deployment's exact workload, hardware, and SLOs; adapting as these change. This is not possible when every optimization costs a fortune.
LEVI is a framework built around lowering the cost of algorithmic discovery. Instead of using the strongest, most expensive models for every step, it invests in the search harness: smaller, cheaper models (e.g. QWEN 30B) do most mutations, while larger models are reserved for rarer paradigm shifts. This is made possible because LEVI maintains diversity across both code structure (e.g. number of loops) and actual behavior (e.g. performance on subset x), ensuring the search archive does not collapse into a single solution family.
The result is a framework that gets stronger ADRS results at a fraction of the cost: roughly 3–7× cheaper than baselines in the main benchmark comparison.
- ✍️ Previous ADRS Blogs: https://ucbskyadrs.github.io/
- 👩💻 Code: github.com/ttanv/levi
- 💬 Join us: join.slack.com/t/adrs-global and Discord
- 🌎 Follow us: x.com/ai4research_ucb
LLM algorithmic discovery frameworks have shown promise in delivering strong results for ADRS. However, a key bottleneck remains: cost. This blog argues why cost plays an important role in ADRS, and then introduces LEVI; an algorithmic discovery framework that outperforms others at a fraction of the cost.
Existing frameworks require using expensive and large closed-source LLMs. This is problematic for obvious reasons. For example, it raises the barrier of entry since most researchers can't afford such experiments. But the more important issue is broader: ADRS should not be viewed as something we run once to produce a single strong result.
Let the Barbarians Spread?
Decreasing the cost until it is orders of magnitude less should be the natural next step for ADRS. This is because the results from ADRS should not be treated as one-off research outcomes similar to how usual systems papers look like. Where for a given problem, researchers improve upon algorithms and heuristics to yield better results. Where industry then follows along by porting these algorithms and adapting them to their setup.
Instead we should move towards completely bespoke solutions. Where each solution is tailored to the exact setup and environment that each deployment has, squeezing out the most juice.
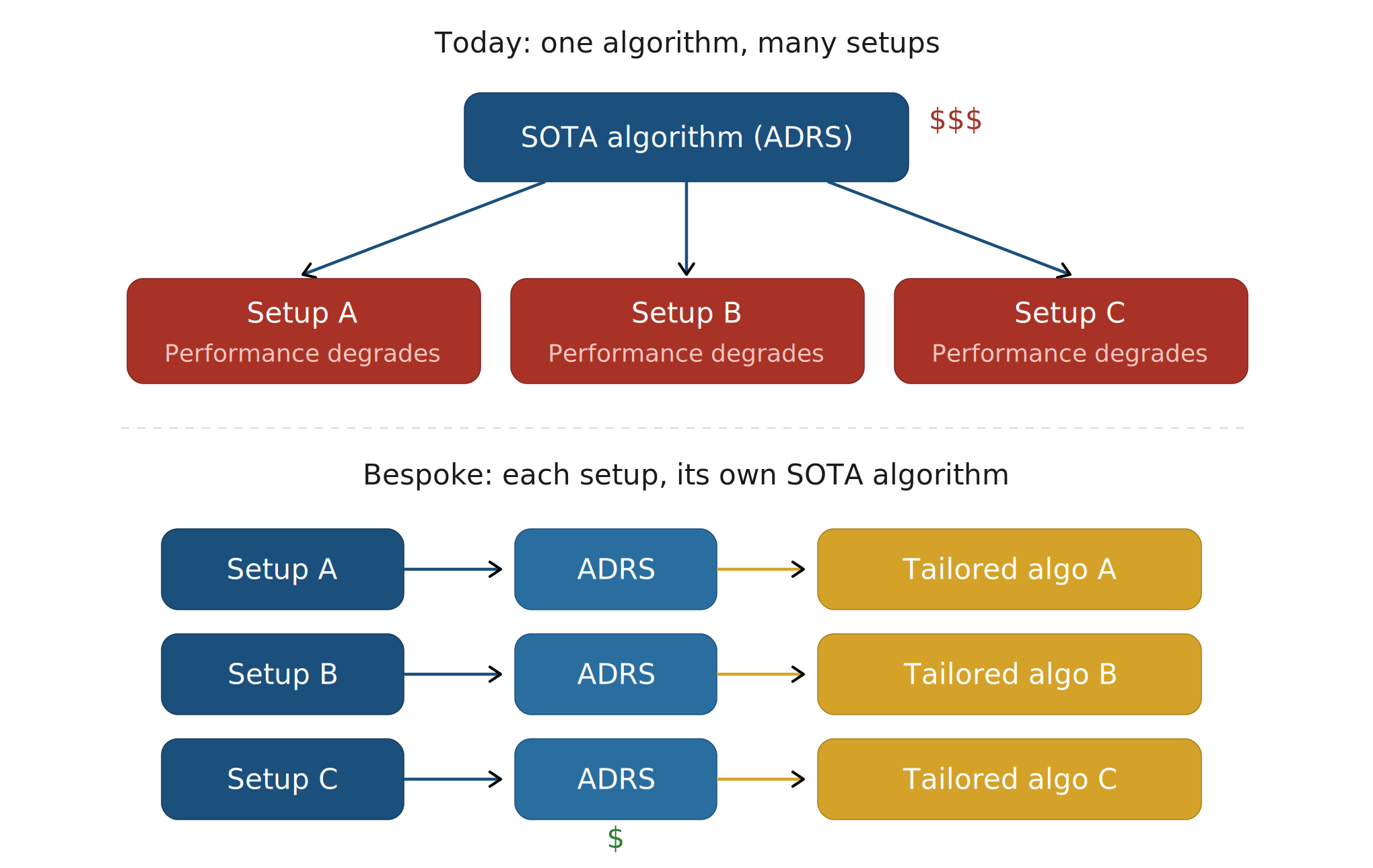
Taken to its logical conclusion, ADRS should be seen as a more sophisticated form of CI/CD. Where the user defines their scoring function and the deployment setup, and instead of just linters or formatters automatically fixing the style and formatting, the algorithm itself is automatically optimized. As the resources (e.g. new GPUs) or priorities change (different SLOs), the corresponding algorithms are automatically optimized. An enterprise running a multi-region cloud scheduler today uses the same algorithm as everyone else. With cheaper ADRS, they could re-optimize nightly against their actual traffic patterns, their actual SLOs, their actual hardware mix.
Introducing LEVI: LLM-Based Optimization at a Fraction of the Cost
Given the above, this blog introduces LEVI: an LLM-based evolutionary framework that produces SOTA performances on ADRS problems at a fraction of the cost. It is built on the key insight that too many frameworks assume access to the largest SOTA models, and build their harnesses around them.
Key Insight: Invest in the Harness instead of the Model
Assuming access to the largest models should not be the default. In fact, the original FunSearch paper reported being unable to benefit from larger models, and only with AlphaEvolve did they succeed. The open-source community often misses this, throwing the strongest models at every step. LEVI proceeds to take a harness first approach instead, through two key components: stratified model allocation and improved diversity maintenance.
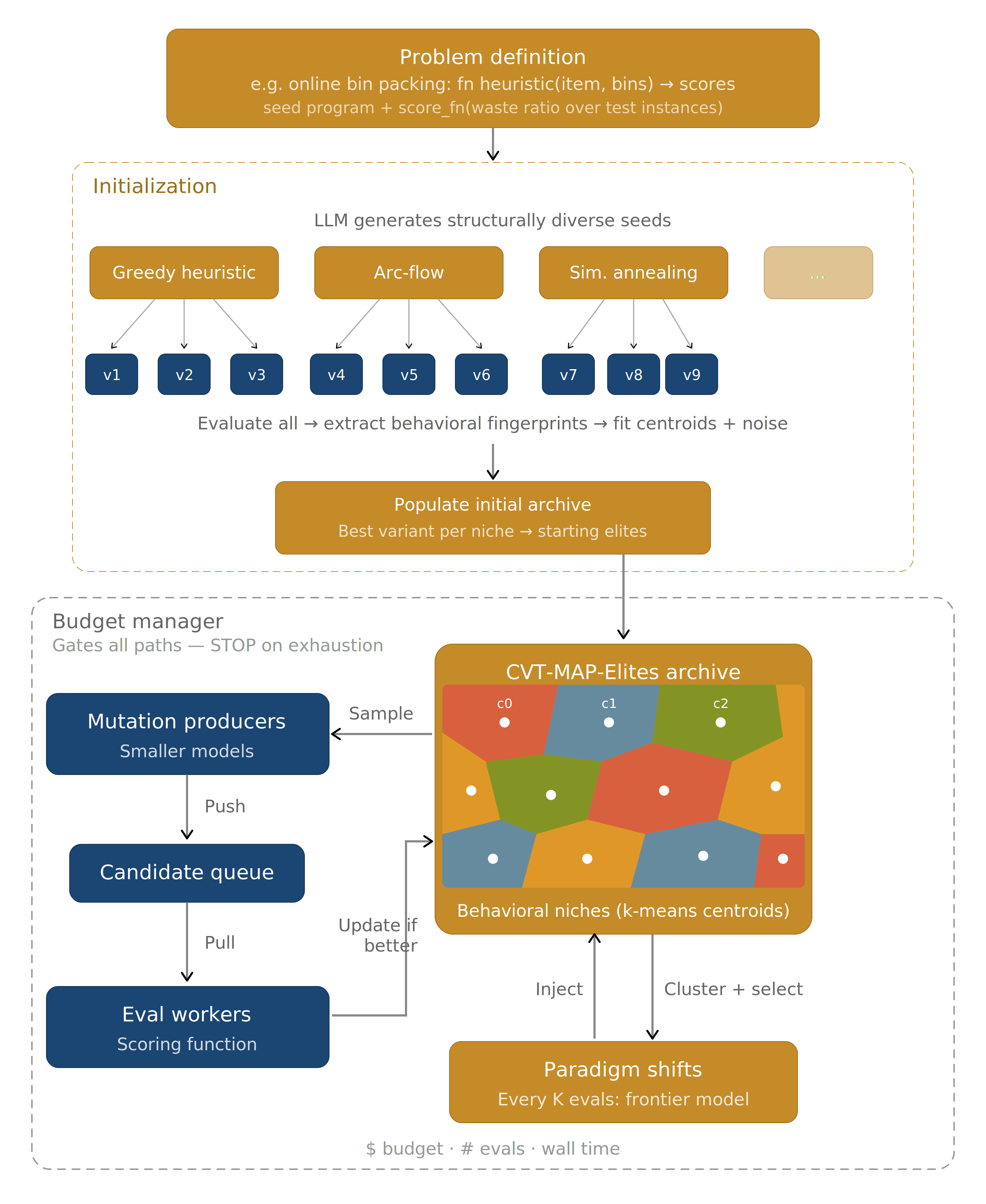
Stratified Model Allocation
Frontier models help, but they are a waste if used for every mutation. Smaller LLMs may actually be preferred under tight budgets, since the sheer quantity of solutions they produce can outweigh the quality advantage of larger models. However, smaller models have a narrower pretraining distribution, limiting their range of ideas and ability to propose fundamentally different approaches. Neither model class is strictly better; they just have different strengths.
Some existing frameworks already support multiple models, but treat them as interchangeable, sampling from an ensemble uniformly or routing calls without regard to what the mutation actually demands. This ignores a natural asymmetry: proposing an entirely new algorithmic direction requires broad knowledge and creative reasoning, while refining an existing approach (adjusting constants, reordering operations, tuning edge cases) requires far less. The harness should be aware of this distinction and allocate accordingly.
LEVI introduces stratified model allocation, which matches model capacity to task demand. Smaller, cheaper models handle the majority of the search: local refinements and incremental improvements within an established algorithmic family. Larger models are reserved for infrequent paradigm shifts: mutations that aim to propose structurally different approaches rather than polish existing ones. The principle is straightforward: allocate each model toward its strength. Small models for breadth and throughput, large models for creative leaps.
However, this raises two questions. First, how do we select representative solutions from each algorithmic family to give the larger model meaningful context for paradigm shifts? Second, since we now rely more heavily on smaller models and their volume of output, we need a more robust mechanism to prevent the archive from converging.
LEVI matches model capacity to task demand: cheap models (e.g. a local QWEN 30B) for refinement, expensive models for paradigm shifts.
Improved Diversity Maintenance
Unifying Structural and Behavioral Diversity. A less obvious reason existing frameworks require frontier models is that those models are doing double duty. Their larger output space implicitly maintains diversity: a GPT-5 or Claude Opus naturally produces a wider spread of solutions than a 30B model, ignoring the fact that the archive itself has no strong mechanism to prevent convergence. When diversity does collapse, the response has been to add complexity on top: ranging from rejection sampling using even more LLM calls to using embedding models. These are compensations for a weak foundation, not solutions to the underlying issue.
The underlying issue is that existing frameworks maintain diversity along only one axis, and a narrow one at that. OpenEvolve considers structural features like code length; GEPA considers per-instance performance trade-offs through Pareto fronts (in practice often more powerful than the former mechanism). Both capture something real, but neither captures the full picture. Structure alone misses behavioral differences: two programs with different loop counts might solve the problem identically. And per-instance scores alone miss solutions that perform similarly on individual instances but work in fundamentally different ways.
Rather than choosing one axis, LEVI uses both as dimensions of a single behavioral descriptor. Each solution is mapped to a fingerprint: a vector combining code-structural features (going beyond simple dimensions like code length to measures such as loop count, cyclomatic complexity) alongside per-instance behavioral results, all normalized and projected to [0, 1]. The framework is also flexible here: users can define their own dimensions when the defaults do not fit their problem.
This fingerprint lives in a CVT-MAP-Elites archive, where a Voronoi tessellation over the combined space maintains geometric structure that neither axis provides alone. The archive holds a diverse set of solutions with different values along the different dimensions. This also directly answers the first question from the previous section: the Voronoi regions naturally cluster solutions into algorithmic families, giving us representative solutions for paradigm shifts.
Archive Initializing. Traditional CVT-MAP-Elites initializes centroids uniformly across the descriptor space. With the higher dimensionality we use (6 to 10 dims), this leads to an extremely sparse tessellation where most regions will never be visited. LEVI adopts a data-driven approach; it creates a set of deliberately unique approaches (regardless of scores) through sequential generation, and then uses those to create the initial centroids. This ensures that the archive is based on solutions that are known to be different.
LEVI maintains diversity through a shared fingerprint space over both structure and behavior, so the archive itself carries more of the diversity burden instead of relying as heavily on ever-stronger models or auxiliary heuristics.
Getting Started with LEVI (Python API)
Below is an example LEVI program, optimizing a dummy bin packing problem. All of the framework details are abstracted away, and the user can focus on defining the problem.
import levi
def score_fn(pack):
bins = pack([4, 8, 1, 4, 2, 1], 10)
wasted = sum(10 - sum(b) for b in bins)
return {"score": max(0.0, 100.0 - wasted)}
result = levi.evolve_code(
"Optimize bin packing to minimize wasted space",
function_signature="def pack(items, bin_capacity):",
score_fn=score_fn,
model="openai/gpt-4o-mini",
budget_dollars=2.0,
)
Try out LEVI yourself at: github.com/ttanv/levi!
ADRS Benchmark Results
LEVI achieves the highest score on every problem where improvement is possible, with an average of 76.5 compared to 71.9 for the next-best framework (GEPA), a +4.6 point improvement over the prior state of the art. On Cloudcast, LEVI reaches a perfect 100.0, indicating the problem is fully solved under the benchmark's scoring function. The largest gains appear on LLM-SQL (+5.8) and Spot Multi (+5.7), while more modest improvements on Spot Single (+0.3) and Transaction Scheduling (+1.1) reflect problems with smaller decision spaces or harder optimization landscapes. Prism remains tied at 87.4 across all frameworks, confirming that the current problem formulation admits a single dominant solution.
| Framework | Avg | Cloudcast | EPLB | LLM-SQL | Prism | Spot Multi-Reg | Spot Single-Reg | Txn Sched |
|---|---|---|---|---|---|---|---|---|
| GEPA | 71.9 | 96.6 | 70.2 | 67.7 | 87.4 | 62.2 | 51.4 | 67.7 |
| OpenEvolve | 70.6 | 92.9 | 62.0 | 72.5 | 87.4 | 66.7 | 42.5 | 70.0 |
| ShinkaEvolve | 67.4 | 72.0 | 66.4 | 68.5 | 87.4 | 63.6 | 45.6 | 68.2 |
| LEVI | 76.5 | 100.0 | 74.6 | 78.3 | 87.4 | 72.4 | 51.7 | 71.1 |
Cost
.png)
LEVI's stratified allocation is the primary driver of cost reduction. By routing the majority of mutations through lightweight models, the per-generation cost drops by roughly an order of magnitude compared to baselines that use GPT-5 or Gemini-3.0-Pro for every call. This allows LEVI to run substantially more generations while still spending less in total: $4.50 per problem on most tasks (Transaction Scheduling: $13), versus $15 to $30 for baselines.
The cost reduction is evidence that the harness-first approach works. When the archive maintains diversity, cheap models suffice for most of the search.
Controlled Architecture Comparison
Same model, same budget, three seeds: isolating the search architecture's contribution.
The main results compare frameworks that differ simultaneously in model choice, budget, and architecture. To isolate the contribution of the search architecture, we run LEVI, OpenEvolve, and GEPA under identical conditions: a single locally-served Qwen3-30B-A3B model, 750 successful evaluations and three random seeds on two representative problems. OpenEvolve required reducing parent count from 5 to 2 for the smaller model and still produced many failures. We report successful evaluations rather than total to give OpenEvolve a fair comparison.
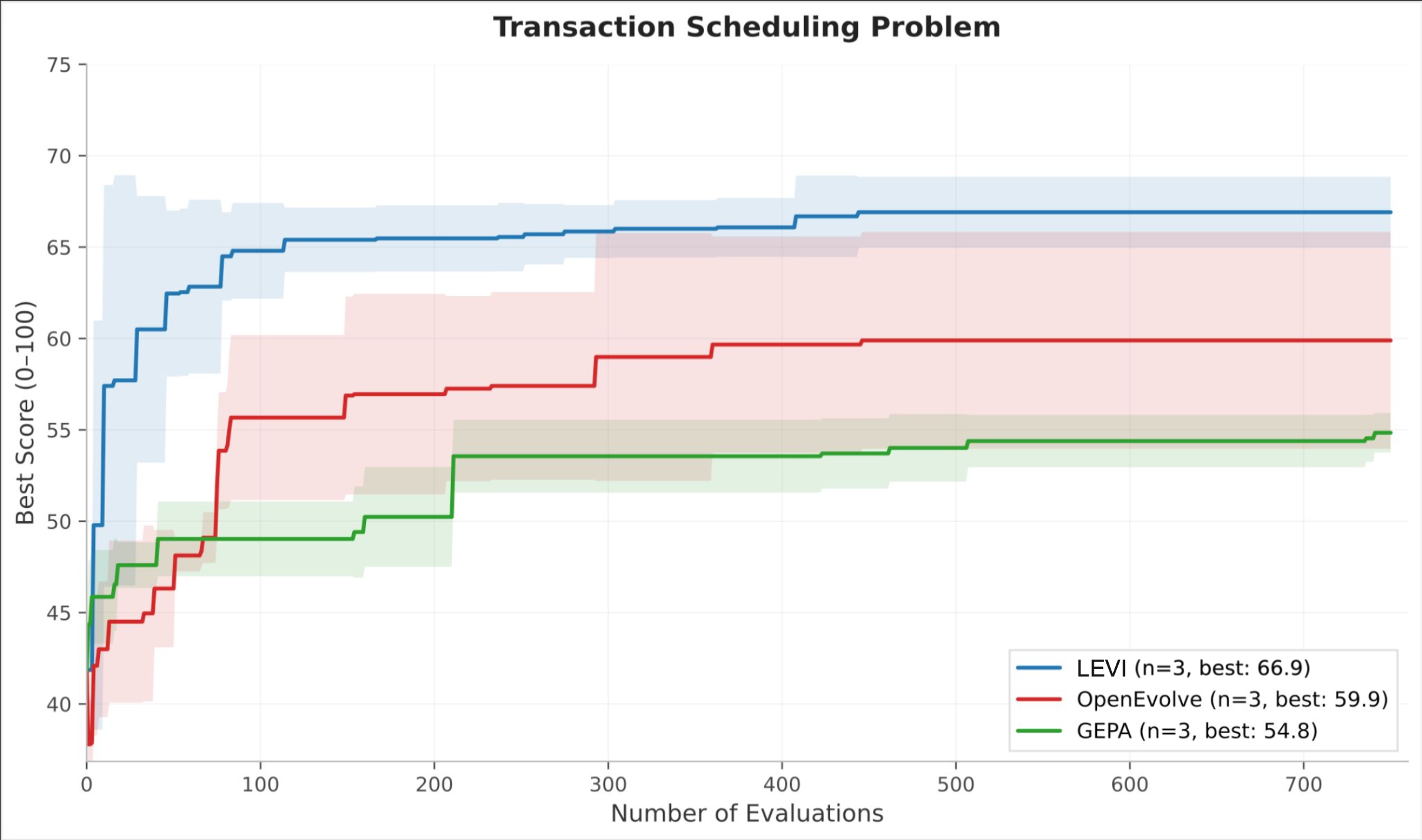
Transaction Scheduling is a variant of an NP-hard ordering problem where multiple algorithmic families (greedy, simulated annealing, genetic) are viable but performance is measured on a single instance, giving Pareto-based diversity no trade-off to exploit. LEVI reaches a score of 62 within the first 100 evaluations, a level neither baseline achieves at any point. Final scores: LEVI 64.9, OpenEvolve 59.9, GEPA 54.4. Both baselines plateau sharply, consistent with early convergence onto a single algorithmic family; LEVI's curve continues rising past evaluation 500.
Can't Be Late is scored across 1,080 simulations that give Pareto-based approaches a richer signal. The final-score gap narrows (LEVI 44.9, OpenEvolve 43.2, GEPA 37.5), but the efficiency gap widens dramatically. LEVI reaches near-peak performance by roughly evaluation 50, while OpenEvolve requires over 600 evaluations to approach the same level, a roughly 12× advantage in sample efficiency.
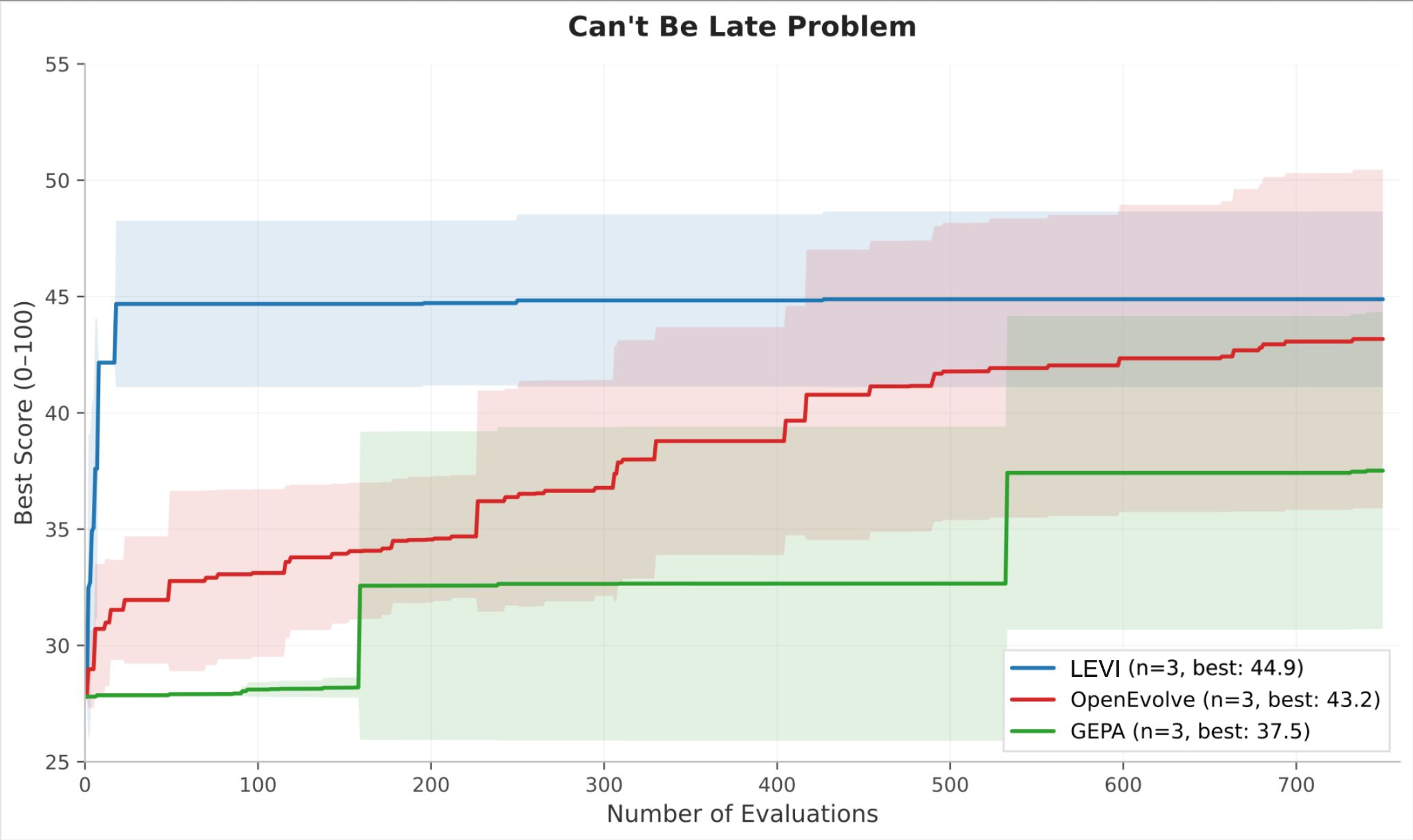
These controlled results confirm that the performance gains are attributable to the search architecture, not to model choice or budget. A 30B model under LEVI's search regime matches or exceeds what the same model achieves under alternative selection mechanisms.
Lessons and Looking Forward
Working with smaller models surfaces real tradeoffs that frameworks built around frontier models never have to confront:
- Higher error rates, but cheaper retries. Smaller models produce broken code more often, but the calls are so cheap that you can afford many more attempts and still come out ahead on total spend.
- Reward hacking. Smaller models are more susceptible to exploiting evaluator weaknesses rather than genuinely solving the problem. But this is an evaluator problem as much as a model problem, and fixing evaluators benefits every framework.
- Code over text. When expressing a useful idea for a smaller model to work with, code beats natural language. A prompt saying "try simulated annealing" leaves enormous room for interpretation; a code skeleton implementing the acceptance criterion and cooling schedule gives the model something concrete. This is why LEVI's paradigm shift step generates code skeletons rather than text suggestions.
- Quantity vs. eval time. The core advantage of smaller models is volume: as shown above, more cheap calls can outperform fewer expensive ones. But this advantage depends on evaluations being fast. For problems where a single eval takes an hour, every call is precious and larger models become more sensible. LEVI mitigates this for most problems through an async distributed producer-consumer model, but for long-eval domains this is a different dimension of tradeoff worth considering.
These are not LEVI-specific findings. They apply to anyone building evolutionary frameworks that aim to work beyond a single frontier model. As the field moves toward making ADRS accessible and continuous, the harness has to compensate for what cheaper models lack. LEVI's results suggest this is not only feasible but preferable: invest in the search architecture, maintain diversity properly, and the model becomes a commodity input rather than the bottleneck. With decreased costs, nightly re-optimization against real production workloads starts being practical.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t/adrs-global and Discord
🗞️ Follow us: x.com/ai4research_ucb