How Do LLM Agents Think Through SQL Join Orders?
This blog is part of a research collaboration with Databricks. In a prior Databricks blog, we discussed how LLMs are highly effective at iteratively optimizing SQL join orderings. This blog is a followup exploring the details of the LLM thinking process.
- ✍️ Previous ADRS Blogs: https://ucbskyadrs.github.io/
- 💬 Join us: join.slack.com/t/adrs-global and Discord
- Follow us: Twitter and LinkedIn
Problem Statement
Since relational databases were first introduced, automated query optimizers and practitioners have struggled to find good join orderings for SQL queries. In the earlier blog we explored the ability of LLMs to optimize the join order of SQL queries, which can be thought of as a form of ADRS optimization against the SQL DSL instead of a full programmatic language. In that blog we showed that LLMs had promising performance for join ordering compared to state of the art approaches.
In this posting, we dive deeper into the problem and explore the question of how LLMs are doing so well. While the ability of frontier models to reach state of the art results in domains such as this is no longer surprising, what is still interesting is the "thought process" of how LLMs are achieving these results. For example, one could ask:
- Are the LLMs exploiting domain knowledge?
- Are the LLMs executing a form of guided search?
- Are the LLMs overfitting based on prior training data?
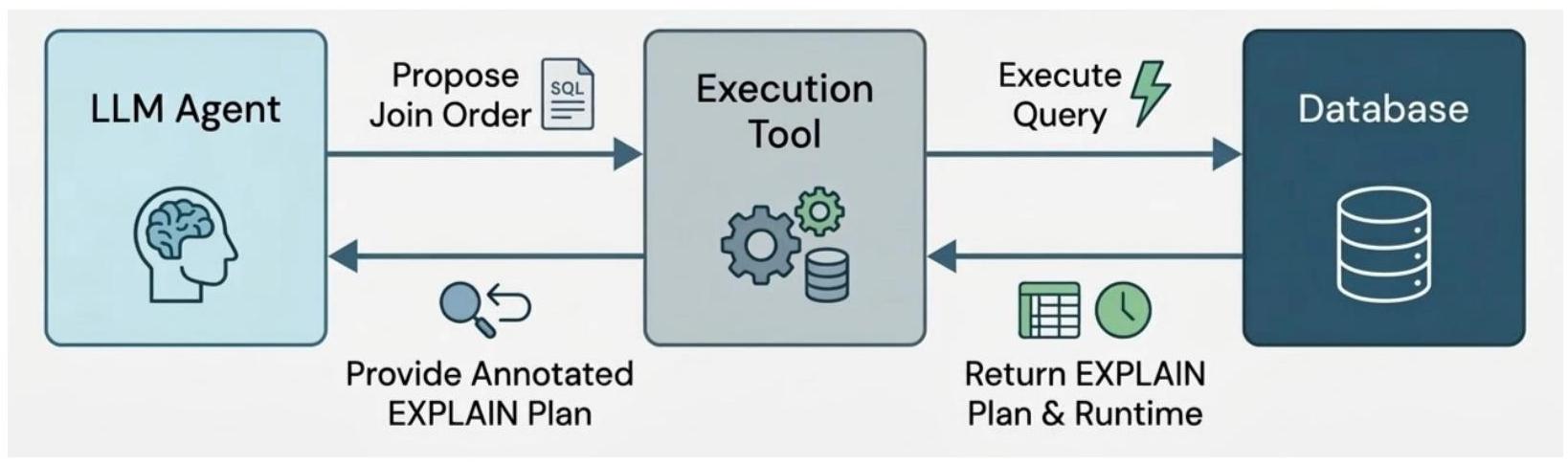
To answer these questions for this ADRS problem, we dug into the thinking traces from a sweep of the join order benchmark using the prototype LLM join order agent we built before. The prototype agent runs in a loop that (1) proposes a new join order, (2) executes the query using the given join order, (3) analyzes post-execution statistics of the proposed plan, and (4) repeats until the iteration limit is reached.
JOB benchmark recap
To recap the results from the previous blog, we observed that on a scaled up join order benchmark (JOB), the prototype agent could achieve significantly better wall-clock results compared to the default join order, perfect cardinality estimates, as well as state of the art ML search techniques:
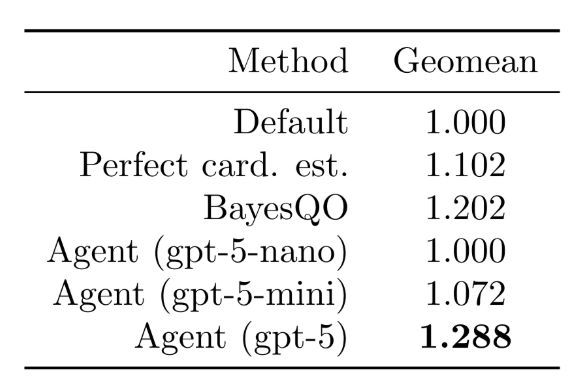
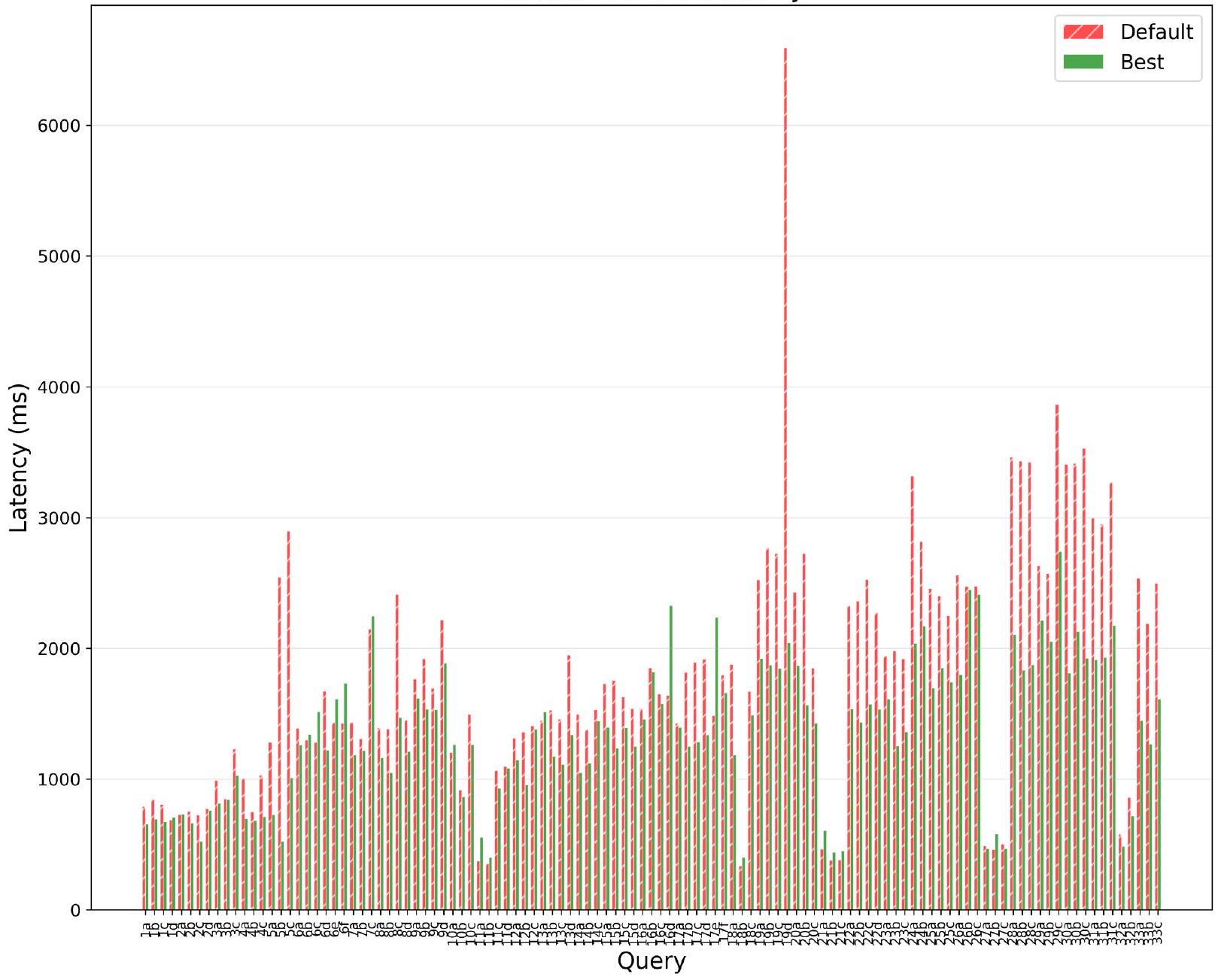
These results (as with the results for BayesQO) require the agent to iteratively execute queries, receive feedback (e.g., post-execution stats from EXPLAIN ANALYZE), and reason about join orders to try in subsequent iterations. Over 10-20 iterations, the agent searches through promising join orders and is able to outperform the default plan in (80%) of the cases:
Case Studies: LLM Reasoning and Strategies
We examine three representative queries that illustrate different facets of the LLM's optimization behavior. To aid in analysis, we forced the LLM to self-report reasoning for each join decision, and we summarize the reasoning decisions below:
Case 1: Query 5b - Discovering the Right Anchor Table (+79% speedup)
| Default | LLM Opt | |
|---|---|---|
| Verified (ms) | 2,543 | 524 |
SELECT MIN(t.title) AS american_vhs_movie
FROM company_type AS ct,
info_type AS it,
movie_companies AS mc,
movie_info AS mi,
title AS t
WHERE ct.kind = 'production companies'
AND mc.note LIKE '%(VHS)%'
AND mc.note LIKE '%(USA)%'
AND mc.note LIKE '%(1994)%'
AND mi.info IN ('USA',
'America')
AND t.production_year > 2010
AND t.id = mi.movie_id
AND t.id = mc.movie_id
AND mc.movie_id = mi.movie_id
AND ct.id = mc.company_type_id
AND it.id = mi.info_type_id;
Query: 5-table join (movie_companies, movie_info, title, company_type, info_type) filtering for American VHS movies from production companies.
What happened: The default optimizer drives the plan from movie_info (mi), which has a highly selective info IN ('USA', 'America') filter producing ~12 rows. On paper this seems optimal, but the LLM's very first rollout tried a completely different approach - starting from movie_companies (mc) with its note filters (LIKE '%VHS%' AND '%USA%' AND '%1994%') - and immediately achieved 655ms vs. the default's 2,543ms.
LLM's reasoning: The LLM explicitly noted that it wanted to "explore a plan that drives the join from movie_companies rather than movie_info, to learn relative selectivity of the mc.note + ct.kind predicates vs mi.info." After several rollouts exploring both mc-first and mi-first orderings, it concluded: "All mi-first trees are ~1.0-1.5s, largely because the optimizer treats (mi⋈it) as a big branch and ends up doing expensive shuffled joins."
Key insight: Starting from the table with the most selective composite filter can dramatically outperform starting from the table with the most selective single predicate. The LLM discovered this empirically and articulated the reasoning clearly.
Case 2: Query 19d - Cluster-Based Reasoning on Complex Queries (+69% speedup)
| Default | LLM Opt | |
|---|---|---|
| Verified (ms) | 6,590 | 2,044 |
SELECT MIN(n.name) AS voicing_actress,
MIN(t.title) AS jap_engl_voiced_movie
FROM aka_name AS an,
char_name AS chn,
cast_info AS ci,
company_name AS cn,
info_type AS it,
movie_companies AS mc,
movie_info AS mi,
name AS n,
role_type AS rt,
title AS t
WHERE ci.note IN ('(voice)',
'(voice: Japanese version)',
'(voice) (uncredited)',
'(voice: English version)')
AND cn.country_code ='[us]'
AND it.info = 'release dates'
AND n.gender ='f'
AND rt.role ='actress'
AND t.production_year > 2000
AND t.id = mi.movie_id
AND t.id = mc.movie_id
AND t.id = ci.movie_id
AND mc.movie_id = ci.movie_id
AND mc.movie_id = mi.movie_id
AND mi.movie_id = ci.movie_id
AND cn.id = mc.company_id
AND it.id = mi.info_type_id
AND n.id = ci.person_id
AND rt.id = ci.role_id
AND n.id = an.person_id
AND ci.person_id = an.person_id
AND chn.id = ci.person_role_id;
Query: 10-table join involving cast_info, name, aka_name, char_name, movie_info, movie_companies, company_name, title, info_type, and role_type - searching for female voice actresses in Japanese/English-voiced movies by US companies.
What happened: The LLM decomposed the 10-table join graph into three logical clusters and reasoned about their optimal ordering:
1. People cluster P = ((((ci ⋈ rt) ⋈ n) ⋈ an) ⋈ chn) — anchored on cast_info's
extremely selective note predicate (142 rows from 36M), filtered by role='actress'
and gender='f'
2. Movie cluster M = ((mi ⋈ it) ⋈ t) — release dates + title with year filter
3. Company cluster C = (mc ⋈ cn) — US companies
The LLM's first rollout used the ordering (P ⋈ M) ⋈ C and achieved 2,055ms. Over 13 rollouts, it explored 8 distinct structural variants (reordering tables within clusters, swapping cluster join order, etc.) and converged on the same structure as the best plan, improving slightly to 1,936ms.
LLM's reasoning: "Anchor on the most selective fact table and apply all person-side filters early… The key winning traits are: start from cast_info and don't touch movie_info until the end. Early joins to an and chn let the engine derive runtime filters (hashedrelationcontains) from the tiny people cluster."
Key insight: For complex multi-table queries, the LLM exhibits a structured decomposition strategy - grouping tables into semantic clusters and reasoning about their relative selectivity. This mirrors how expert DBAs approach query tuning.
Case 3: Query 28b - Iterative Refinement Finds Non-Obvious Ordering (+46% speedup)
| Default | LLM Opt | Ablation | |
|---|---|---|---|
| Verified (ms) | 3,431 | 1,832 | 3,348 |
SELECT MIN(cn.name) AS movie_company,
MIN(mi_idx.info) AS rating,
MIN(t.title) AS complete_euro_dark_movie
FROM complete_cast AS cc,
comp_cast_type AS cct1,
comp_cast_type AS cct2,
company_name AS cn,
company_type AS ct,
info_type AS it1,
info_type AS it2,
keyword AS k,
kind_type AS kt,
movie_companies AS mc,
movie_info AS mi,
movie_info_idx AS mi_idx,
movie_keyword AS mk,
title AS t
WHERE cct1.kind = 'crew'
AND cct2.kind != 'complete+verified'
AND cn.country_code != '[us]'
AND it1.info = 'countries'
AND it2.info = 'rating'
AND k.keyword IN ('murder',
'murder-in-title',
'blood',
'violence')
AND kt.kind IN ('movie',
'episode')
AND mc.note NOT LIKE '%(USA)%'
AND mc.note LIKE '%(200%)%'
AND mi.info IN ('Sweden',
'Germany',
'Swedish',
'German')
AND mi_idx.info > '6.5'
AND t.production_year > 2005
AND kt.id = t.kind_id
AND t.id = mi.movie_id
AND t.id = mk.movie_id
AND t.id = mi_idx.movie_id
AND t.id = mc.movie_id
AND t.id = cc.movie_id
AND mk.movie_id = mi.movie_id
AND mk.movie_id = mi_idx.movie_id
AND mk.movie_id = mc.movie_id
AND mk.movie_id = cc.movie_id
AND mi.movie_id = mi_idx.movie_id
AND mi.movie_id = mc.movie_id
AND mi.movie_id = cc.movie_id
AND mc.movie_id = mi_idx.movie_id
AND mc.movie_id = cc.movie_id
AND mi_idx.movie_id = cc.movie_id
AND k.id = mk.keyword_id
AND it1.id = mi.info_type_id
AND it2.id = mi_idx.info_type_id
AND ct.id = mc.company_type_id
AND cn.id = mc.company_id
AND cct1.id = cc.subject_id
AND cct2.id = cc.status_id;
Query: 14-table join - the most complex query type in the benchmark - involving movie metadata, keywords, ratings, companies, and cast completeness, filtering for European dark/violent movies with high ratings.
What happened: This case shows the value of continued exploration. The LLM's improvement trajectory over 15 rollouts:
| Rollout | Best Plan Found | Latency | Key Change |
|---|---|---|---|
| 1 | Core → companies → cast | 2,043ms | Initial: selective predicates first |
| 3 | Core → cast → companies | 1,921ms | Moved cast before companies |
| 7 | Core + cast early → keywords/ratings → companies | 1,708ms | Interleaved cast into the core |
| 11 | Flipped core ordering (t⋈kt before mi⋈it1) | 1,691ms | Fine-tuned within-core order |
The LLM methodically tested structural hypotheses:
- Rollout 3: "Keeping the core from plan #1 but swapping the order in which we attach cast vs companies" → discovered that filtering by cast completeness early helps prune movie_ids before hitting the large keyword/rating tables.
- Rollout 7: "Moving the cast branch (cc ⋈ cct1 ⋈ cct2) inside the core… because the cast-status filter helped prune the candidate movies before touching movie_keyword and movie_info_idx" → a 12% improvement over the prior best.
- Rollout 11: Simply flipping (mi ⋈ it1) ⋈ (t ⋈ kt) to (t ⋈ kt) ⋈ (mi ⋈ it1) yielded another ~1% improvement.
Key insight: On complex queries, the LLM performs systematic A/B testing of structural hypotheses, documenting what worked and why. The best plan was found at rollout 11 underscoring that even late rollouts can yield meaningful improvements on hard queries.
LLM reasoning strategies
The full set of observed reasoning strategies is listed in the below table.
| Strategy | Description | Example |
|---|---|---|
| Anchor selection | Start from the table with the most selective predicates | 5b: mc with note filters, 19d: ci with note predicate |
| Cluster decomposition | Group tables into semantic clusters and reason about their ordering | 19d: people/movie/company clusters |
| Iterative hypothesis testing | Systematically vary one structural element at a time | 28b: 11 rollouts to find optimal cast placement |
| Bushy plan construction | Build independent sub-branches and intersect them | 17e: (k⋈mk) and (cn⋈mc) intersected early |
| Convergence and exploitation | Recognize when to stop exploring and reuse the best plan | All queries: later rollouts often reuse the best plan |
| Reasoning accumulation | Reference prior rollout results to justify decisions | All queries: explicit notes like "History #1 was best because…" |
Conclusion
Overall, we found that the LLM prototype agent was able to outperform thanks to a reasoning-informed search process, which is much closer to a hypothesis validation process than a purely algorithmic tree search. As models continue to improve, we believe that LLMs will increasingly play a role in systems research due to their efficiency and performance compared to both heuristic and classic ML techniques.
Yuhao Zhang is a Software Engineer at Databricks. Eric Liang is a Senior Staff Software Engineer at Databricks. Ryan Marcus is an Assistant Professor at the University of Pennsylvania. Sid Taneja is a Senior Engineering Manager at Databricks.
Databricks is hiring!
If you've built, optimized, or experimented with AI-driven approaches to database optimization, we'd love to hear from you. Reach out to sid.taneja@databricks.com to discuss opportunities in the AI×systems space.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t/adrs-global and Discord
🗞️ Follow us: x.com/ai4research_ucb