Bespoke OLAP: Using AI to Synthesize Workload-Specific Database Engines from Scratch

This post is part of the AI-Driven Research for Systems (ADRS) blog series, where we explore how AI can be applied to systems research. This post was contributed by Johannes Wehrstein, Timo Eckmann, Matthias Jasny and Carsten Binnig (TU Darmstadt).
Every modern OLAP engine pays a hidden performance tax: the cost of being general-purpose. They must support any schema, any SQL query, any access pattern. Even when a production workload uses the same 20 query templates, day after day. What if we could let AI build a database engine for exactly your workload, from scratch, in a few hours?
We introduce Bespoke OLAP, a fully autonomous synthesis pipeline that uses LLM-guided code generation to produce complete, workload-specific C++ database engines. The results:
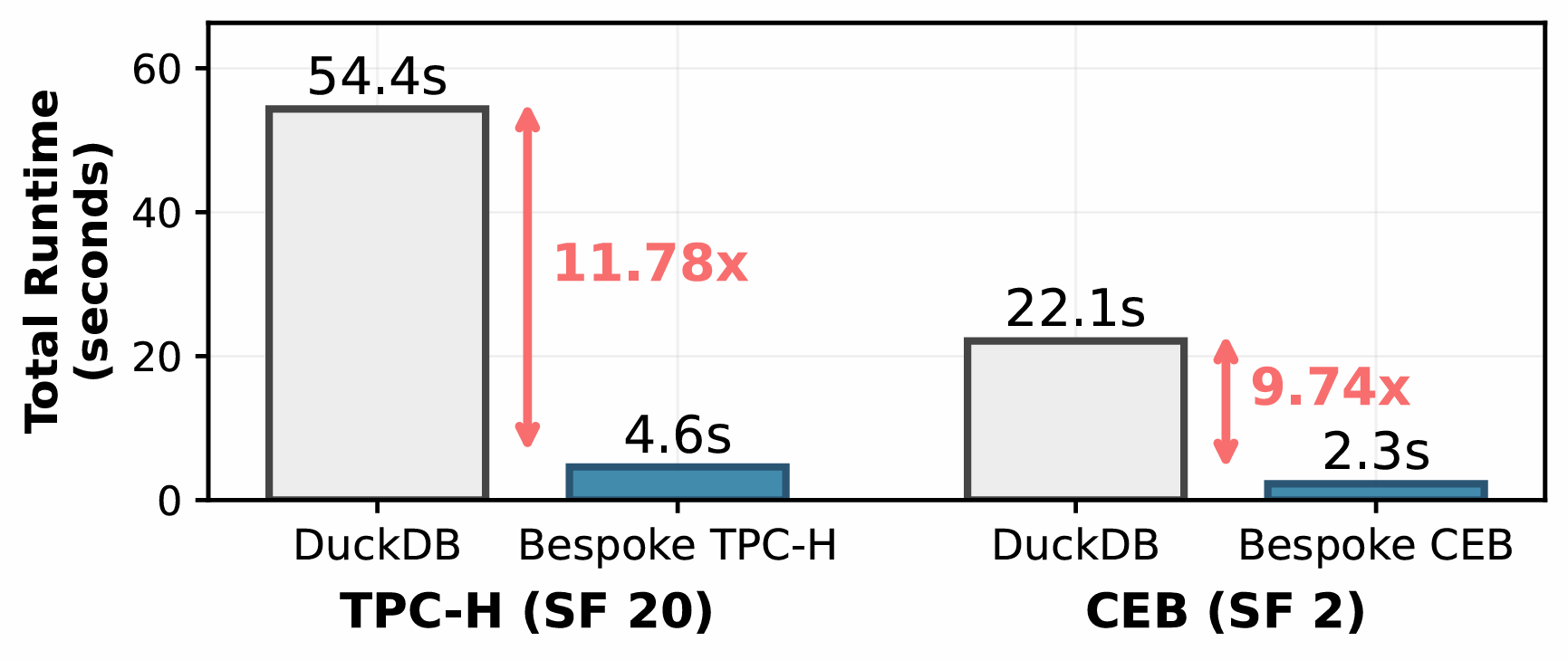
- 11.78x total speedup over DuckDB on TPC-H (SF 20), with a 16.40x median per-query speedup.
- 9.76x total speedup on CEB (real-world IMDB workload, SF 2), growing to 70x at larger scale factors.
- Every single query is faster: per-query speedups range from 5.7x to 1466x.
- Synthesis cost: ~$120 and 6-12 hours wall-clock (4-6 thousand LLM interactions). No manual intervention required.
Bespoke OLAP is fully open-source. Try it out!
- 📝 Paper: https://arxiv.org/abs/2603.02001
- 👩💻 Code: https://github.com/DataManagementLab/BespokeOLAP
- 🔍 Webpage & Demo: https://datamanagementlab.github.io/BespokeOLAP/
More from ADRS:
- ✍️ Previous Blogs: https://ucbskyadrs.github.io/
- 📝 ADRS Paper: https://arxiv.org/abs/2510.06189
- 👩💻 ADRS Code: https://github.com/UCB-ADRS/ADRS
- 💬 Join us: Slack and Discord
- 🌎 Follow us: x.com/ai4research_ucb
The Problem: The Performance Tax of Generality
Modern columnar OLAP engines like DuckDB, HyPer, and Umbra represent decades of engineering effort. They are fast, well-optimized, and broadly applicable. But they are still general-purpose DBMSs designed to handle arbitrary schemas, arbitrary SQL, and arbitrary access patterns.
This generality comes at a cost. Schemas are interpreted at runtime. Tuple layouts remain generic. Data structures are chosen to accommodate unknown future queries. Query compilation reduces some interpretation overhead, but the engine still operates within a generic storage and execution layer. This overhead is not due to poor engineering; it is the unavoidable price of generality.
Yet many real-world OLAP deployments do not need this flexibility. Enterprise data warehouses frequently execute stable suites of parameterized query templates. Recent real-world workload analyses of cloud databases such as Redshift and Snowflake confirm extremely high query repetition rates of queries. In these settings, the ability to run arbitrary ad-hoc queries is rarely exercised. But its cost is incurred on every execution.
If the workload is known in advance, a "one-size-fits-one" bespoke data-processing engine can eliminate this overhead entirely: schema interpretation disappears, storage layouts are organized around actual access patterns, encoding decisions are tailored to observed value distributions, and all queries are compiled into code that directly operates on workload-specific data structures.
The obstacle of building such bespoke DBMSs that are optimal for a given workload has never been conceptual feasibility, but rather economics: building a high-performance DBMS has required years of expert engineering. In a world with potentially millions of distinct workloads, manually building an engine for each one is infeasible.
The Opportunity: Synthesizing Entire Systems
This is where AI-Driven Research for Systems (ADRS) comes in. The core insight of AI-Driven Research for Systems is that AI can automate the iterative cycle of designing, implementing, and evaluating solutions, provided there exists a reliable evaluator. Database engines are a perfect fit: correctness can be verified against a reference system, and performance is directly measurable.
But Bespoke OLAP goes way further than prior ADRS work. Rather than optimizing a single algorithm or policy within an existing system, we synthesize a complete DBMS from scratch: storage layout, data ingestion, query execution, and low-level optimizations. All tightly coupled and all shaped for the target workload. This makes database engine synthesis one of the most ambitious applications of ADRS to date.
Key Distinction: Prior ADRS work treats systems as white boxes and rewrites individual components (schedulers, routing policies, placement strategies). Bespoke OLAP treats the entire system as the artifact to be synthesized. The LLM doesn't optimize an existing engine. It constructs a new one.
Bespoke OLAP: The Synthesis Pipeline
Naively prompting an LLM to produce a database engine does not work. In our early testing, full OLAP engines generated by LLMs often failed to compile, violated correctness, or exhibited fragile performance. Database engines are complex systems of deeply interdependent components. Storage formats constrain operator design, execution strategies depend on data layout, and optimizations in one layer can introduce regressions in another.
Bespoke OLAP addresses this through a structured synthesis pipeline that maintains correctness while aggressively optimizing performance. The pipeline takes two inputs, a set of SQL query templates and a dataset (as Parquet files), and produces a complete, optimized C++ engine.
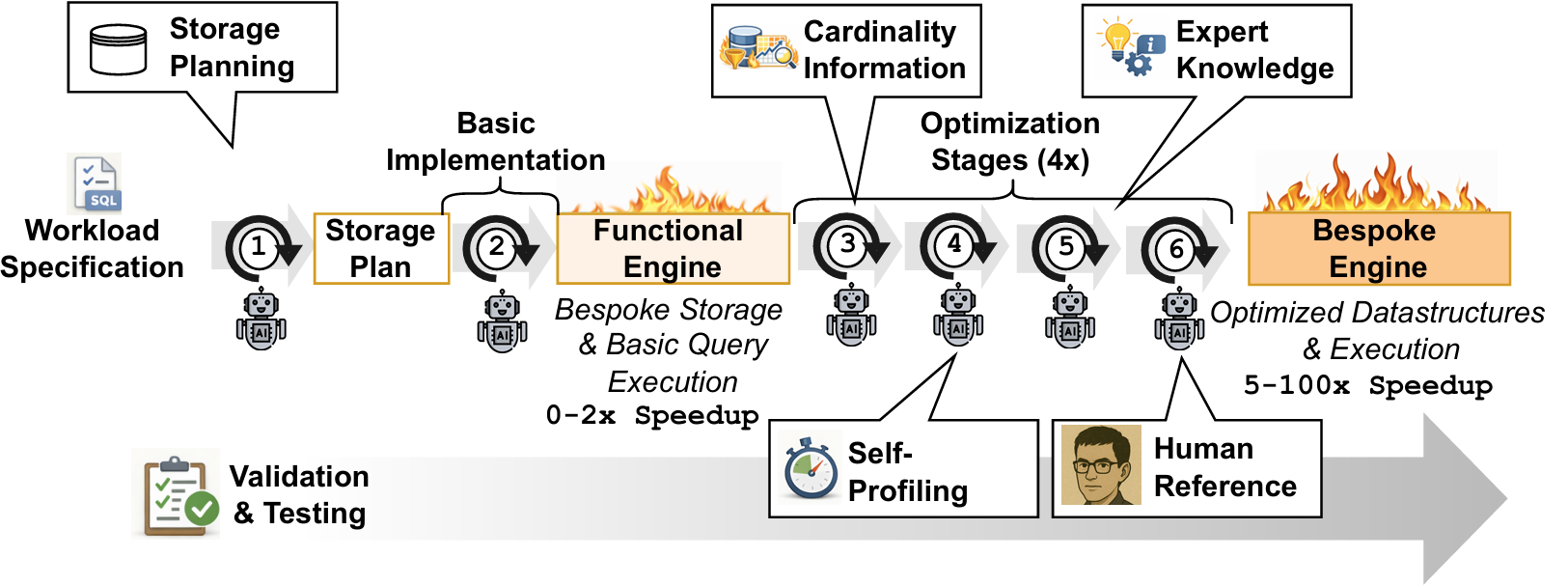
Step 1: Storage Layout Planning
Before writing any execution code, the Bespoke Agent examines the dataset and cross-references it with the query templates. It identifies which columns appear in predicates, which serve as join keys, which are co-accessed, and how data is distributed. Based on this analysis, it decides on physical sort orders, encoding/compression schemes, and auxiliary data structures, and commits these decisions before any query code is written. This co-designing of storage layout unlocks order-of-magnitude speedups, since advanced optimization techniques (beyond removing only the generalization-tax) like late materialization can be leveraged.
Step 2: Basic Query Implementation
With storage in place, the agent generates a dedicated execution function for each SQL template. At this stage the goal is correctness, not performance. Results are verified against DuckDB across diverse parameter instantiations.
Steps 3-6: Multi-Stage Optimization Loop
With a correct baseline established, the agent enters four rounds of optimization:
- Cardinality-Guided Optimization: The agent receives actual cardinalities from DuckDB query plans, bootstrapping empirical join-order exploration and eliminating clearly suboptimal query execution plans.
- Self-Profiling: The agent writes its own tracing instrumentation, examines where time is spent in each query, and localizes bottlenecks precisely.
- Expert Knowledge Injection: Curated optimization knowledge from decades of database research is provided: sequential access patterns, cache-aware algorithms, SIMD-friendly code, and more. The agent applies these selectively to identified bottlenecks.
- Human-Reference Prompting: The agent adopts the perspective of an expert database engineer, performing a holistic review of each query function for any remaining inefficiency.
Crucially, there is no cost model. Unlike traditional query optimizers, the Bespoke Agent discovers effective strategies empirically: it proposes an implementation, benchmarks it on sampled instantiations, and iteratively refines based on observed runtimes. The best strategy is hard-coded into the final artifact.
Infrastructure for System Synthesis
Just an LLM prompt is not enough. Systems-for-System-Generation are necessary to enable robust, autonomous engine synthesis.
A key contribution of Bespoke OLAP is the infrastructure that makes autonomous synthesis reliable. Three mechanisms proved indispensable:
Hotpatching via Conversation Branching. Each query begins with a shared preparation (storage planning, interface design), the synthesis branches into independent per-query optimization threads. Each thread carries the shared history but develops independently, keeping the LLM's context focused and manageable.
External Regression Tracking. LLM agents are unreliable at recognizing when a change has made things worse. An external monitor tracks every change, compares against the last known-good state, and automatically rolls back regressions. This ensures the optimization trajectory is monotonically improving.
Continuous Fuzzy Testing. Because query templates are parameterized, correctness is tested across diverse instantiations and multiple scale factors. Not just a single fixed test case.
Highly Promising Results
We evaluated Bespoke OLAP on two benchmarks, TPC-H and CEB (a templated version of the JOB benchmark on real-world IMDB data), against DuckDB v1.1.4, a state-of-the-art embedded analytical engine. Both systems run single-threaded, pinned to the same core, with all data in memory.
| Benchmark | DuckDB | Bespoke | Total Speedup | Median Per-Query |
|---|---|---|---|---|
| TPC-H (SF 20) | 54.4s | 4.6s | 11.78x | 16.40x |
| CEB (SF 2) | 22.1s | 2.3s | 9.76x | 4.66x |
These speedups are not driven by a few outlier queries. Bespoke OLAP outperforms DuckDB on every single query, with per-query speedups ranging from 5.7x to 104x on TPC-H and from 1.5x to 1466x on CEB. The gains on TPC-H are particularly notable because OLAP engines are already heavily tuned for this benchmark, and some even implement specific code paths for TPC-H queries. We now have comparisons with ClickHouse and Umbra (webpage), as well as a live demo.
Scalability
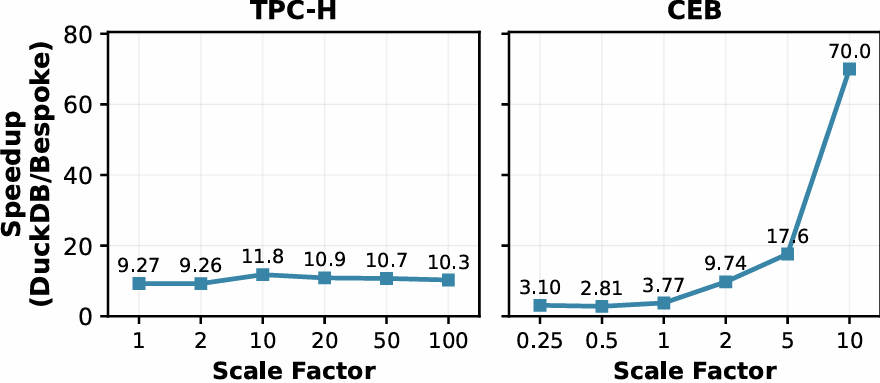
On TPC-H, the speedup remains stable at approximately 10-12x across all tested scale factors (SF 1 to SF 100), indicating that Bespoke-TPCH and DuckDB exhibit the same asymptotic complexity. On CEB, however, the speedup grows with data size, from 3x at SF 0.25 to over 70x at SF 10, because the bespoke engine achieves an algorithmically lower complexity class on the complex, correlated IMDB workload.
Where Do the Speedups Come From?
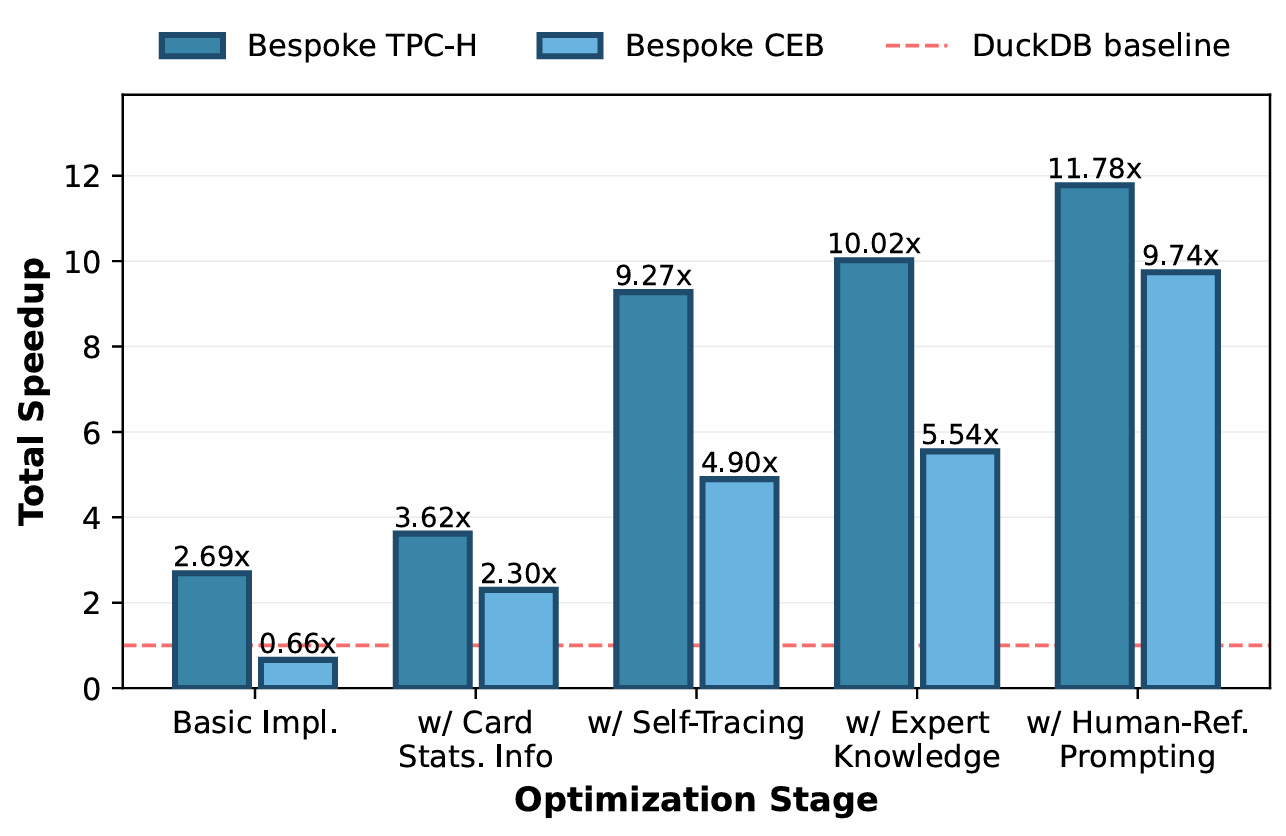
We decomposed the gains along two dimensions:
Optimization stages matter. The initial (unoptimized) implementation already achieves 2.7x on TPC-H, from bespoke storage alone. Each subsequent optimization stage adds meaningfully: cardinality-guided optimization, self-profiling, expert knowledge, and human-reference prompting together lift the speedup from 2.7x to 11.78x.
Bespoke storage is a multiplier. With a flat (generic) storage layout, bespoke query code alone achieves 5.18x after optimization on TPC-H. With bespoke storage, this jumps to 11.78x. The synergy between workload-specific storage and workload-specific execution is what produces the largest gains.
What the Agent Discovers
The Bespoke Agent employs a rich repertoire of strategies spanning six categories. Some highlights:
- Bitmap semi-joins in 73.7% of queries — a technique rarely used in general-purpose engines but highly effective when the join selectivity is known at synthesis time.
- Inline fused aggregation in 97.4% of queries — eliminating materialization boundaries between operators.
- Hash indices for O(1) join lookups in 47.4% of queries — replacing generic hash-join operators with pre-built, workload-specific index structures.
- Precomputed derived columns in 36.8% of queries — materializing frequently needed expressions at ingestion time.
- Low-level optimizations: pointer __restrict aliasing (50%), integer-scaled arithmetic (44.7%), branchless range checks (18.4%), and software prefetching (10.5%).
The agent's selections are remarkably targeted: for each query, it applies only a small, carefully chosen subset. This query-specific decision-making is precisely what distinguishes a bespoke engine from a general-purpose system.
Q13 performs a focused two-column scan, touching only orders.custkey and orders.comment. Variable-length comments are accessed through a string arena for fast offset-based substring checks. Each order row carries two bitmasks, alpha_mask (recording which letters appear) and bigram_mask (recording hashed character pairs), that cheaply rule out non-matching rows before any substring search is attempted. A general-purpose engine has no mechanism to discover or exploit this pattern.
The Synthesis Process
Synthesizing Bespoke-TPCH required approximately 5,000 agent turns (LLM interactions + tool calls using GPT 5.2 Codex), producing ~12,000 lines of C++ code. The total API cost was $120.99 (of which $109.89 was spent on optimization stages). Wall-clock time ranges from 6 to 12 hours, depending on LLM rate limits.
The agent maintains a disciplined development cycle: for approximately every 1.5 code edits, it triggers a validation check, roughly every 70 changed lines of code. Nearly 80% of all shell tool calls are text-processing and search operations (primarily grep), reflecting a strategy of selectively retrieving only the information needed rather than loading entire files into context.
Correctness is strong from the start: 17 out of 22 TPC-H queries were correct on the first implementation attempt; the remaining five were corrected within a few turns.
Implications for ADRS
Bespoke OLAP demonstrates several principles that extend the ADRS methodology:
System-level synthesis is feasible. Prior ADRS work focused on optimizing individual algorithms within existing systems. Bespoke OLAP shows that AI can construct entire systems from scratch (including storage, execution, and their deep interdependencies) with order-of-magnitude performance gains over expert-engineered alternatives.
Structure beats brute force. Naively prompting an LLM to build a database engine fails. The key is a carefully staged pipeline, separating storage planning from query implementation, separating correctness from performance optimization, and providing progressively richer signals (cardinalities, profiling, expert knowledge, holistic review). This mirrors ADRS best practices around problem decomposition and evaluator design.
Infrastructure is as important as the agent. Hotpatching, regression tracking, conversation branching, and continuous testing are not optional. They are what make the difference between an LLM producing fragile code and an LLM producing a production-grade system. For ADRS to scale to system-level synthesis, the evaluation and deployment infrastructure must scale with it. Systems-for-system-generation is the cornerstone.
Empirical search replaces cost models. Rather than building cost models or relying on optimizer heuristics, the Bespoke Agent discovers optimal strategies by directly measuring alternatives. This is the ADRS philosophy taken to its logical conclusion: when you have a fast, reliable evaluator, search beats prediction.
Try It Out
Bespoke OLAP is fully open-source. To synthesize a bespoke engine for your workload, provide a set of SQL query templates and a dataset as Parquet files:
- 📝 Paper: https://arxiv.org/abs/2603.02001
- 👩💻 Code: https://github.com/DataManagementLab/BespokeOLAP
- 📦 Generated Engine Artifacts: https://github.com/DataManagementLab/BespokeOLAP_Artifacts
- 🔍 Webpage & Demo: https://datamanagementlab.github.io/BespokeOLAP/
Citation
@article{wehrstein2026bespoke,
title={Bespoke OLAP: Synthesizing Workload-Specific One-size-fits-one Database Engines},
author={Wehrstein, Johannes and Eckmann, Timo and Jasny, Matthias and Binnig, Carsten},
journal={arXiv preprint arXiv:2603.02001},
year={2026}
}
Get In Touch
- Johannes Wehrstein: email, LinkedIn
- Timo Eckmann: email, LinkedIn
- Matthias Jasny: email, LinkedIn
- Carsten Binnig: email, LinkedIn
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
🗞️ Follow us: x.com/ai4research_ucb