AI-Driven Research at Berkeley
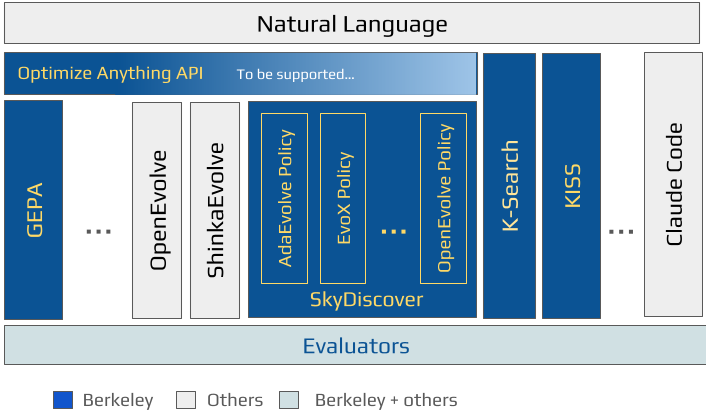
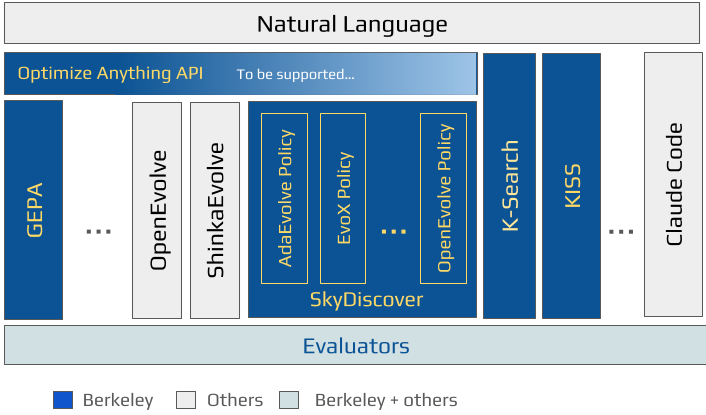
This post provides an overview of recent work from Berkeley on automated discovery using AI. We cover the main solutions and frameworks we've developed so far, along with the problems they are designed to address. We also describe how these efforts fit together as part of a broader push toward AI-driven discovery.
- ✍️ Previous ADRS Blogs: https://ucbskyadrs.github.io/
- 💬 Join us: join.slack.com/t/adrs-global and Discord
- Follow us: x.com/ai4research_ucb
Accelerating Discovery with AI
One of the most ambitious goals of artificial intelligence is to automate the scientific discovery process itself. A number of recent efforts appear to be making real progress toward that goal. FunSearch from Google DeepMind demonstrated it was possible to improve state-of-the-art algorithms in mathematics. Subsequently, AlphaEvolve from Google showed evolutionary techniques could dramatically improve system performance. Open-source frameworks, such as OpenEvolve and ShinkaEvolve, further emerged as powerful tools enabling AI-driven discovery. Various research efforts, such as MIT's Glia and UW's SDS, also center on this approach. At Berkeley, as early as December 2024, our framework GEPA demonstrated success in discovering high-performing solutions using reflective text evolution in hard problems like writing kernels for new hardware architectures and optimizing agents, even outperforming RL. Most recently, Andrej Karpathy's autoresearch has gained significant attention by demonstrating how an AI agent can be used to autonomously conduct research. Taken together, these efforts suggest that AI-driven discovery is emerging as a practical reality.
At Berkeley, we've been working on automated discovery for over a year and are excited to share our results in this space. As Figure 1 shows, we have worked across the stack to build the various components needed to realize the vision of AI-driven discovery. We started with building the foundations of this approach with GEPA, demonstrating an end-to-end framework for optimizing agents and writing optimized kernels for AMD's NPUs. We further demonstrated the broad-applicability and promise of this approach with our work on AI-Driven Research for Systems (ADRS) by applying these techniques to 10 diverse systems research problems. Next, realizing that frameworks like GEPA, OpenEvolve, and ShinkaEvolve all perform text optimization in various paradigms, we developed a universal declarative API (optimize_anything) to decouple problem specification from different solver backends which can all be invoked via the same unified API. Subsequently, we have developed K-Search and SkyDiscover (AdaEvolve and EvoX), frameworks that drive the loop of automated search, and are also compatible with optimize_anything; alongside KISS, a coding agent that also enables these goals.
As an overview, we provide a brief summary of each of our efforts below:
- AI-Driven Research for Systems (ADRS): We describe the foundations of AI-driven research and provide results on a range of real-world research problems, demonstrating that this approach can significantly outperform existing state-of-the-art baselines. We provide our analysis and a benchmark of use cases in this work.
- optimize_anything: We present a universal API for text optimization that separates the user-facing interface from the underlying search algorithm. This makes it easy to define artifacts, evaluators, and objectives once, then swap in any optimization backend through configuration. The API allows expressing a broad class of optimization problems (spanning 3 optimization paradigms including single task, multi task, and generalization) as a text optimization problem through the same interface.
- GEPA: We introduce a dependency-free, extensible framework that uses reflective mutation and Pareto-efficient search to optimize any text artifact including prompts, code, agent architectures and skills, and more. By reflecting on rich evaluation feedback in natural language rather than collapsing it into scalar rewards, GEPA can outperform RL in agent optimization while using 35× fewer rollouts. It supports all 3 optimization paradigms (single-task, multi-task and generalization) and serves as the primary backend for optimize_anything.
- KISS: We introduce a simple agent framework built around composable Python primitives rather than heavy abstractions. It enables long-running agent workflows, supports self-improving agents, and provides a practical foundation for building and optimizing coding agents.
- K-Search: We present a new approach to automated GPU kernel generation that uses LLMs as a world model to guide search. By separating high-level strategy from low-level implementation, K-Search can explore more effective multi-step optimizations and achieves strong results on real kernel workloads.
- SkyDiscover: We release a modular framework for AI-driven discovery that breaks the discovery loop into reusable components such as context building, solution generation, evaluation, and selection. It provides a common foundation for implementing, benchmarking, and comparing discovery algorithms across a wide range of tasks.
AI-Driven Research for Systems (ADRS)
As described in our previous blog post and paper, ADRS automates the core iterative loop of research.
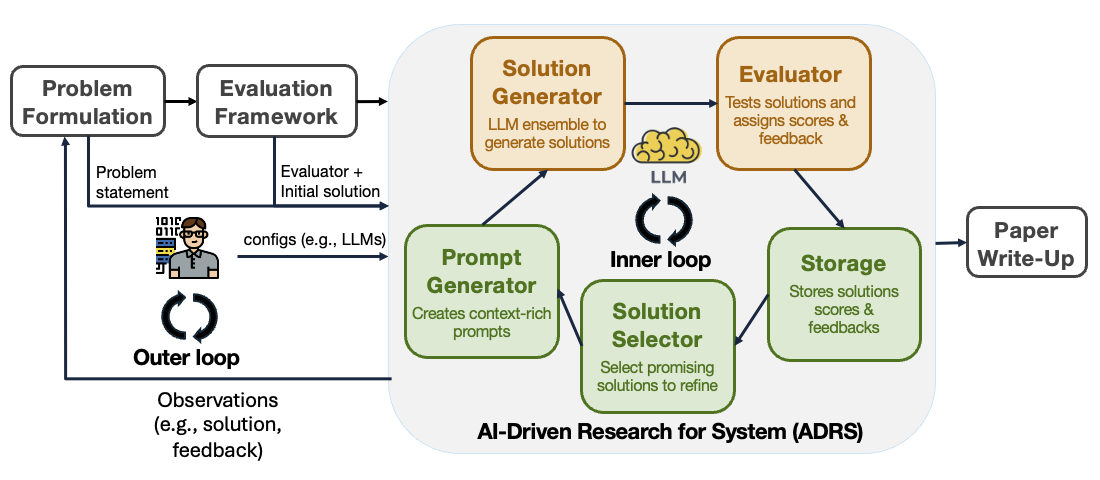
This automated loop is the foundation of several existing implementations, ranging from specialized frameworks like Google's AlphaEvolve, GEPA, OpenEvolve, and ShinkaEvolve, to workflows using interactive coding assistants like Cursor.
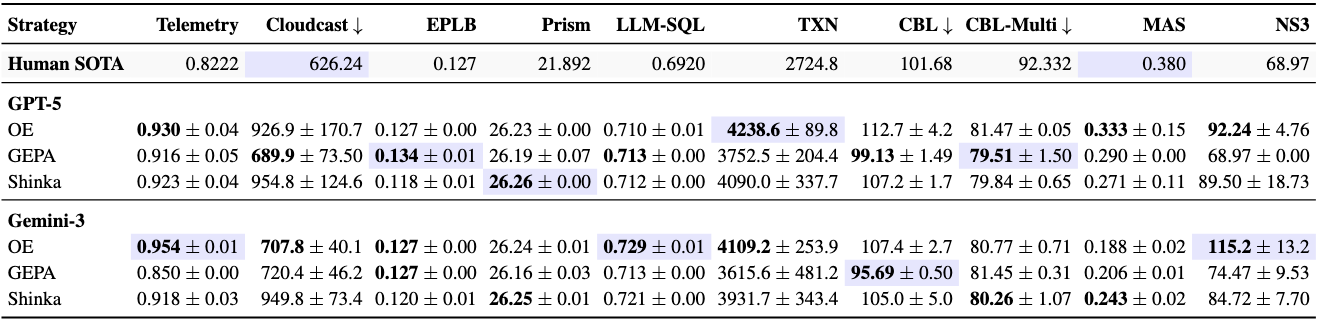
To rigorously evaluate the capability of ADRS, we expanded our investigation to three open-source frameworks—GEPA, OpenEvolve, and ShinkaEvolve—on ten real-world research problems across diverse sub-domains, including networking, databases, and core systems. We use GPT-5 and Gemini-3.0, capped at 100 iterations per run to ensure a fair comparison, and provide the specific configs used in the appendix of our paper.
Most of these solutions were discovered in under 8 hours, at a cost of less than $30. Importantly, the results we're sharing should be seen as a starting point; as the frameworks and models improve, we expect even more improvements.
One of the most exciting capabilities of ADRS is its ability to generate solutions by drawing on techniques from different domains. While systems researchers typically specialize in a particular subfield (e.g., networking or databases), LLMs are trained on vast, diverse datasets that span the entire spectrum of human knowledge. This breadth allows ADRS to identify structural parallels between systems performance problems and challenges in unrelated fields—connections that are easily overlooked by experts focused on a single domain. Table 6 provides an overview of cross-domain techniques discovered by ADRS frameworks across our case studies.
Paper: https://arxiv.org/abs/2510.06189
Code: https://github.com/UCB-ADRS/ADRS
Blog: https://ucbskyadrs.github.io/
Open-Source Frameworks
We describe the various efforts from our lab below that tackle different parts of the automated discovery loop. We present the API layer first and then the frameworks in alphabetical order.
optimize_anything: A Universal API for Text Optimization and Evolution
Instead of locking users into specific search algorithms, optimize_anything provides a common frontend API where strategies like Genetic-Pareto and EvoX are plugged in as backends.
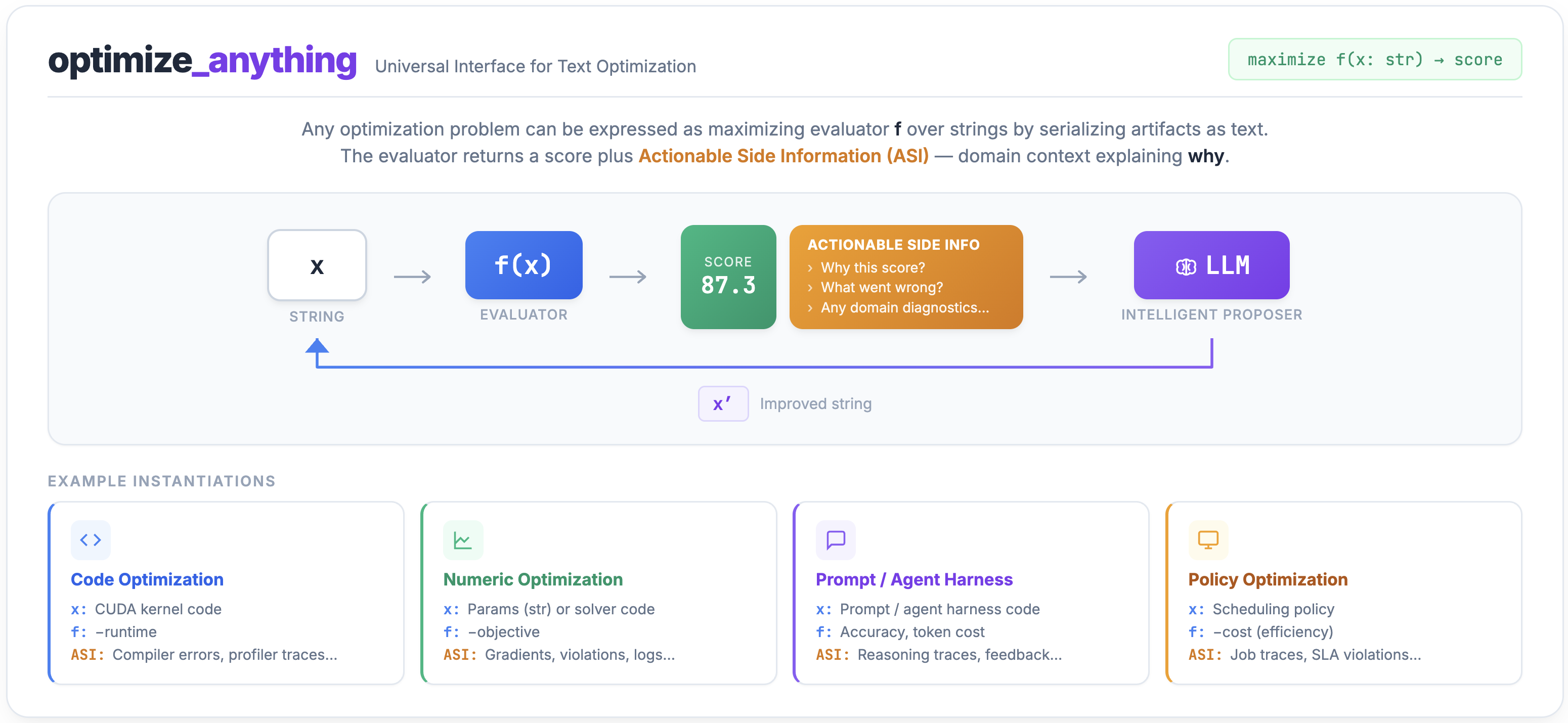
Prior frameworks tightly couple the optimization task with specific search algorithms (e.g., prompt samplers, island topologies). This makes it difficult to experiment with different strategies without rewriting code. optimize_anything removes this limitation by establishing a backend-agnostic interface. Users simply install optimize_anything, define their optimization scenario through just 2 required inputs: 1) what to optimize (initial artifact, or natural language description), 2) How to measure it, and the backend handles the rest.
Specifically, optimize_anything provides:
- Common Frontend API: A unified interface for defining artifacts, evaluators, and objectives, independent of the underlying search logic.
- Pluggable Backends: GEPA is the default backend implementation, but the system allows users to plug in and try multiple search algorithms via a simple config.
By treating the search strategy as a modular backend, optimize_anything enables seamless experimentation with different optimization engines while keeping the user interface constant. In our optimize_anything blog, we demonstrate that with just one API, we can:
- create agent skills achieving near-perfect Claude Code task completion 47% faster,
- optimize cloud scheduling policies that cut costs by 40%, beating expert heuristics,
- find detailed system prompts to boost GPT's math reasoning accuracy,
- discover bespoke agent harnesses that nearly triple Gemini Flash's ARC-AGI accuracy,
- write custom solvers to match and exceed Optuna in blackbox mathematical optimization,
- model a 3D unicorn,
- and many other applications.
Code: https://github.com/gepa-ai/gepa
Blog: https://gepa-ai.github.io/gepa/blog/2026/02/18/introducing-optimize-anything/
GEPA
GEPA optimizes any text artifact—prompts, code, policies, hypotheses—by reflecting on evaluation feedback in natural language. The same framework that optimizes an LLM agent also discovers scheduling algorithms or writes GPU kernels.
GEPA (ICLR 2026) is a dependency-free Python framework for optimizing any text artifact—prompts, agent architectures, code, scheduling policies, hypotheses and more—using reflective mutation and Pareto-efficient search. Given an artifact and an evaluator, GEPA iteratively has an LLM reflect on evaluation feedback (agent execution traces, compiler errors, profiling data, test outcomes, human feedback or any other signal) to diagnose shortcomings and propose diverse improved candidates. GEPA maintains a Pareto frontier over candidates, preserving specialists that excel on different subsets of the evaluation (avoiding local optima), naturally supporting multi-objective and multi-task optimization. Across six benchmarks (multi-hop QA, math, instruction following, privacy, retrieval verification), GEPA outperforms GRPO by up to 19pp while using 35× fewer rollouts (679 vs. 24,000).
Every component in the optimization loop is independently swappable: candidate selection strategies (Pareto, epsilon-greedy, or custom), batch samplers, component update order, merge strategies, evaluation policy, proposal mechanisms, stopping conditions, including the LLM-framework itself. Users start with a simple optimize_anything() call and progressively customize any piece without switching frameworks. This flexibility makes GEPA straightforward to integrate into any existing system regardless of its shape; it has been adopted as a core optimizer in DSPy, Pydantic AI, Comet ML's Opik, MLflow, and verifiers. GEPA natively supports all three optimization paradigms exposed by optimize_anything (single-task, multi-task, and generalization) and serves as its primary backend. It has been downloaded over 13M+ times, deployed by 25+ organizations, including at Databricks where GEPA-optimized open-source models outperform Claude Opus 4.1 and GPT-5 at 90× lower cost and by OpenAI for building Self-Evolving Agents.
Notably, GEPA complements RL: Arc.computer applied GEPA on top of an already RL-tuned model in their ATLAS framework, yielding +142% student performance improvement. Researchers have also used GEPA for AI safety, GPU parallelization (boosting compilation success to 100% and increasing functional speedups by up to 50%), production OCR (consistent error reduction across Gemini model classes), healthcare multi-agent systems, and simulation-based agent training (Veris.AI's RAISE, NeurIPS 2025: 12.5% → 62.5% task correctness). A full showcase of 50+ research and production use cases is available here.
Code: https://github.com/gepa-ai/gepa
Paper: https://arxiv.org/abs/2507.19457
Website: https://gepa-ai.github.io/gepa/
Blog: https://gepa-ai.github.io/gepa/blog/
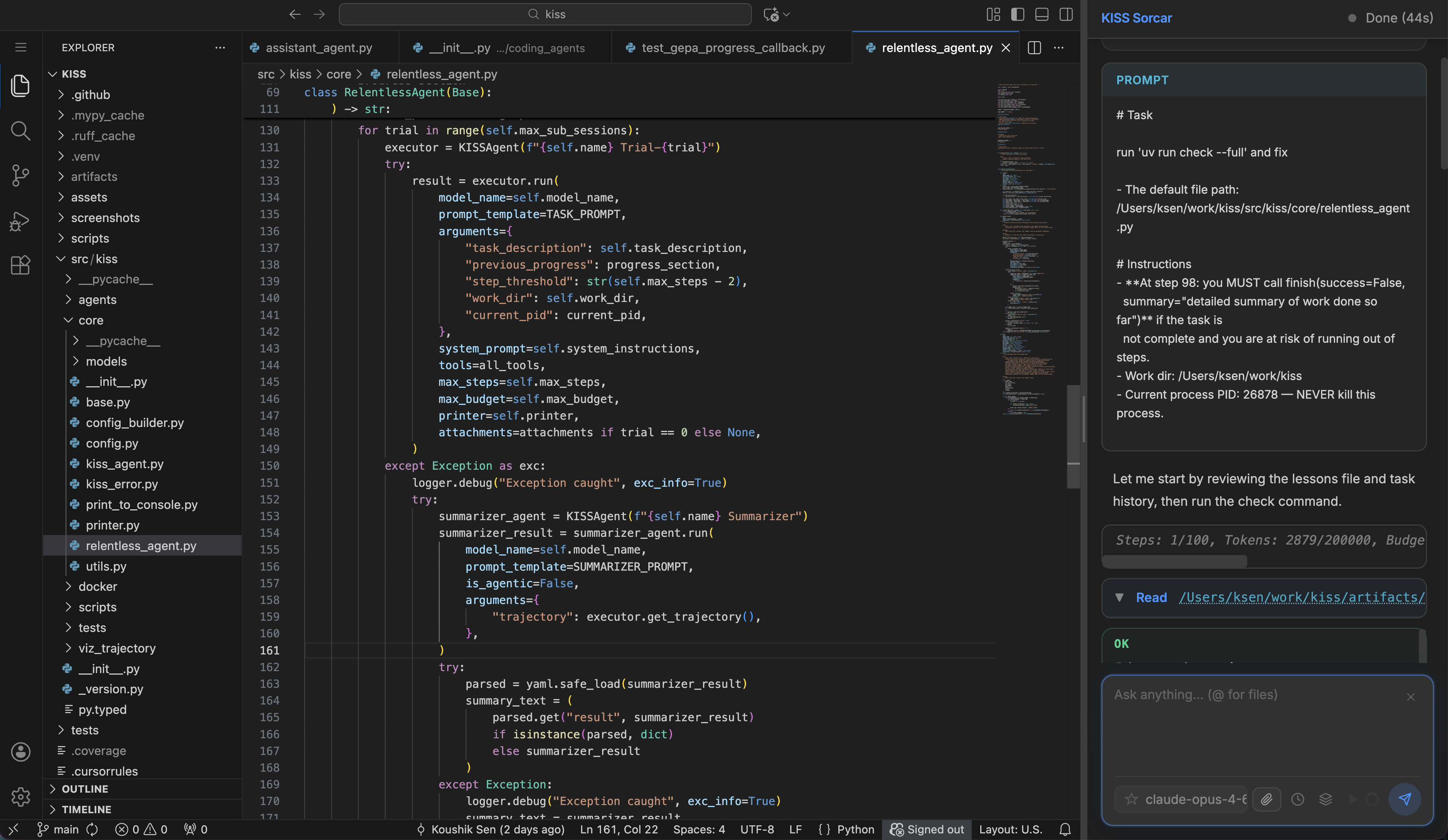
KISS
Modern AI agent frameworks often introduce excessive layers of abstraction and boilerplate. KISS takes the opposite approach: by treating agents and tools as simple, composable Python primitives, it enables agents to relentlessly tackle long-running tasks and even optimize their own codebase.
The AI agent ecosystem has grown increasingly complex, creating steep learning curves that hinder developer productivity. KISS strips away unnecessary complexity, allowing complex tasks and constraints to be expressed purely in natural language. Its core engine, the RelentlessCodingAgent, runs an LLM-powered ReAct loop designed to hammer at long-running tasks across multiple sub-sessions until it succeeds or exhausts its budget.
- Smart Auto-Continuation: Seamlessly executes massive tasks across tens of thousands of sub-sessions (e.g., 10,000+) of 100-step ReAct agents, using a chronological list of steps taken by the agent along with explanations and relevant code snippets, to perfectly track and resume progress.
- Self-Evolution: Since agents are simple Python classes, they can easily optimize their own codebase. Using the AgentEvolver, the relentless agent self-evolved overnight, reducing its API costs by 98%.
- Zero-Boilerplate Tools: Core tools (Bash, Edit, Read, Write) are just plain Python functions with type hints—no complex wrappers or config ceremonies required.
- Integrated Ecosystem: Runs natively in Docker for isolated execution, provides implementations of the GEPA optimizer, Agent Evolver, and OpenEvolve/ShinkEvolve, and powers KISS Sorcar, a fully open-source local AI IDE. Repo optimizer and agent optimizer present the simplest and most modern techniques for evolving repositories and agents (including prompts, tools, and agent code), effectively by exploiting frontier models to the fullest.
Code: https://github.com/ksenxx/kiss_ai/tree/main
K-Search
Traditional methods treat LLMs as stochastic code generators inside heuristic loops — but this misses a key point: LLMs are powerful planners with rich domain priors.
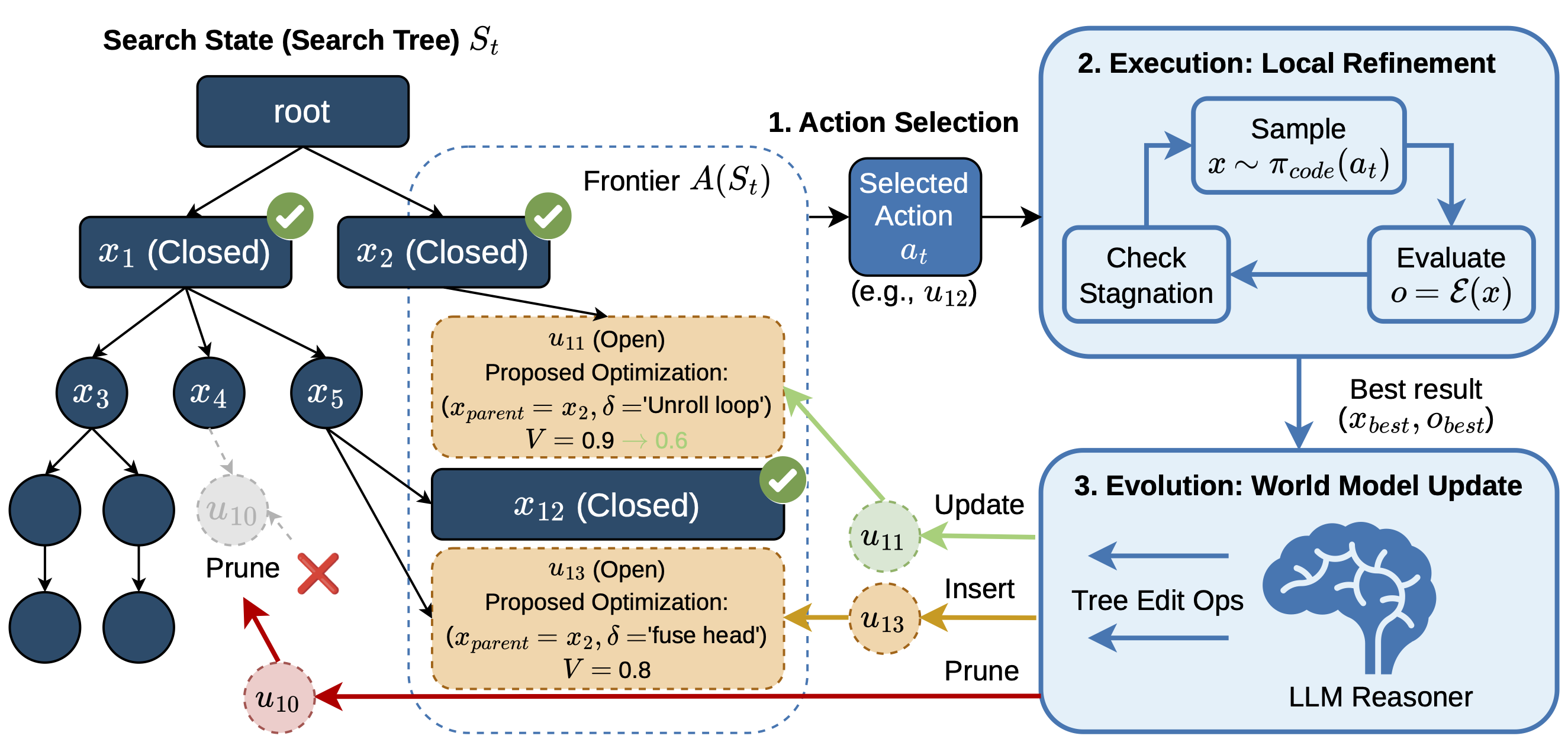
We introduce K-Search, a new paradigm for automated GPU kernel generation that leverages LLMs as a co-evolving intrinsic world model to guide the search process. By decoupling high-level optimization strategy from low-level code implementation, K-Search can pursue multi-step transformations even when intermediate implementations do not immediately improve performance.
- Our discovered kernels achieve an average speedup of ~2.10× over state-of-the-art evolutionary search across 4 FlashInfer kernels on H100/B200.
- Up to 14.3× gain on complex Mixture-of-Experts (MoE) kernels, compared to OpenEvolve.
- State-of-the-art performance on GPUMode TriMul (H100) task — beating both automated and human solutions.
Code: https://github.com/caoshiyi/K-Search
Paper: https://arxiv.org/abs/2602.19128v1
SkyDiscover: A Modular Foundation for AI-Driven Discovery
To address the lack of reusable infrastructure in prior work, we built SkyDiscover, a modular foundation for AI-driven discovery that makes it easy to build, run, and compare discovery algorithms across domains.
Existing evolutionary discovery systems (OpenEvolve, GEPA, ShinkaEvolve) tightly couple selection logic, prompt construction, evaluation, and resource allocation. Changing how parents are selected often means rewriting how prompts are built. This coupling makes it difficult to experiment with new search strategies, compare methods fairly, or scale to new problem domains. SkyDiscover solves this by decomposing the discovery loop into four independently replaceable components, connected by a programmable control loop:
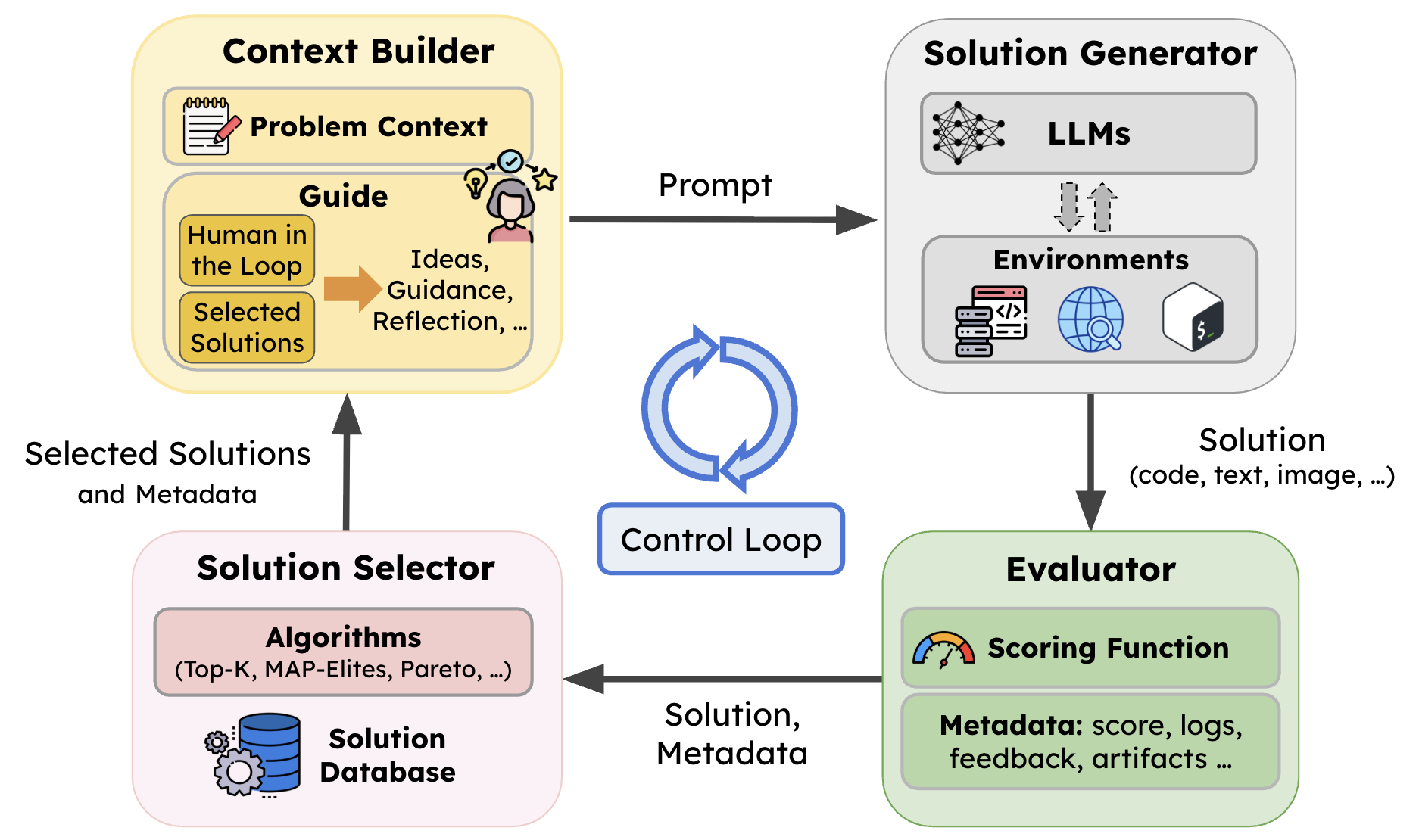
- Context Builder — constructs problem + history + guidance
- Solution Generator — proposes candidates (LLMs + tools)
- Evaluator — scores solutions with rich feedback
- Solution Selector — maintains and evolves the search process
Both the components and the orchestration logic that connects them are programmable. Algorithms can modify how experience is accumulated, how candidates are generated, how selection operates, and even how the control loop itself behaves. This programmability is what enables adaptive algorithms like AdaEvolve and EvoX to be implemented in ~2,500 lines of code each.
Three Evaluator Formats
A key design goal of SkyDiscover is making it easy to bring any problem into the framework. To that end, SkyDiscover supports three evaluator formats and auto-detects which one is being used:
- Python evaluator — a single file with an
evaluate(program_path)function that returns a score and optional artifacts (feedback strings, metrics, traces). This is the simplest option and covers most use cases:
def evaluate(program_path):
score = run_and_grade(program_path)
return {
"combined_score": score,
"artifacts": {"feedback": "Off by one in the loop boundary"},
}
- Containerized evaluator — a directory with a
Dockerfileandevaluate.shthat writes JSON to stdout. Runs in Docker, so it can have arbitrary dependencies (GPU runtimes, system libraries, custom compilers). This is useful for systems benchmarks like GPU kernel optimization or network simulation. - Harbor-format tasks — a directory following the Harbor standard (
instruction.md+environment/Dockerfile+tests/). SkyDiscover natively supports Harbor-format benchmarks, enabling out-of-the-box compatibility with external benchmark suites including AlgoTune, EvoEval, HumanEvalFix, BigCodeBench, LiveCodeBench, USACO, CRUSTBench, and CodePDE
This means researchers can bring their own evaluation infrastructure without modifying SkyDiscover's internals; whether it's a 5-line Python function, a Docker container with CUDA dependencies, or an existing community benchmark.
What SkyDiscover Enables:
- Plug-and-play discovery algorithms Swap selection strategies (Top-K, Pareto, MAP-Elites, etc.) or entire search paradigms without rewriting the system
- Search over strategies, not just solutions Treat the optimization process itself as an object of search
- Unified benchmarking across tasks and methods Run different algorithms under identical settings for fair comparison
- Broad task coverage (~200+ problems) Across math, systems, programming, kernels, and prompts
- Seamless integration with optimize_anything + ADRS Same abstraction across problem specification → search → evaluation
SOTA Adaptive Discovery Algorithms (Built on SkyDiscover)
On top of this modular foundation, SkyDiscover supports a broad class of LLM-driven evolutionary algorithms, and enables two key advances:
Adaptive Evolution (progress-aware search)
Discovery is treated as a non-stationary optimization process, where the system dynamically adjusts:
- exploration vs exploitation — shifts search behavior as the run progresses
- compute allocation
- search strategies
based on real-time progress signals.
Self-Evolving Optimization (AI optimizes itself)
Beyond adapting parameters, the system evolves the optimization strategy itself:
- rewrites how solutions are selected and combined
- changes mutation / refinement strategies
Result
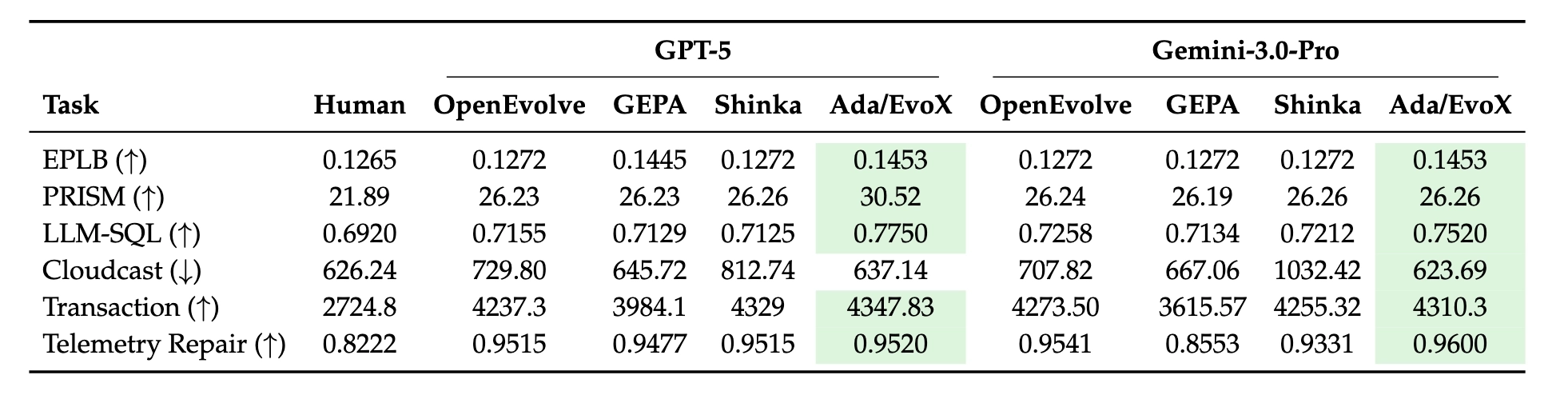
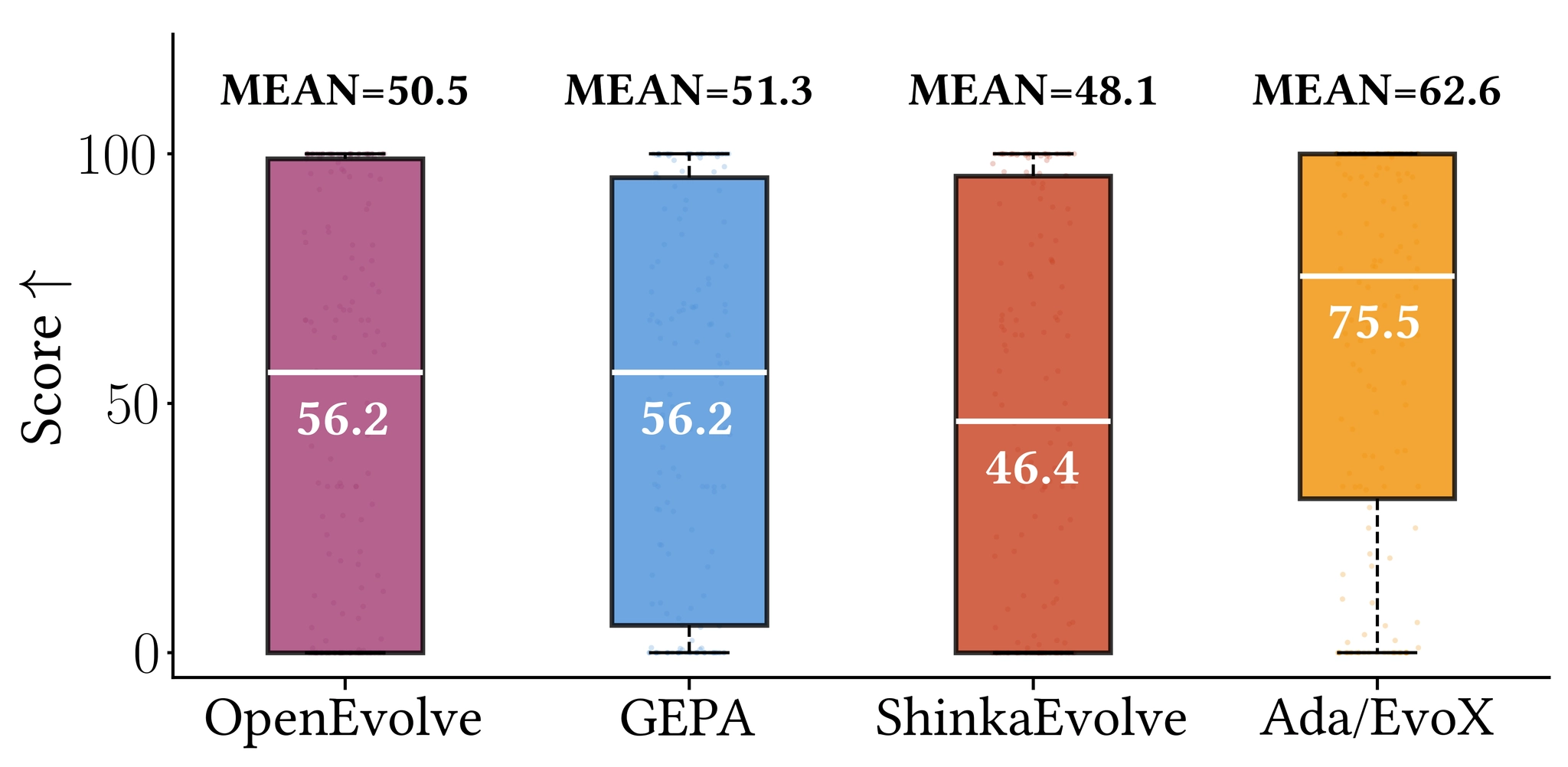
Across 200+ tasks under fixed budgets and models, AdaEvolve / EvoX achieve the strongest open-source performance.
- Outperform OpenEvolve, GEPA, and ShinkaEvolve across math, systems, and programming
- Match or exceed AlphaEvolve / human SOTA on multiple tasks
- +34% median improvement on 172 Frontier-CS problems
- Real-world gains: 41% lower cloud transfer cost, 14% better MoE balance, 29% lower KV-cache pressure
Code: https://github.com/skydiscover-ai/skydiscover
Blog: https://skydiscover-ai.github.io/blog.html
AdaEvolve: https://arxiv.org/abs/2602.20133
EvoX: https://arxiv.org/abs/2602.23413
What's Next?
We are actively pursuing research on ADRS. In the coming weeks, we will introduce a standardized leaderboard to benchmark AI performance on a range of different tasks. We will also continue our blog series and feature success stories from both academia and industry. Stay tuned!
Acknowledgments
This research was supported (in alphabetical order) by gifts from Accenture, AMD, Anyscale, Broadcom Inc., Google, IBM, Intel, Intesa Sanpaolo, Lambda, Mibura Inc, Samsung SDS, and SAP.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t/adrs-global and Discord
🗞️ Follow us: x.com/ai4research_ucb