Automating Algorithm Discovery in the Lakehouse: Leveraging ADRS to Improve Bauplan

This post is part of our AI-Driven Research for Systems (ADRS) case study series, where we use AI to automatically discover better algorithms for real-world systems problems. We feature exciting work from Bauplan this week!
In this blog, we describe how we repeatedly sample frontier models to generate scheduling policies for workloads in a FaaS lakehouse, Bauplan. Leveraging our FaaS simulator, Eudoxia, as a fast verifier, we share preliminary findings (to be presented at AAAI26) in our journey in applying AI to real-world systems.
- 📝 Bauplan Paper: https://arxiv.org/pdf/2510.18897
- 📝 ADRS Paper: https://arxiv.org/abs/2510.06189
- ✍️ Previous ADRS Blogs: https://ucbskyadrs.github.io/
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb, **Bauplan Engineering Blog, Bauplan on Linkedin**
In Eudoxia, (...), a carpet is preserved in which you can observe the city's true form. At first sight nothing seems to resemble Eudoxia less than the design of that carpet (...), but if you pause and examine it carefully, you become convinced that each place in the carpet corresponds to a place in the city and all the things contained in the city are included in the design." I. Calvino, Invisible Cities
The Problem: Designing Flexible Scheduling Policies
Bauplan is a platform for running data pipelines, based on a scheduler: when multiple users want to run their DAGs, which one goes first? How many resources should they be given? When should failed work be retried?
In practice, this is a multi-dimensional, complex problem. Tasks within an organization may differ in how much time and resources they require, and different organizations may have wildly different distributions: some use Bauplan mostly for long-running batch jobs while others execute frequent mini-batches and online queries. Moreover, schedulers can be designed for optimizing different metrics: high throughput, low latency for high-priority jobs, predictable performance.
Our challenge is therefore the following: can we use LLMs to automatically write and improve policies, based on a distribution of workloads and a target KPI?

Not a Warehouse, not a Lambda, but a Third New Thing
The Data Lakehouse (DLH) is the de facto standard for analytics, data engineering and AI workloads. In traditional DLHs, this flexibility comes at a cost: debugging data pipelines, running workloads on a schedule, querying tables requires practitioners to move between several UIs and master a plethora of tools, each with their own mental models:
| Interaction · UX · Infrastructure | | --- | --- | --- | | Traditional DLH | | | | Batch pipeline · Submit API · One-off cluster | | Dev. pipeline · Notebook Session · Dev. cluster | | Inter. query · Web Editor (JDBC Driver) · Warehouse |
Bauplan takes a different approach, by serving interactive and batch use cases through a unified Function-as-a-Service (FaaS) runtime on VMs:
| Interaction · UX · Infrastructure |
| --- | --- | --- |
| FaaS DLH | | |
| Batch pipeline | bauplan run | Functions |
| Dev. pipeline | bauplan run | Functions |
| Inter. query | bauplan query | Functions · The complexity of resource management in a dynamic, multi-language DLH thus reduces to "just scheduling functions": functions have clear isolation boundaries, natural support for infra-as-code, and are easy to reason about for both humans and agents.

What we need is a computational policy, i.e. an algorithm that observes ongoing computation and incoming functions and properly schedules the workloads as closely as possible to user-defined priorities, e.g. a query typically has a human waiting on the other side of the screen, while a daily job may start five minutes later without affecting any downstream system. Importantly, interleaving latency sensitive and latency insensitive workloads for better resource utilization is a common pattern in architectures for heterogeneous, containerized computation (Borg, XFaaS), less so in data systems.
As building and testing such policies on the real, cloud-based, high-performance system is costly and error-prone, we developed a Python simulator to quickly iterate offline: little did we know that a tool built for human researchers would turn out to be well suited for AI ones as well.
Eudoxia, a FaaS Simulator
A key insight of the ADRS agenda is that "system problems naturally admit reliable verifiers": in particular, since simulators allow researchers to evaluate solutions quickly, they make "systems research particularly well-suited for AI-driven exploration". Eudoxia, the Bauplan simulator, is therefore a key piece in our ADRS experiments.
We developed *Eudoxia* (CDMS@VLDB25) **originally in collaboration with Tapan Srivastava from UChicago. Eudoxia will take existing traces or generate random ones parametrically, then simulate function execution with appropriate callbacks for whatever scheduling policy is under test. The high-level architecture is depicted in the following diagram:
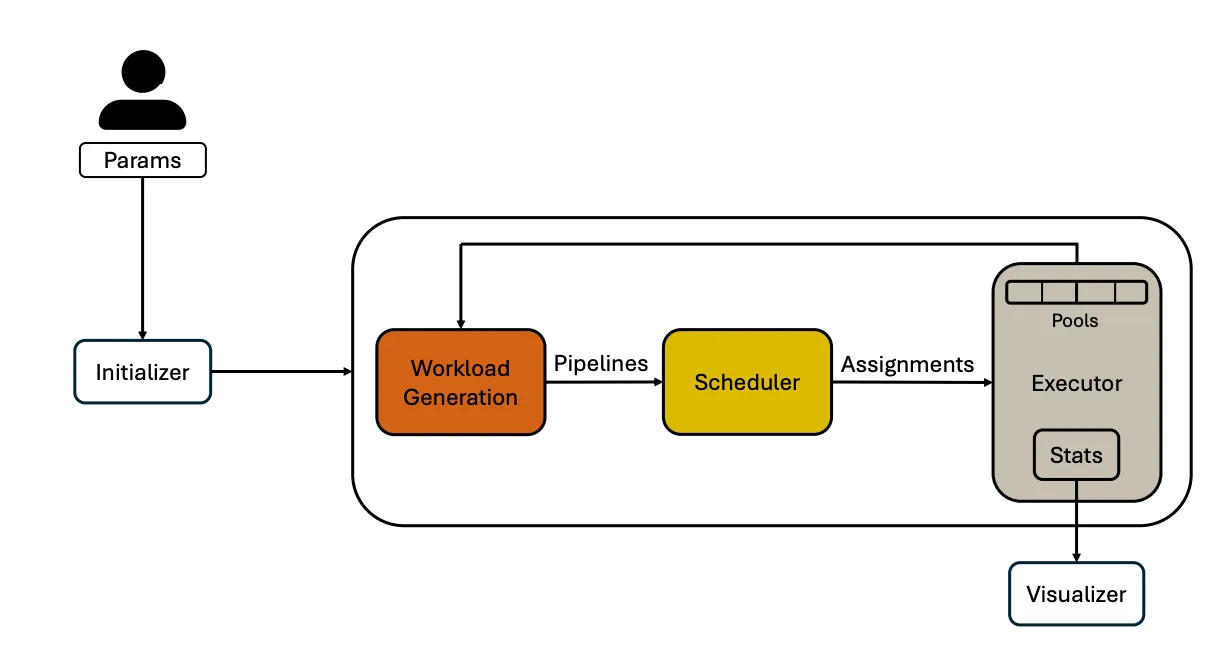
At the end of a trace, Eudoxia will produce latency, throughput, # failed jobs and other interesting stats which can be used to evaluate how well a policy is doing. As an example, a standard FIFO baseline policy can be implemented with a few lines of Python, as shown here.
A policy boils down to just an init and a scheduling function, with a decorator specifying its name: as long as we produce new modules with the same functions and signatures, the rest of Eudoxia will work as is, making comparisons easy and deterministic. Using (Python) code to both reason about and evaluate new policy ideas has obvious advantages: code allows for modular improvements, it is easy to interpret and benchmark, and it is cheap to generate thanks to Large Language Models.
On top of the usual ADRS perks, pulling off cheap policy generation in a multi-tenant system such as Bauplan is particularly important from an industry perspective: while a standard parametric policy uses different parameters for each customer to effectively navigate one design space, open-ended code generation is not constrained in a similar way, so that customers with different workloads are indeed served by policies sampled from a "multiverse" of design spaces.
Putting It All Together
The combination of a complex, multi-dimensional decision problem such as scheduling data workloads, and the availability of a quick, deterministic verifier such as Eudoxia fit perfectly the prerequisites of the AI-Driven Research for Systems agenda: as long as the solution is verifiable, we can ask LLMs to iteratively generate and refine solutions.
Following the ADRS generate → evaluate → refine recipe, we frame scheduler design as a loop: an LLM proposes a policy by generating Python code, the simulator evaluates it on standardized traces, and structured feedback steers subsequent generations (e.g. "policy not valid", "latency is worse than FIFO").
More precisely, our initial study - accepted at Post AI FM @ AAAI 26 - implements the following sampling loop:
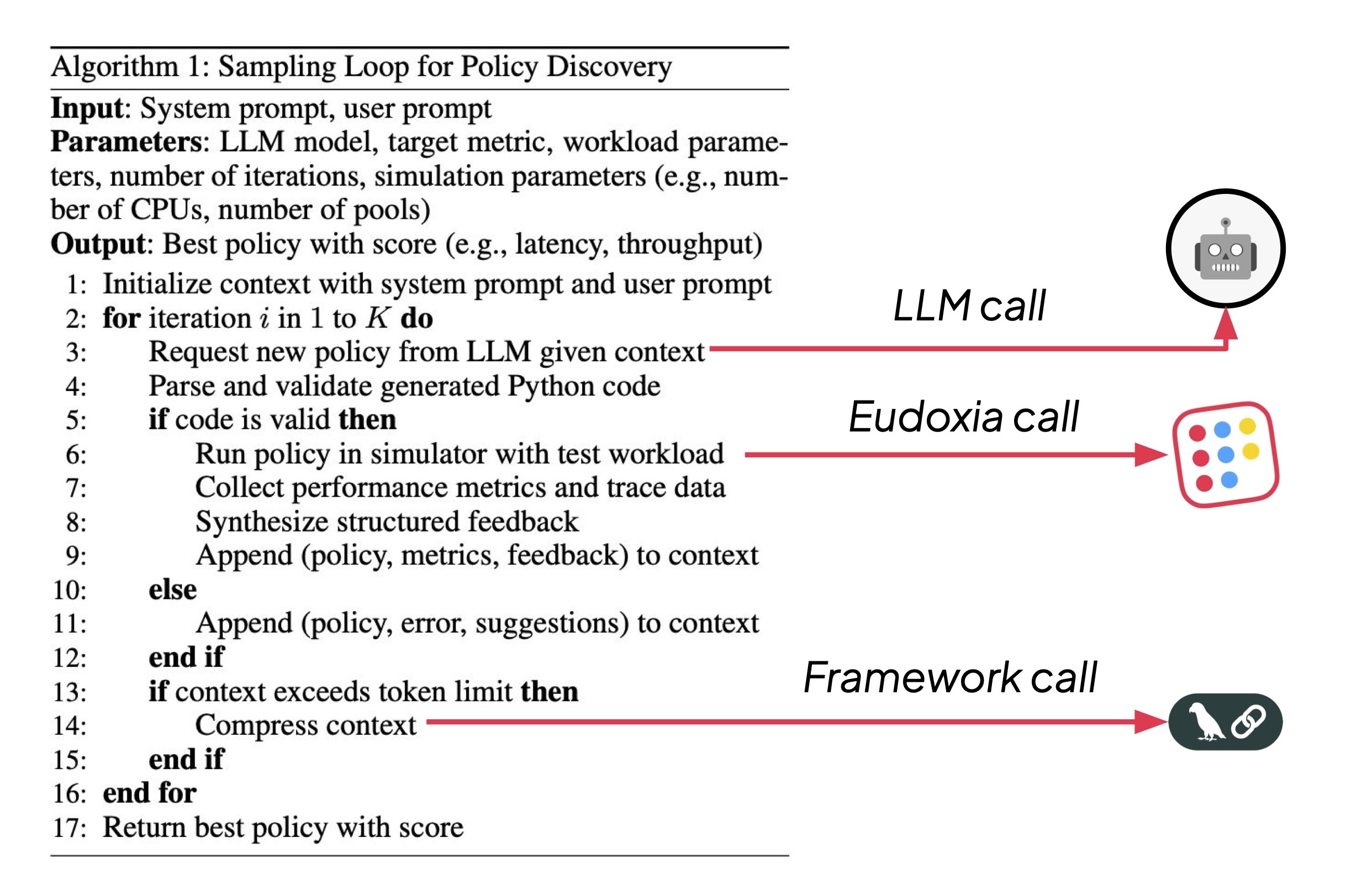
Two results were pretty surprising:
- even with off-the-shelf models (i.e. no SFT or RL), repeated sampling is prima facie an effective strategy to generate policies which are more complex and effective than the (weak) baseline;
- keeping everything else constant (Eudoxia traces, number of iteration, hyperparameters in the simulator, prompts), model performance varies quite a lot and it is very task-sensitive: for example, the initial results in the pre-print are different than what the latest simulations have shown (below). While reminding us of the famous deep learning quote ("We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence"), we acknowledge that doing robust ADRS is difficult in a constantly changing, complex AI environment, and we therefore invite caution in deriving strong interpretations from initial empirical results.
The picture below (on a log scale) shows the full range of improvement from baseline (~13,000) to final values for three LLMs tested with the sampling loop above on thirty iterations. While Opus quickly found a working policy but never improved, GPT got its breakthrough around iteration 7. The most interesting curve though is Sonnet's, which started at baseline, dropped to a good result by iteration 7, then achieved breakthrough at iteration 20.
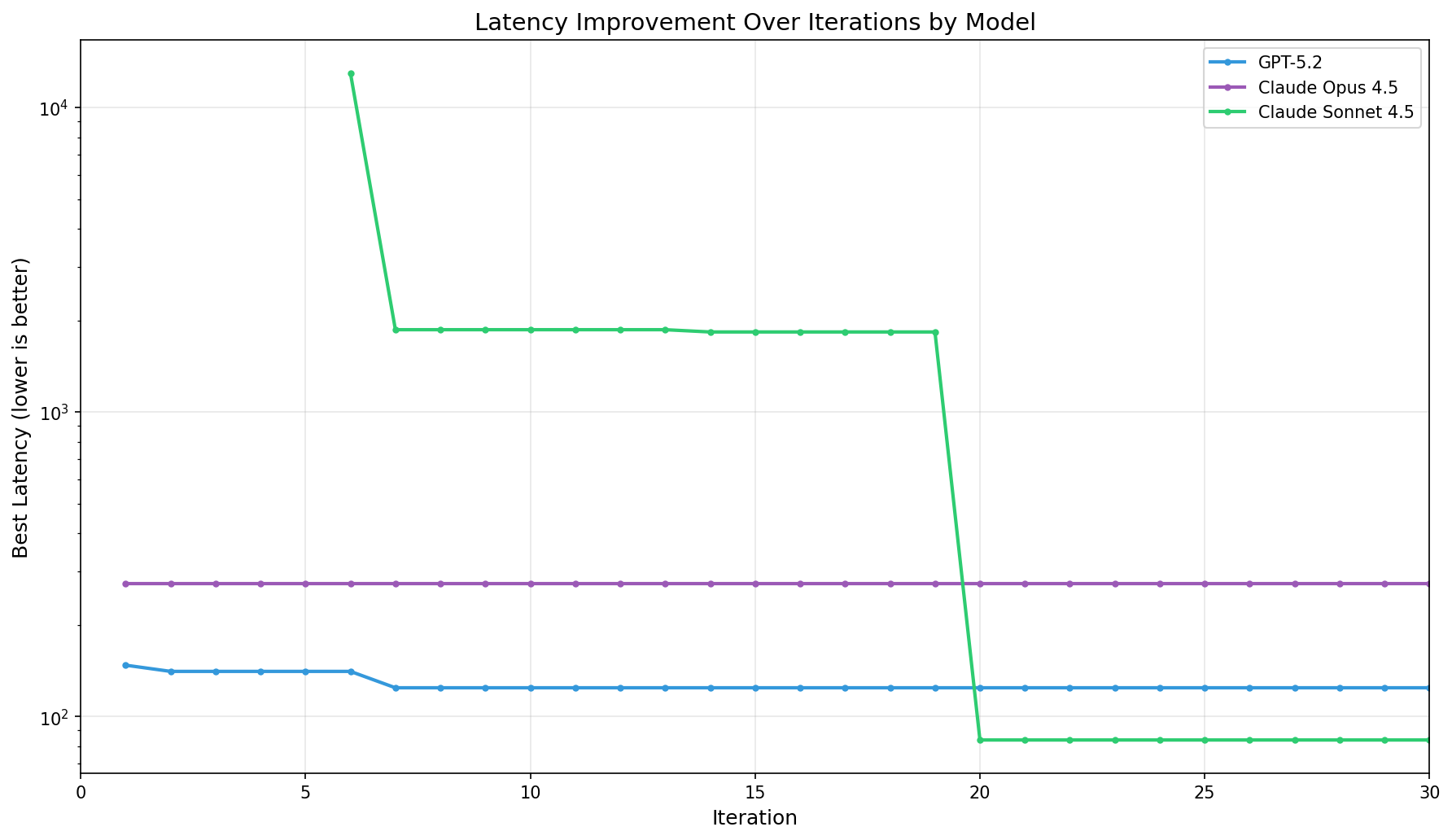
| Model | Baseline Latency | Best Result | Total Time | Total Cost |
|---|---|---|---|---|
| Claude Sonnet 4.5 · 12,999.70 · 83.77 · 32.8 min | $9.10 | |||
| GPT-5.2 · 12,999.70 · 124.34 · 159.6 min | $16.25 | |||
| Claude Opus 4.5 · 12,999.70 · 272.89 · 401.8 min | $11.12 · When checking Sonnet's progression, we find that it spent the first ~20 iterations learning the API (5 failed attempts at generating valid Eudoxia code), then getting basic functionality working and a first "decent" improvement, before quite suddenly discovering a much better strategy. |
Interestingly, policies generated by powerful reasoning models tend to be pretty long (hundreds of Python lines), requiring domain expert examination to be fully understood: it is an open question how to properly steer models to be not just interpretable (as all code is, by definition), but also understandable - i.e. code that uses abstractions and patterns somehow compatible with human cognitive architecture. As someone used to say, "Any fool can know. The point is to understand."
From LLM-in-a-Loop to Fine-Tuning Open-Source Models
We could take the experiment one step further and move from generate>evaluate>refine to generate>evaluate>fine-tune, i.e. we could use our simulator "DeepSeek-style" as a reward generator for reinforcement learning. To test out this hypothesis, we extended our initial experiments setting up Tinker for LoRA-based tuning of an open-source LLM.
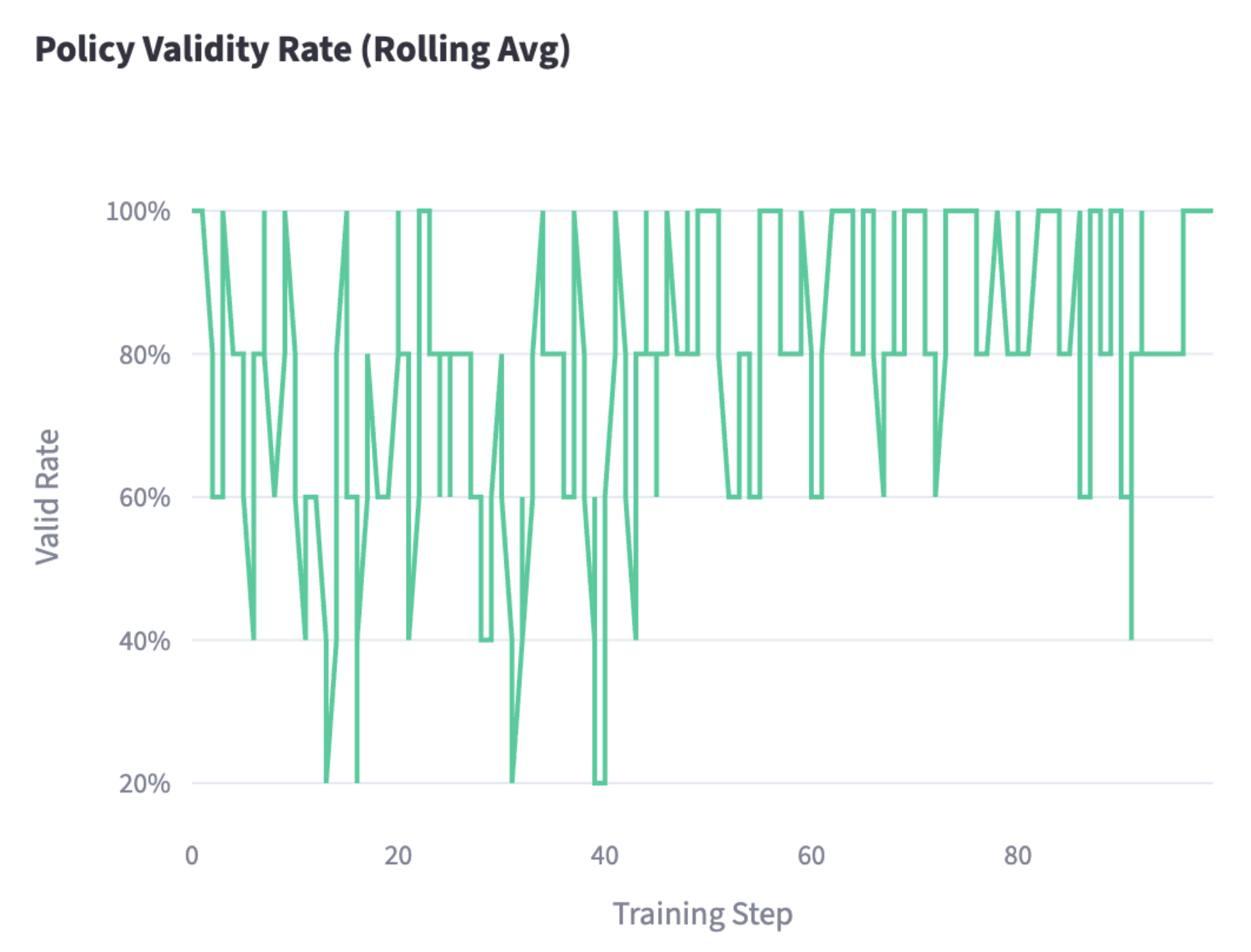
A thorough analysis of an RL setup would need to wait for a future iteration (especially in light of recent literature). However, we can already remark how our building blocks can easily be arranged to show encouraging results. In our latest runs, we defined a new KPI, adjusted latency, which is based on a weighted mean of total job times, to account for the importance of finishing high priority jobs first. To also account for completion rate, we normalize the weighted latency by completion rate. We fine-tune Qwen3-30B-A3B-Instruct-2507, evaluated on ~50 simulated traces submitted to Eudoxia. When compared to the same baseline policy, the following RL-generated code provides a ~29x latency improvement (from ~200s to ~30s). Interestingly, the code is small enough to be easily interpreted; in particular, the model figured out two important strategies to reduce latency:
- Priority-Aware Scheduling: instead of treating all pipelines equally, the policy assigns 10x weight to Query jobs, 5x to Interactive, and 1x to Batch. This helps high-priority jobs complete faster;
- Completion-Rate Boosting: pipelines closer to finishing (higher fraction of operators ready) get scheduled first. This reduces latency by clearing near-complete work before starting new work.
See You, ADRS Cowboys!
When we invested in building our simulator, little did we know that it would become a stepping stone towards semi-automated policy design (as they say, "never bet against code"). The modularity of the main building blocks - prompts, simulator, sampler, LLMs - will allow us to progressively enhance the system, and take advantage of existing efforts to "auto-magically" generate better policies: as of today, our research will benefit automatically from any effort in making Eudoxia better and any LLM improvement from model providers.
It is a bit of a research cliché, but we did indeed just scratch the surface. It is not surprising how many more things can be improved and tuned - such as prompt optimization or graduating to sophisticated code evolution strategies. The surprising part is that a "simple while-loop around an LLM" works out of the box.
As a full-fledged, code-first lakehouse, Bauplan is however more than a custom FaaS. Some generalization comes up naturally (even if the answer is all but trivial: more on that soon!): for example, can AI help us understand user code better and "transpile" it to a more efficient version? Other generalizations are less obvious, as they point to an even more fundamental shift in understanding systems through AI: what if AI could also help remove the burden of building simulations at scale? If it becomes easier and easier to generate the next "Eudoxia for X", a new type of flywheel in system design can happen, one in which some simulator AI provides "experience" to a policy AI in a close optimization loop.
As Alan Turing said, "We can only see a short distance ahead, but we can see plenty there that needs to be done". Let's not forget, it is up to us to get it done.
Acknowledgements
Thanks to Tapan and Tyler for the outstanding work in getting Eudoxia where it is today, and thanks to the ADRS group for hosting us and for precious feedback on previous versions of this blog post.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t and Discord
🗞️ Follow us: x.com/ai4research_ucb