Automating Algorithm Discovery: A Case Study on Sparse Attention Design using SkyLight
This post is part of our AI-Driven Research for Systems (ADRS) case study series, where we use AI to automatically discover better algorithms for real-world systems problems.
In this post, we study sparse attention for accelerating decoding in Large Language Models (LLMs). The goal is to reduce the memory traffic and latency during the decoding phase, which is a fundamental bottleneck in LLM inference.
We explore how AI, specifically a Cursor agent within the SkyLight framework, can evolve towards state-of-the-art solutions like vAttention. Starting from a simple sink + sliding-window attention, the agent iteratively refines the approach, discovering components like top-k selection and positional bias. While the agent made significant progress, human oversight was crucial to correct subtle numerical issues and fully realize vAttention-level quality.
- 🌐 SkyLight website: SkyLight
- Follow SkyLight: x.com/skylight_org
- 🧑🏻💻 SkyLight Code: skylight-org/sparse-attention-hub: Advancing the frontier of efficient AI
- 📄 vAttention paper: [2510.05688] vAttention: Verified Sparse Attention
- ✍️ Previous ADRS Blogs: https://ucbskyadrs.github.io/
- 📝 ADRS Paper: https://arxiv.org/abs/2510.06189
- 👩💻 Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb
The Problem: Designing Sparse Attention for Accelerating Decoding
Modern autoregressive LLM inference proceeds in two distinct phases: prefill and decode. In a typical single turn interaction, the model first processes the entire prompt, which may include long textual instructions or visual inputs, and computes token representations across all transformer layers while materializing the key value cache. This stage, referred to as the prefill phase, is largely compute bound and can be executed efficiently on modern accelerators.
The subsequent decode phase behaves very differently, leading to performance challenges. During decoding, the model generates one token at a time while repeatedly accessing the previously constructed key value cache. Despite operating on far fewer tokens per step, decoding is often significantly slower. This slowdown is fundamental. The decode phase is dominated by memory traffic rather than computation, which limits effective GPU utilization and makes memory bandwidth and latency the primary bottlenecks (Figure 1).
For more information, check out this blog from FlashInfer.

Sparse Attention for Decoding
Sparse attention is a widely explored paradigm for accelerating the decode phase of LLM inference. Instead of attending to all previously generated tokens, sparse attention selects only a subset of tokens to participate in the attention computation. This selection is typically performed independently for each attention head and each transformer layer. By limiting attention to a small set of relevant tokens, sparse attention significantly reduces key value cache accesses and overall memory traffic. As a result, memory pressure is lowered and the latency of each decoding step is reduced.
Research on sparse attention has focused on two essential algorithms (Figure 2): (i) the indexer, or how to select the subset of tokens (which tokens and how many) and (ii) how to compute the sparse attention, the mathematical formula.

Why AI Driven Research (ADRS) Fits Sparse Attention and ML
Like systems research, machine learning research is strongly guided by empirical evaluation. Progress is measured using well-defined benchmarks, datasets, and metrics, which naturally act as reliable evaluators. In most ML settings, the research objective is simply to improve a measurable metric such as perplexity or accuracy on a held out validation set from benchmarks, like ImageNet, GPQA, etc. This emphasis on quantitative objectives and automated evaluation pipelines makes ML research uniquely suited for AI-driven workflows. By enabling rapid experimentation and large-scale exploration with minimal human intervention, these clear evaluators allow learning-based agents to efficiently search for improved solutions.
In sparse attention research, the key metrics of interest, evaluated on a validation dataset, capture the trade-off between efficiency and fidelity.
- Density: measures the fraction of tokens selected for attention computation relative to full attention. Lower density corresponds to reduced memory traffic and compute.
- Approximation error: quantifies the deviation of the sparse attention output from full attention, typically measured as a relative error at the attention module output.
- Downstream quality: quantifies the absolute quality of LLM with sparse attention on validation set.
The core objective is to minimize approximation error (and hence maximize quality) subject to a target density constraint, thereby achieving maximal efficiency without sacrificing model quality.
SOTA Algorithm: vAttention
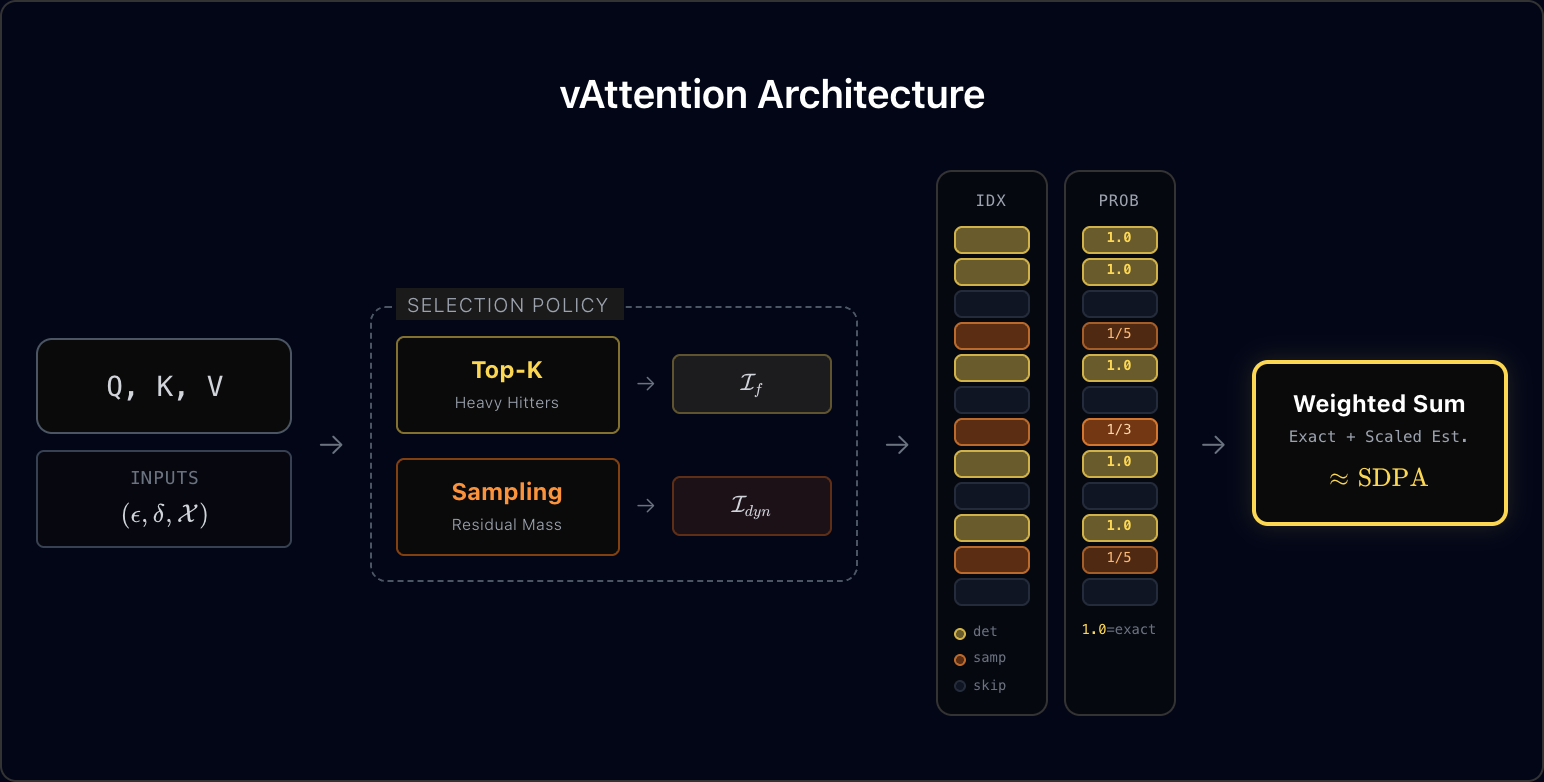
vAttention (Verified Sparse Attention) is the leading sparse attention mechanism on SkyLight's leaderboard, which compares various inference time sparse attention approaches on standardized benchmarks. We briefly introduce the ideas in vAttention below (Figure 3). For more details, please refer to the vAttention blog post.
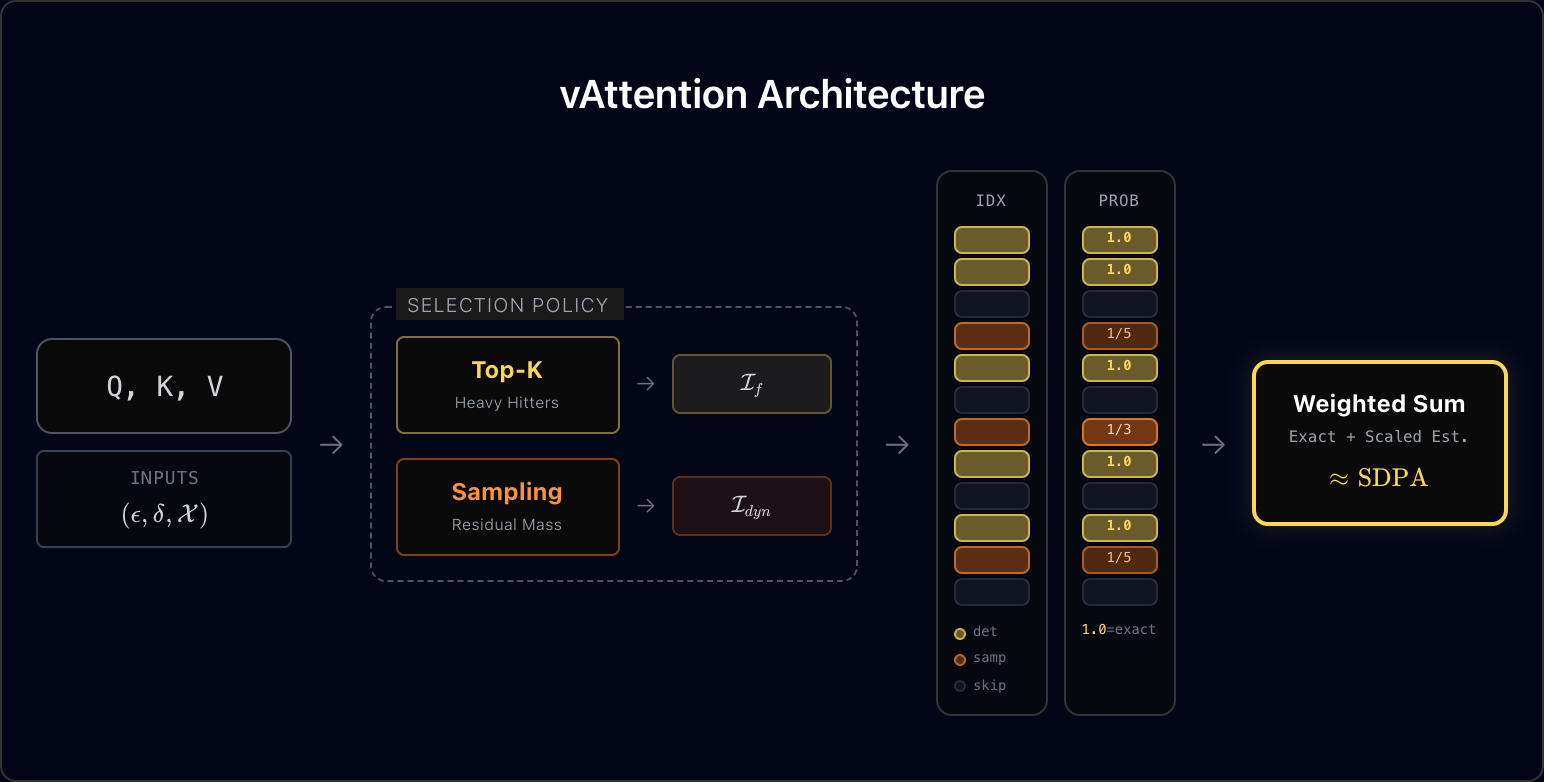
vAttention uses hybrid token selection: deterministic top-k (I_f) and stochastic token selection (I_dyn, i.e. random sample) in order to obtain a subset of tokens. It then uses the stochastic form of attention computation (eq. 3 in paper) to compute the sparse attention.
N = N_f + N_dyn = sum_i(exp(<K[i], q>) * V[i]) + (n_s / |I_dyn|) * sum_j(exp(<K[j], q>) * V[j])
D = D_f + D_dyn = sum_i(exp(<K[i], q>)) + (n_s / |I_dyn|) * sum_j(exp(<K[j], q>))
SDPA = N / D
where I_f, I_dyn are deterministic (top-k) indices and sampled indices respectively; N_f, D_f are partial numerator and denominator computed over I_f and N_dyn and D_dyn are estimated residual sums. n_s is the count of residual tokens.
The core idea behind hybrid selection is based on the following observation: across the spectrum of attention score entropy, top-k selection and random sampling play complementary roles. Relying solely on top-k tokens works well in low-entropy regimes but can incur large errors when attention scores are relatively flat (high entropy). In contrast, random sampling-based estimation performs well in high-entropy regimes but degrades in low-entropy settings. By combining these two strategies, vAttention achieves stable performance across the entire entropy spectrum (Figure 5).

Apart from the hybrid selection strategy, vAttention goes beyond and introduces the verified-X paradigm, which adjusts the sample size to ensure (ϵ, δ) guarantees on the approximation quality.
ADRS Setup with SkyLight
We describe how we apply ADRS to SkyLight, a comprehensive framework that unifies implementation, evaluation, and optimization for a wide collection of sparse attention mechanisms. SkyLight's sparse-attention-hub provides a flexible framework for composing different token selection strategies through the add_mask function of the Masker class (Figure 6). By combining multiple Masker instances, users can construct a sparse attention module that plugs into Hugging Face models as a replacement for full attention. The framework supports popular sparse attention approaches such as HashAttention, PQCache, Quest, Double Sparsity, and Adaptive Sampling (vAttention). It also includes an evolve_masker, which serves as an initial sparse attention implementation for ADRS exploration.

Detailed instructions for running exploration with open-evolve and the Cursor native agent are provided in their respective README files. In our case study, we use a Cursor agent as the ADRS framework because the code we want to evolve is part of a large repository, and Cursor provides built-in tools for efficiently indexing and navigating the repository.
Case Study: Evolving From Scratch to vAttention
In our case study, we present the Cursor agent with a starter code and ask it to optimize the sparsity pattern selection algorithm under a density target of 10% (i.e., selecting 10% of tokens) to minimize the attention approximation error. The evolution of the Cursor agent is shown below in Figure 7 in terms of combined score versus iterations. The combined score is defined as:
- −(approximation error + density penalty), where a density penalty is applied when density exceeds the target, so higher values indicate better performance.

Figure 7. Evolution progress over time with Cursor.
As a starting point in the evolution, we use a simple implementation of sink + sliding-window (local) attention. We prompt the agent to improve the attention approximation error while staying within the density target. The exact Cursor task specification can be found here. Since the Cursor agent has access to the entire repository, we do not provide much additional information. For frameworks such as OpenEvolve, we would instead need to summarize the repository APIs relevant to the task.
In the very first iteration, the agent identifies the need to add top-k selection (we allow oracle top-k selection at this stage, as it remains valid for research purposes even though it is not practically applicable.) This likely reflects the LLM drawing on prior knowledge of sparse attention and established approaches in the literature. In subsequent iterations, the agent explores different allocations among sink, local, and top-k attention. It also experiments with adding a position-based bias that prefers local tokens over distant ones, which improves selection. Performance peaks around iterations 25-30.
The best result, at iteration 28, is obtained by applying top-k score scaling, which ideally should not have affected the top-k selection. This highlights how sensitive these systems are to numerical computation errors and how such effects can be misinterpreted as algorithmic progress.
Progress largely stalls after iteration 28. At this point, we prompt the agent to use sampling and leverage the probabilistic nature of the mask (motivated by our knowledge of vAttention). When prompted, it attempts random sampling in combination with prompting but obtains worse scores. It eventually concludes that iteration 28 remains the best result.
On manual inspection of its hybrid selection attempts, we find that the agent was close to achieving strong results. With a two-line fix--correcting the sampling procedure and setting the appropriate mask values to ensure unbiased estimates of the numerator and denominator--we are able to approach vAttention-level quality (Figure 8). Note that even with this manual fix, the solution remains far from vAttention's verified guarantees. However, for this workload and at a 10% density target, the dynamic selection provided by verified-X is not particularly valuable.
![Figure 8. [Left] cursor generated code for sampling [Right] with manual fixes that matches vAttention performance.](https://hackmd.io/_uploads/H1TjMblLWx.png)
Figure 8. [Left] cursor generated code for sampling [Right] with manual fixes that matches vAttention performance.
Discussion
Overall, the ADRS approach appears promising as a general mechanism for accelerating algorithm discovery and exploration. It is effective at rapidly identifying known building blocks, combining them in nontrivial ways, and making progress through iterative refinement with minimal guidance. At the same time, it struggles with subtle implementation details and numerical effects and can misinterpret incidental artifacts as meaningful improvements. As a result, while promising, it currently benefits from human oversight to address nuanced reasoning, correctness constraints, and the validation of true algorithmic advances.
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t and Discord
🗞️ Follow us: x.com/ai4research_ucb