Autocomp: An ADRS Framework for Optimizing Tensor Accelerator Code

This post is part of the AI-Driven Research for Systems (ADRS) blog series, where we explore how AI can be applied to systems research. This post was contributed by a team of our colleagues at UC Berkeley's SLICE Lab!
In this blog post, we go down the stack and explore how AI is being used to speed up AI--at the kernel level. Specifically, we highlight Autocomp, the first LLM-driven code optimizer for low-resource tensor accelerators. Autocomp helps hardware designers extract the full performance of tensor accelerators, outperforming human expert kernel writers by up to 17x on AWS Trainium while being highly portable and easy to use. Read below and see the Autocomp 📝 paper and 👩💻 GitHub repo for full technical details!
More from ADRS:
- ✍️ Previous Blogs: https://ucbskyadrs.github.io/
- 📝 ADRS Paper: https://arxiv.org/abs/2510.06189
- 👩💻 ADRS Code: github.com/UCB-ADRS/ADRS
- 💬 Join us: join.slack.com/t and Discord
- Follow us: x.com/ai4research_ucb
The Problem: Accelerators are Hard to Program
NVIDIA (briefly) became a $5 trillion company by accelerating AI. Tensor accelerator offerings from Amazon, Apple, Cerebras, Google, Groq, Meta, Qualcomm, and many other companies promise to do even better -- but why aren't these accelerators dominating the market?
One key reason is software. In practice, accelerators don't dominate because their software stacks are immature. Each accelerator requires custom kernels, compilers, and runtime code tuned to its unique programming model, and writing this software is slow and error-prone. GPUs succeed largely because of their deep, battle-tested software ecosystem, not just their hardware. This raises the question: can ADRS help close this software gap? To answer this question, let's go in more depth on what a tensor accelerator is and why exactly writing software for one is challenging.
What is a Tensor Accelerator?
Tensor accelerators are specialized hardware architectures optimized to run AI models. Due to AI models' regular tensor-based computations and low precision requirements, tensor accelerators can allocate larger percentages of chip area (compared to CPUs/GPUs) towards specialized structures like systolic arrays. This can lead to orders-of-magnitude improvements in performance and energy efficiency for AI workloads such as LLMs. However, despite being simpler than CPUs or GPUs, accelerators still vary widely in size, dataflow, and programming model. They can range from tiny devices like the Raspberry Pi AI HAT to wafer-scale systems like Cerebras's CS-3. Furthermore, simpler accelerator hardware architectures can often mean that more aspects of performance optimization must be handled by software, making said software more complex. Fig. 1, based on Gemmini's architecture, shows how a representative tensor accelerator's hardware might be organized.
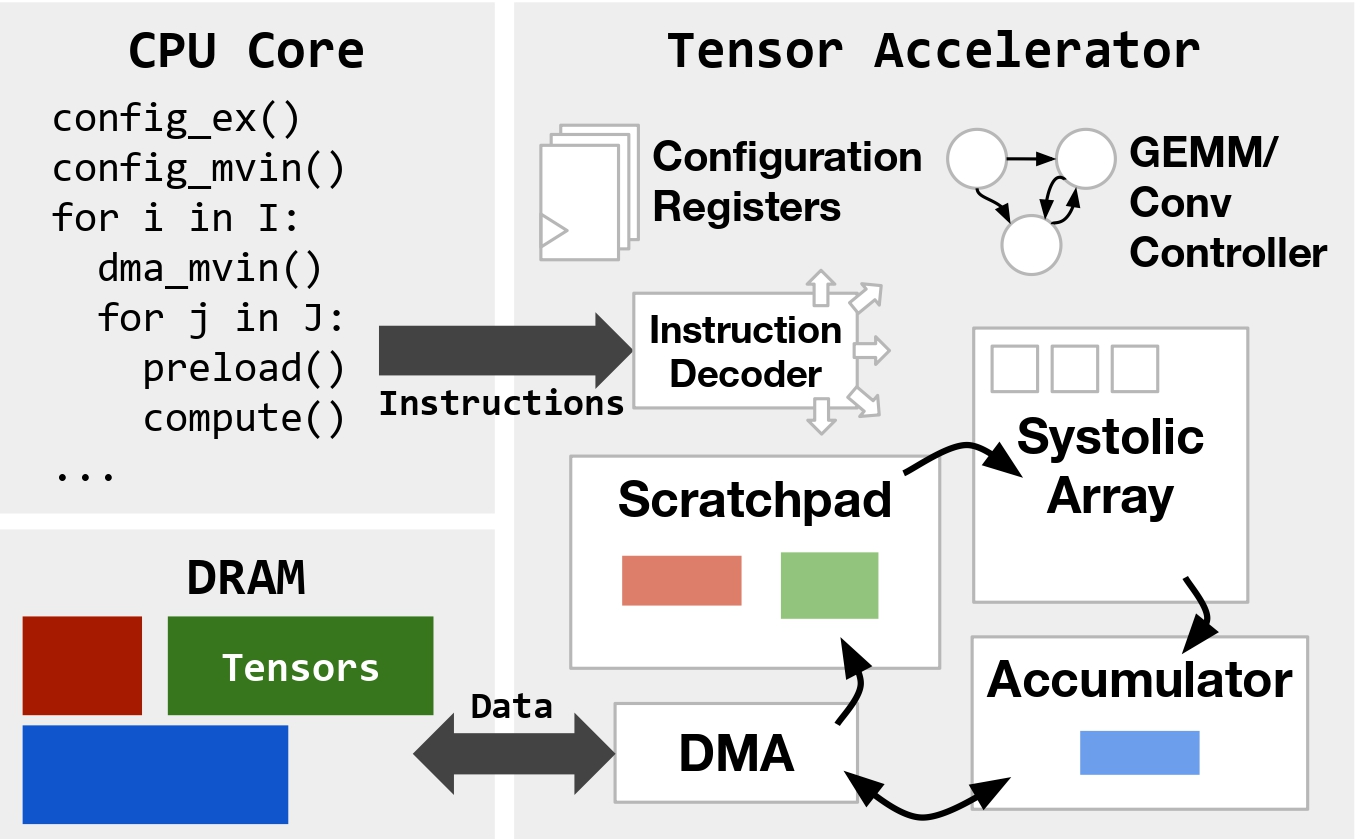
How is Accelerator Code Written Today?
So, how are accelerators like Gemmini programmed? If you've built a machine learning model, you've likely written hardware-agnostic code in libraries like PyTorch or JAX. On NVIDIA GPUs, this code is compiled to CUDA, PTX, and SASS--but other accelerators are less straightforward. Compilers like XLA, TVM, and Triton support a few hardware backends, but none are universal. Building a new accelerator almost always requires developing a custom software stack, which is challenging.
Adapting compilers to new hardware platforms has always been difficult, due to things like vendor- and implementation-specific ISAs (instruction set architectures). As a result, new accelerators often need hand-optimized kernels for key operations like matrix multiplication or convolution. And even once a compiler exists, generating performant code requires good scheduling, i.e., deciding which optimizations to apply and in what order--a process refined over years for CPUs and GPUs, but lacking for new accelerators.
As researchers at UC Berkeley's SLICE Lab, we've also explored using LLMs to write low-level software for low-resource tensor accelerators for a while. Our prior work shows that LLMs perform poorly in zero-shot scenarios, which is unsurprising given each accelerator's unique interface and the scarcity of available training data for these specific platforms.

Tensor Accelerator Programming
So, what do these difficult-to-write programs actually look like? To begin with, programming tensor accelerators differs greatly from programming general-purpose CPUs. Tensor accelerators focus on efficiently executing fixed-size (e.g., 16×16) matrix multiplications. Rather than trying to reduce the number or type of these instructions, software optimization emphasizes:
- Minimizing explicitly managed data movement between main memory and smaller accelerator-local memories (in Fig. 1, the scratchpad and accumulator).
- Setting global configuration state at runtime for varying types of tensor computation and data movement.
- Scheduling or reordering operations to maximally overlap computation and data movement.
Code transformations that enable these optimizations range from low-level arithmetic simplifications and instruction selection to higher-level changes like loop tiling, hoisting, or software pipelining.
Fig. 3 shows an example of software pipelining in a pseudocode tensor accelerator DSL. While bearing resemblance to the classical CPU version of software pipelining, explicitly managed data movement in tensor accelerators means that in addition to reordering instructions, scratchpad addresses must also be carefully managed to achieve functional correctness. Furthermore, hardware performance characteristics must also be carefully considered to evaluate whether such a change is even worthwhile.
// Unoptimized
for (int k = 0; k < 8; k++) {
for (int i = 0; i < 32; i++) {
dma_mvin(A[i*16][k*64], spad_addr);
for (int k_i = 0; k_i < 4; k_i++) {
compute(spad_addr + k_i * 16, ...);
// Optimized
for (int k = 0; k < 8; k++) {
spad_addr = base_spad_addr;
dma_mvin(A[0][k*64], spad_addr);
for (int i = 0; i < 32; i++) {
dma_mvin(A[(i+1)*16][k*64], spad_addr + 64);
for (int k_i = 0; k_i < 4; k_i++) {
compute(spad_addr + k_i * 16, ...);
spad_addr += 64;
The Autocomp Approach
To address these challenges, we present Autocomp, an ADRS framework that uses an iterative LLM-guided search approach to optimize accelerator code. Unlike previous compilers, Autocomp can adapt to new hardware platforms and ISAs by simply changing prompts. Unlike existing tensor DSLs, Autocomp automatically generates optimized code without manual tuning. And unlike data-driven approaches targeting CPUs and GPUs, Autocomp requires no model training, instead leveraging LLM in-context reasoning and pretrained knowledge of common optimizations.
How does it actually work? Autocomp leverages domain knowledge, hardware feedback, and a prompting technique we call dropout to optimize tensor accelerator code via an automated LLM-driven search. Each iteration in this search consists of two structured phases, first planning an optimization in natural language, then implementing that optimization. Autocomp repeats this Plan-then-Implement process on generated code, completing the optimization loop with an iterative beam search. The result is an automated system that discovers optimizations even experts miss!
Plan-then-Implement: Two-Phase Optimization
Prior work across general-purpose LLM prompt design and LLM code generation shows that decomposing tasks into multiple steps can improve an LLM's ability to solve them. As a result, we split our workflow into two phases (shown in Fig. 4): optimization plan generation and code implementation.
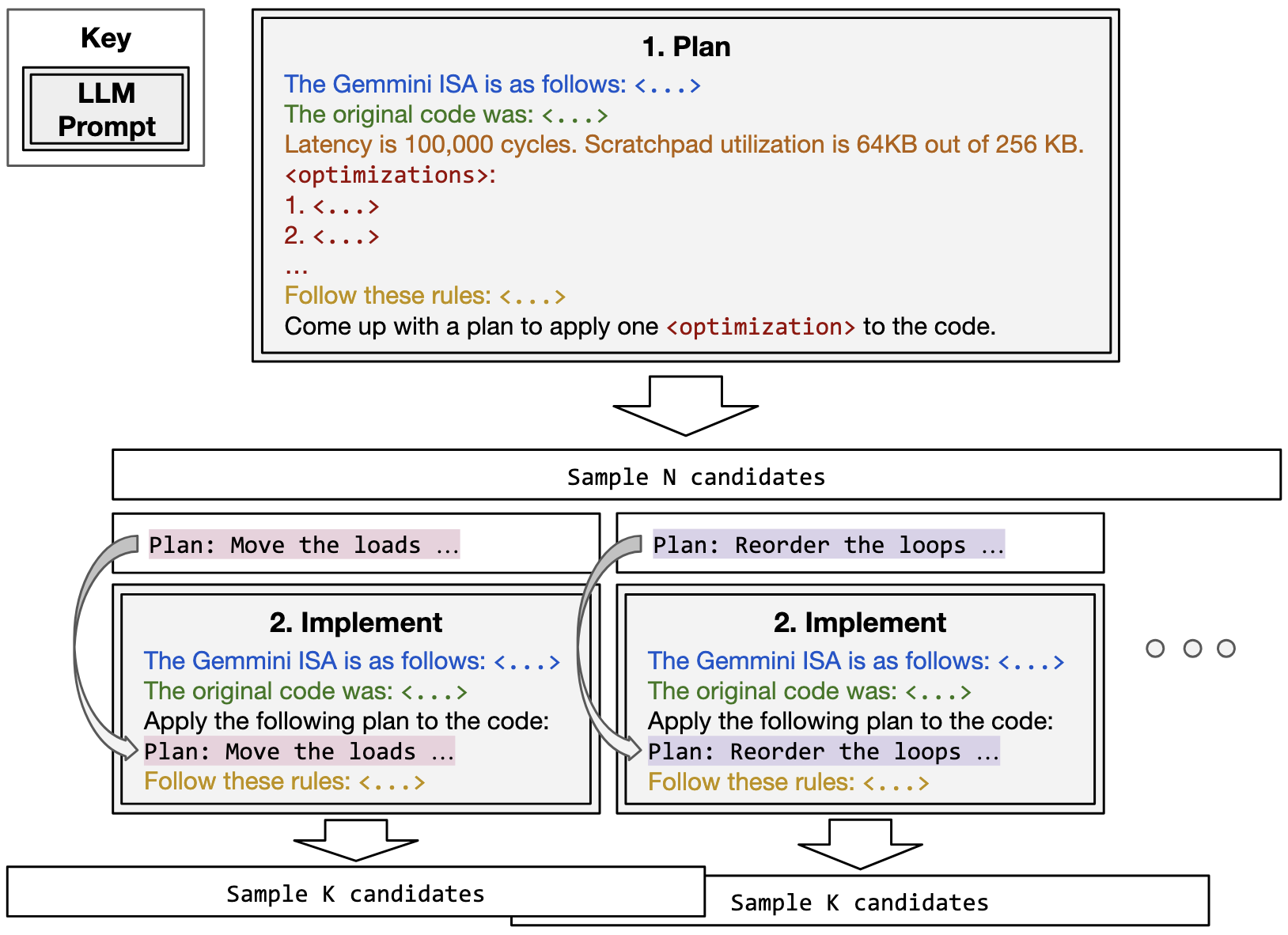
Phase 1: Plan
We prompt an LLM to select one optimization from a predefined menu of optimization options and to describe the concrete transformations required to apply it. Since we're working with a low-resource DSL, we make sure to include all necessary information in context. The planning prompt includes the following components: Accelerator ISA, Current Code, Hardware Performance Feedback, Optimization Menu, Instruction, and Rules (see the paper for full details). For each current code candidate, we sample N different plans, since there are many possible ways to schedule a tensor accelerator workload!
Phase 2: Implement
Following phase 1, we have a plan that outlines the specific transformation for the selected optimization. To generate optimized code, in phase 2 we prompt the LLM to apply the transformations in the plan to generate new, semantically equivalent code. The implementation prompt (phase 2) contains many of the same elements as the planning prompt (phase 1). We sample K independent code candidates for each plan to improve the likelihood of implementing the plan correctly.
Autocomp relies on models with good coding capabilities and long context lengths as prompts can hit tens of thousands of tokens when all required context is included. Using frontier LLMs such as o4-mini and gpt-5, we have successfully optimized workloads with more than 300 lines of code, at the cost of just a few hours and tens of dollars. As the capabilities of LLMs (both small and large) continue to improve, we anticipate that Autocomp will only become cheaper and faster to run over time.
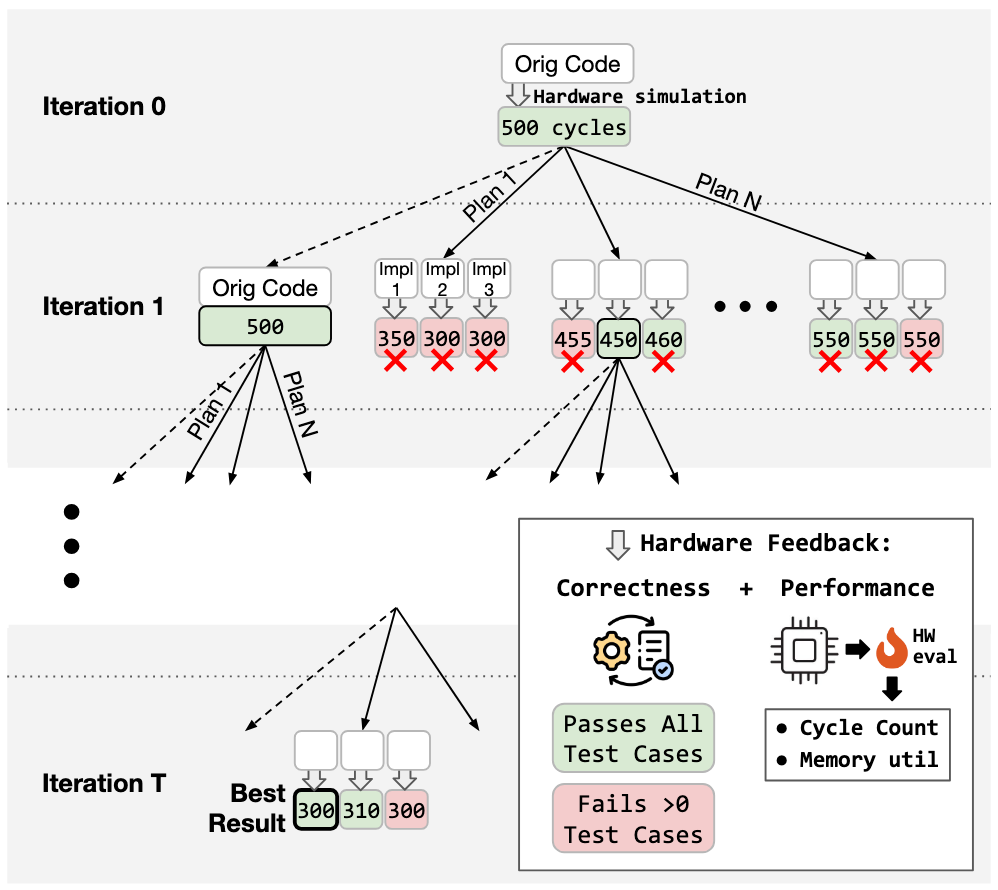
Survival of the Fastest (and Correct): Beam Search
To efficiently explore several optimizations in parallel, we use a traditional beam search, with beam width B. Fig. 5 above shows how beam search would work for a beam size B=2. Our beam search integrates the two phases described above, but only candidates which meet the following criteria can enter the beam:
- ✅ Correctness. After each code generation step, every candidate is compiled and run against our functional test suite.
- ⚡ Performance. Next, we measure the latency of functionally correct candidates via cycle-accurate simulation. Only candidates that are faster than their "parent" i.e., the version they were derived from are retained.
Of the functionally correct candidates, we keep the best (lowest latency) B to seed the next iteration of beam search. We run this loop for a fixed budget of iterations.
Hardware Performance Feedback
In addition to functional correctness and cycle count, we utilize more detailed hardware performance feedback to guide the search. Specifically, we measure the utilization of the accelerator's local memories (scratchpad and accumulator) and provide it in the Hardware Performance Feedback section of the planning prompt. Local memory utilization is a generally applicable yet important metric that can help the model select optimizations that increase memory utilization (such as double-buffering or increasing tile sizes) when memory is underutilized and avoid these optimizations when memory is full.
❗ Increasing Plan and Code Diversity
We use the following two techniques to boost the diversity in plan (and in the case of LLM ensembling, code) generation and prevent the model from repeatedly selecting the same optimizations:
- Optimization Menu Dropout. Inspired by methods for preventing neural networks from overfitting, we implement dropout in our optimization menu. Each time a plan candidate is generated, each menu option in the list of optimizations has a chance to be dropped (we use values ranging from 70-80% in the paper). When we initially provided the same menu of optimizations to the model every time, we found that the choices tended to be biased towards specific menu options--dropout fixed this.
- LLM Ensembling. Ensembling LLMs is known to improve diversity and quality of results. To further increase the diversity of generated plans and code, in each case where multiple candidates are sampled, we divide these requests between different LLMs. In the experiments below, we ensemble o4-mini and gpt-5.
🤔 Why not OpenEvolve?
First, OpenEvolve did not exist when we started this project. However, we still find that Autocomp consistently outperforms OpenEvolve on our benchmarks, even when we provide the same amount of context in our prompts. Although we have not carried out extensive testing across the two tools, we believe the following factors play a role:
- Two-Phase Prompting. As shown in studies like PlanSearch, planning in natural language significantly improves LLM code generation performance. We find this to be especially true when trying to creatively generate complex optimizations for low-resource code. By default, OpenEvolve does not implement separate rounds of prompting (i.e., both planning and code generation are done in the same iteration).
- Optimization Menu Dropout. This systematic prompt mutation technique encourages diverse LLM responses and exploration of the scheduling space. In our ablation studies, we find that this technique provides an 18% performance boost on average--a boost which can mean the difference between outperforming or falling behind human expert-written code.
- Greedier Search. While beam search is known to be a greedier algorithm than evolutionary search, this can be beneficial when the problem space is huge and evaluating one sample is costly (hardware simulation can be slow and hard to parallelize).
Applying Autocomp to AWS Trainium
One key strength of Autocomp that we haven't touched on so far is its portability. With just a small team of grad students, we've been able to apply Autocomp to an academic accelerator (Gemmini), an industry accelerator (AWS Trainium), a RISC-V V Extension-compliant dev board (Canaan K230), and even a GPU (NVIDIA L40S). In this blog post, we'll focus on our Trainium results--you can find the rest in our paper or at Charles's blog.

Fig. 6: From Trainium 1 announcement (The Next Platform).
Trainium Overview
Trainium is a family of state-of-the-art tensor accelerators built and deployed by Amazon Web Services (AWS). We optimize code for Trainium 1 (specifically, a trn1.2xlarge instance). This instance contains two NeuronCore-v2, each of which contains scalar, vector, and tensor (systolic array) engines, as well as on-chip scratchpad and accumulator memories (called SBUF and PSUM), which communicate with main memory, and supports a wide range of data types. You can read more about Trainium's architecture in the AWS documentation.
Trainium's software stack includes several different entry points for users, including high-level frontends like PyTorch and JAX. If you use PyTorch, Trainium's NeuronX compiler, based on the XLA compiler, can automatically optimize a PyTorch module by tracing it and taking advantage of fixed shapes and fixed control flows to produce a fused computation graph. However, this prevents the user from implementing low-level optimizations.
Setup
With Autocomp, we optimize code written in the Neuron Kernel Interface (NKI), which enables lower-level control of computation and data movement. While Trainium accelerators are a real-world, high-performance industry backend, they are very low-resource, as Trainium was first deployed in 2022 with NKI only being released in 2024. This makes Trainium a challenging target for LLM-based code generation and an ideal target for Autocomp.
For each benchmark, we manually specify relevant instructions, and include a description and examples (sourced from Trainium's documentation) for only those instructions in the Accelerator ISA section of the prompt. Furthermore, as Trainium's compiler provides decent error messages for syntax errors, when a code implementation fails correctness checking, we prompt the LLM with the Accelerator ISA, the code, and the compiler-generated error message, and then evaluate the fixed code again.
Target Benchmarks
For evaluation, Trainium provides the nki-samples repository, which contains naive, unoptimized NKI implementations, along with optimized implementations, of several tensor kernels in the directory src/nki_samples/tutorial (note that RMSNorm and SDAttention only have optimized implementations). We call these Tutorial benchmarks, and when available, we start Autocomp optimization from naive code and compare its performance to that of the hand-optimized code.
In addition, nki-samples provides a set of advanced implementations that "showcase cutting-edge optimizations and specialized implementations" of key kernels in the directory contributed/neuron-team-kernels. These are optimized implementations written by kernel engineers at AWS. We call these Advanced benchmarks, and we start Autocomp optimization from the optimized code.
Reference code is directly copied from the nki-samples repository, with some implementations requiring small modifications to run on a trn1.2xlarge instance. For more information about the specific configurations used, see our Trainium-specific blog post.
Now, let's dive into the results!
Results
Many of the optimizations in our Optimization Menu for Trainium are based on the Tutorial workloads, so we expect Autocomp to at least match the performance of the fully optimized code. Autocomp not only does so, but outperforms hand-optimized code by a geometric mean of 1.36x (Fig. 7). In doing so, Autocomp speeds up the starting code used as input (either unoptimized or optimized NKI code) by a geometric mean of 2.51x and outperforms Trainium's PyTorch compiler by 13.52x.
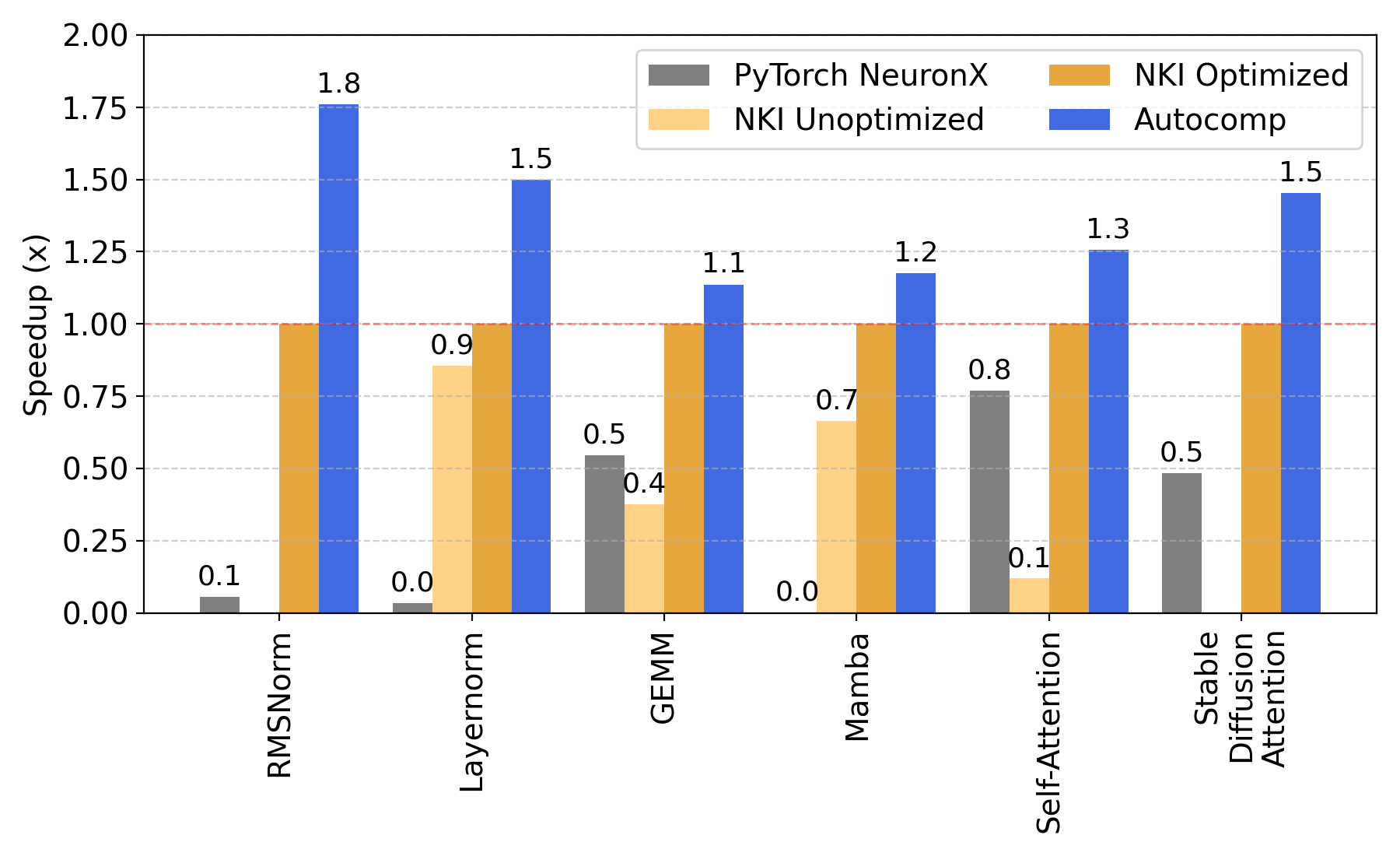
Advanced workloads are already highly optimized, so our initial expectation was that any improvement would be a highly positive result. As shown in Fig. 8, Autocomp managed to optimize these workloads by a geometric mean of 1.9x, far surpassing our expectations. 1D depthwise convolution was optimized by a whopping 17.37x!
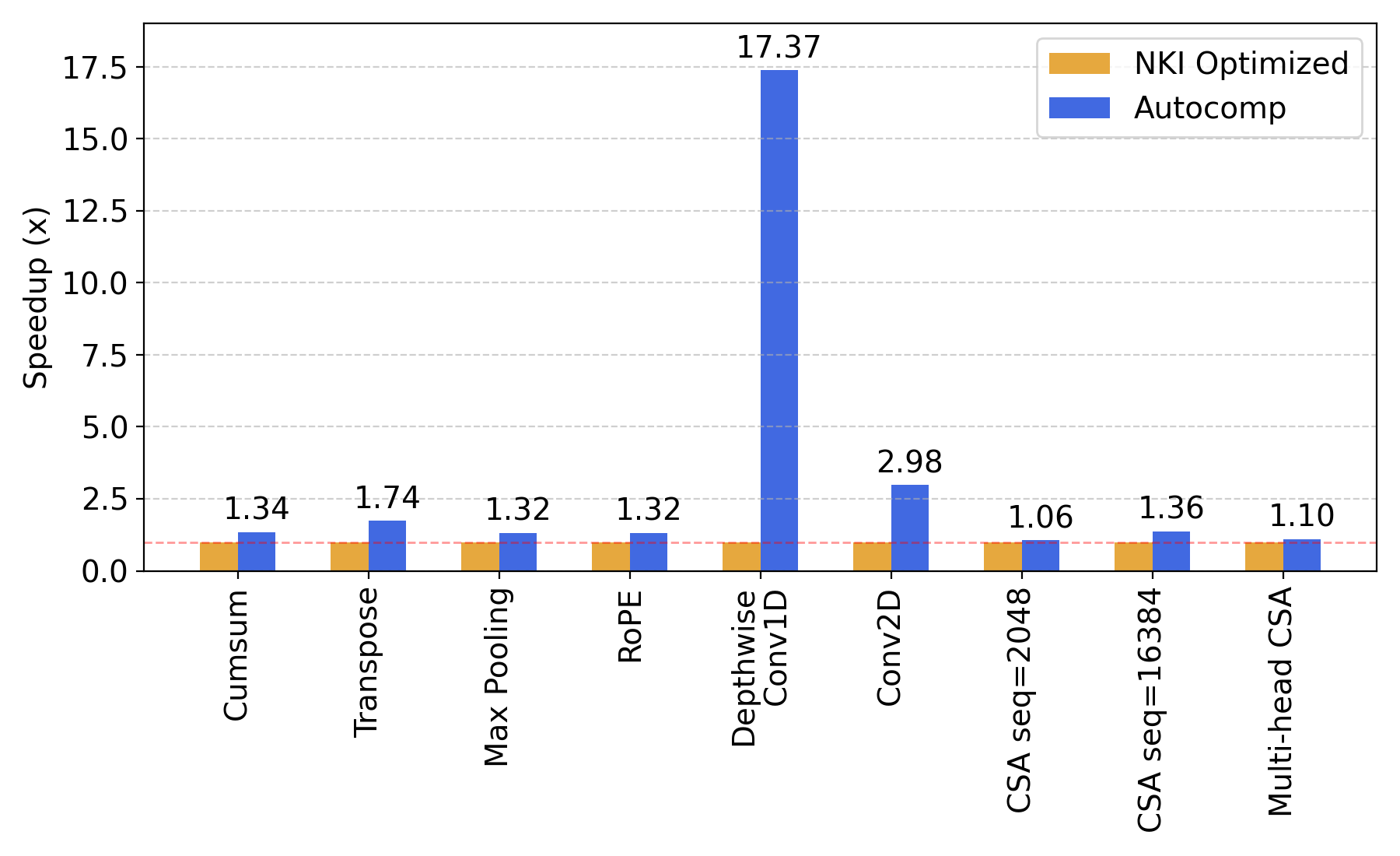
1D Depthwise Convolution: A Case Study
Thanks to Autocomp's plan-then-implement prompting strategy, we can see exactly what reasoning was used at each stage of optimization. We have released a detailed case study of the 1D depthwise convolution in our blog series.
In summary, Autocomp is able to achieve this impressive speedup through a sequence of optimizations that takes advantage of both the specific target shape as well as the code's inherent inefficiencies. Fig. 9 shows the effect of each of these optimizations on latency.
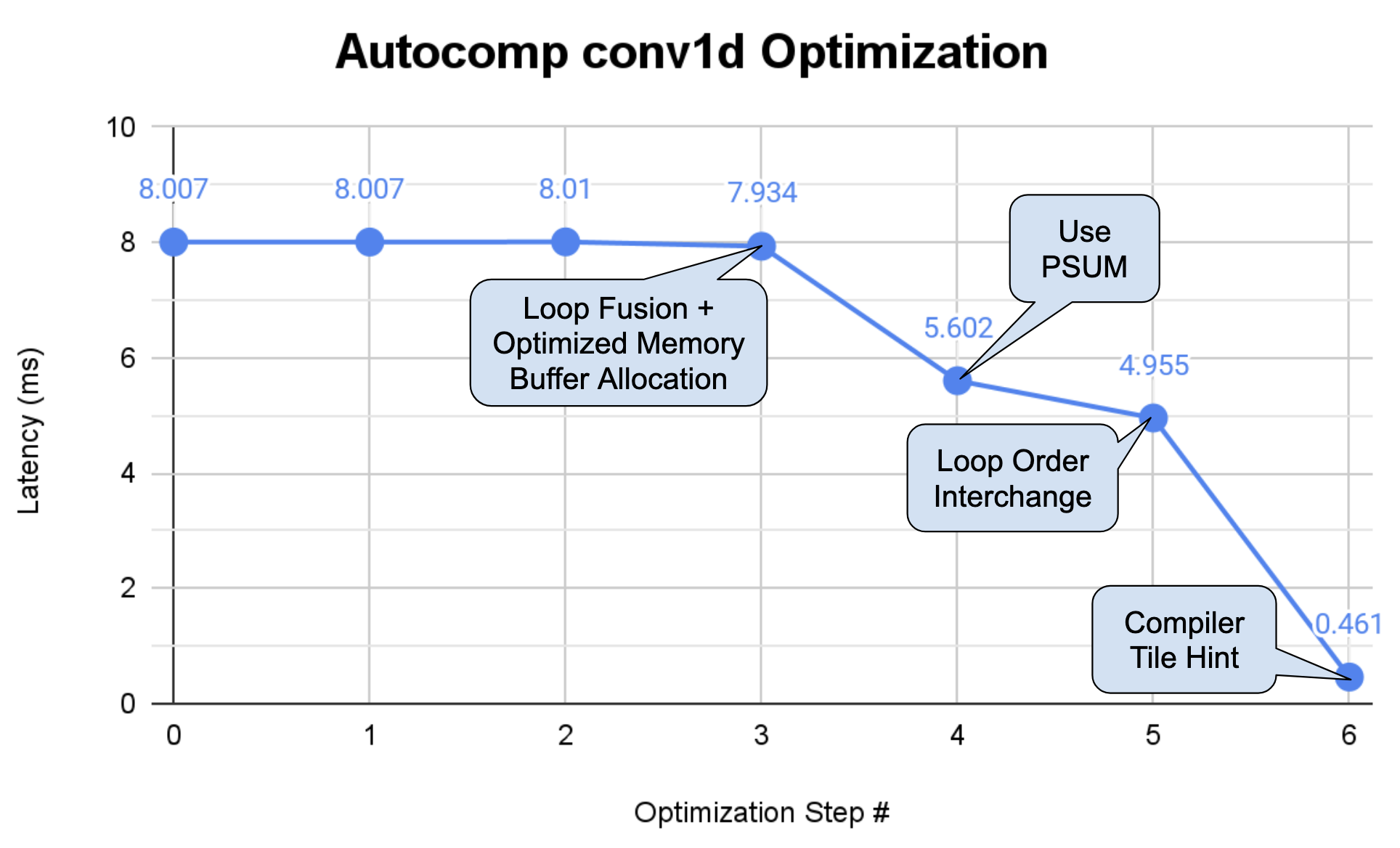
First, it fuses all the loops in the kernel and decreases allocated tile sizes in the scratchpad to prevent spilling to main memory, which allows the next iteration to move the new smaller tile-sized accumulations into the accumulator. Then, it swaps loop ordering to increase filter reuse over batches. Finally (and most critically), Autocomp adds a new fixed-size loop inside the main convolution loop, enabling Trainium's VectorEngine to more widely vectorize the element-wise and reduction operations inside this loop.
Key Takeaways
We believe Autocomp provides new insight into potential use cases of AI in systems research. Not only can AI be used to optimize code to superhuman levels, it can also provide attributes like portability, in this case enabling our code optimization workflow to easily transfer across diverse tensor accelerator backends, even ones with which we were initially unfamiliar.
In addition, while many associate large neural network models like LLMs with poor interpretability and opaque decision-making, we find that with Autocomp, AI-driven systems techniques can in fact increase interpretability when properly structured. By decomposing optimization into human-readable "plans," Autocomp surfaces the model's reasoning directly: why an optimization was chosen, what transformation is being applied, and how it fits into a larger schedule. These natural-language plans form an explicit, interpretable optimization trace--something previous auto-schedulers and learned cost models largely lack, and which can be used for case studies (like with conv1d above) or even to more efficiently optimize future workloads (see the "Schedule Reuse" experiments in our paper).
We hope that future work can continue to expand upon these perspectives to identify new and fruitful systems research directions. Contact Charles (charleshong@berkeley.edu) if you have any questions!
📜 Citation
@misc{hong2025autocomp,
title={Autocomp: A Powerful and Portable Code Optimizer for Tensor Accelerators},
author={Charles Hong and Sahil Bhatia and Alvin Cheung and Yakun Sophia Shao},
year={2025},
eprint={2505.18574},
archivePrefix={arXiv},
primaryClass={cs.PL},
url={[arxiv.org/abs/2505.18574}](https://arxiv.org/abs/2505.18574}),
}
Contribute to the ADRS Blog Series!
The AI-Driven Research Systems (ADRS) initiative is an open, collaborative effort to explore how AI can accelerate scientific discovery itself, from evolving algorithms to optimizing real-world systems.
If you've built, optimized, or experimented with AI-driven research tools, we'd love to hear from you. Share your experiences, insights, or case studies with us in the ADRS Blog Series.
👉 Reach out to us via email: ucbskyadrs@gmail.com
💬 Join us: join.slack.com/t and Discord